Квантовые технологии
Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
Автор: Денис Аветисян
Новый подход объединяет расчеты квантовой механики и методы машинного обучения для создания более чувствительных и точных сенсоров, способных определять биомаркеры запаха тела.
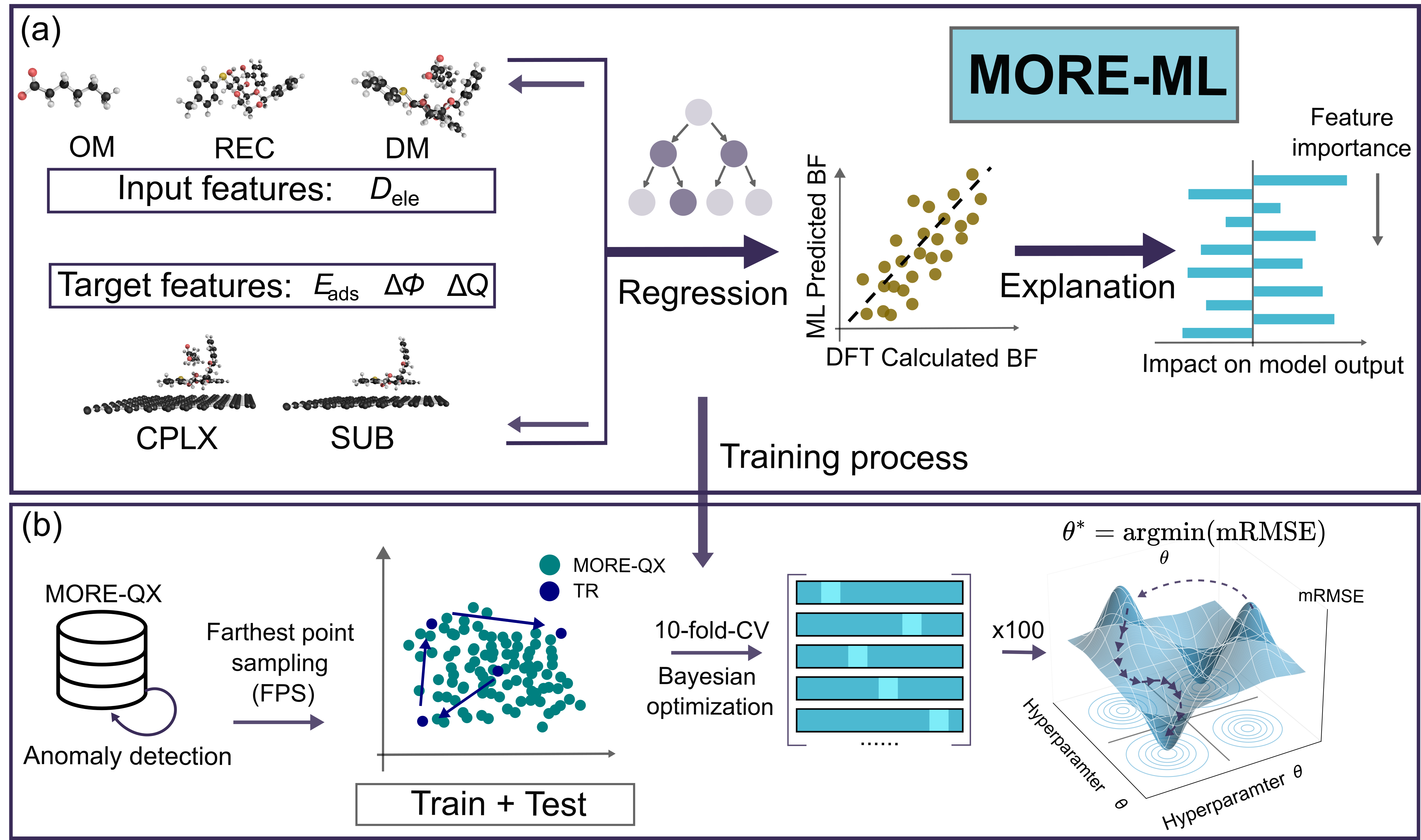
В статье представлена платформа MORE-ML, объединяющая квантово-механические данные и машинное обучение для прогнозирования и интерпретации свойств молекулярных строительных блоков искусственного обоняния.
Разработка устойчивых и высокочувствительных электронных носов для анализа сложных запахов, в частности, компонентов телесного запаха, остается сложной задачей. В данной работе, посвященной ‘Interpretable Machine Learning for Quantum-Informed Property Predictions in Artificial Sensing Materials’, представлен вычислительный фреймворк MORE-ML, объединяющий квантово-механическое моделирование и машинное обучение для предсказания ключевых свойств молекулярных рецепторов. Построенные модели, основанные на расширенном наборе данных MORE-QX, демонстрируют высокую точность предсказания связывающих характеристик и позволяют выявить определяющие квантово-механические свойства молекул-сенсоров. Может ли такой подход стать основой для создания принципиально новых искусственных ольфакторных систем, способных эффективно анализировать сложные запаховые смеси и расширить возможности диагностики и мониторинга состояния здоровья?
Запах как язык: Раскрывая невидимую коммуникацию
Человеческий запах тела — это не просто неприятный аромат, а сложная смесь летучих органических соединений, известная как BOV (Body Odor Volatilome). Эта химическая «подпись» играет ключевую роль в социальной коммуникации, позволяя людям воспринимать эмоциональное состояние и даже генетическую совместимость друг друга. Более того, состав BOV тесно связан со здоровьем организма: изменения в концентрации определенных соединений могут служить ранними индикаторами различных заболеваний, от инфекций до онкологических процессов. Изучение BOV открывает новые возможности для диагностики, позволяя выявлять болезни на ранних стадиях, до проявления клинических симптомов, и оценивать эффективность лечения на основе химического состава выделяемого запаха.
Традиционные методы определения запаха тела, такие как органолептическая оценка, зачастую страдают от высокой субъективности восприятия и недостаточной чувствительности для выявления отдельных компонентов сложного состава запаха — так называемого BOV (Body Odor Volatilome). Восприятие запаха варьируется в зависимости от индивидуальных особенностей обоняния, предыдущего опыта и даже психологического состояния оценивающего, что делает количественную оценку и сравнительный анализ затруднительными. Кроме того, существующие методы, как правило, не способны выделить и идентифицировать отдельные летучие органические соединения, составляющие BOV, особенно в крайне низких концентрациях, что существенно ограничивает возможности диагностики заболеваний или выявления индивидуальных особенностей метаболизма по запаху.
Разработка «электронного носа», способного точно анализировать состав человеческого запаха, требует глубокого понимания взаимодействия молекул, формирующих этот запах, с материалами сенсоров. Идентифицировать отдельные компоненты сложного букета запаха — задача, требующая от сенсорных материалов высокой чувствительности и селективности к различным летучим органическим соединениям. Исследования направлены на создание материалов, способных эффективно связывать определенные молекулы запаха, вызывая измеримое изменение электрических свойств сенсора. Оптимизация этого взаимодействия — ключевой этап в создании надежного и точного инструмента для анализа запаха тела, который найдет применение как в социальной психологии, так и в ранней диагностике заболеваний.
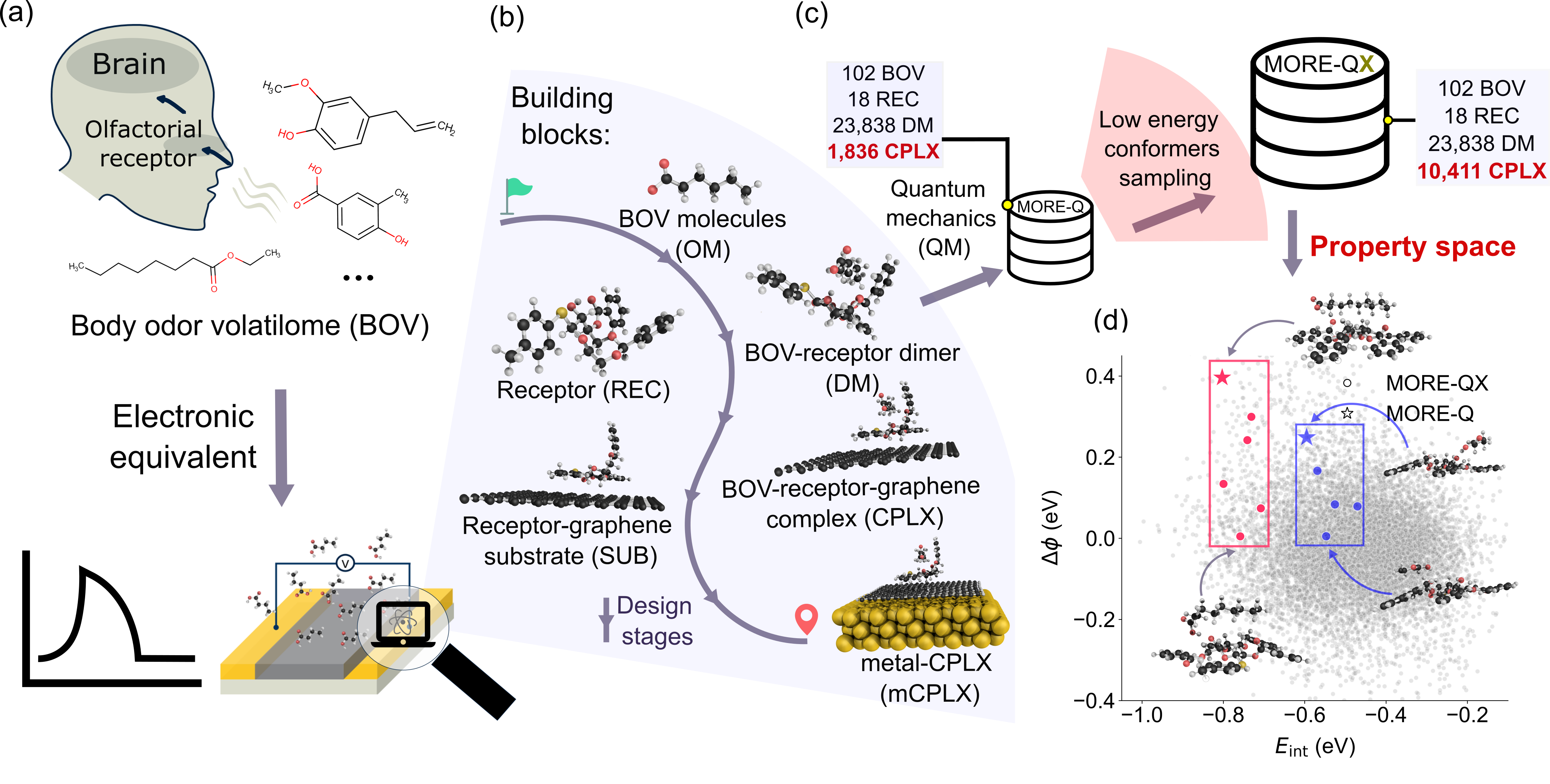
Квантовая механика в поисках обонятельного кода
Для точного моделирования взаимодействия молекул-одороантов с рецепторами необходимы квантово-механические расчеты, такие как Теория функционала плотности (DFT) и более быстрый метод GFN-xTB. DFT обеспечивает высокую точность, но требует значительных вычислительных ресурсов, особенно при моделировании больших молекулярных систем или большого количества конформаций. GFN-xTB представляет собой полуэмпирический метод, который, используя упрощенные приближения, значительно ускоряет вычисления при сохранении приемлемой точности для многих задач, включая анализ взаимодействия с сенсорами. Выбор метода зависит от требуемой точности и доступных вычислительных мощностей, однако оба подхода позволяют рассчитать электронную структуру и энергию взаимодействия, необходимые для понимания механизмов распознавания запахов.
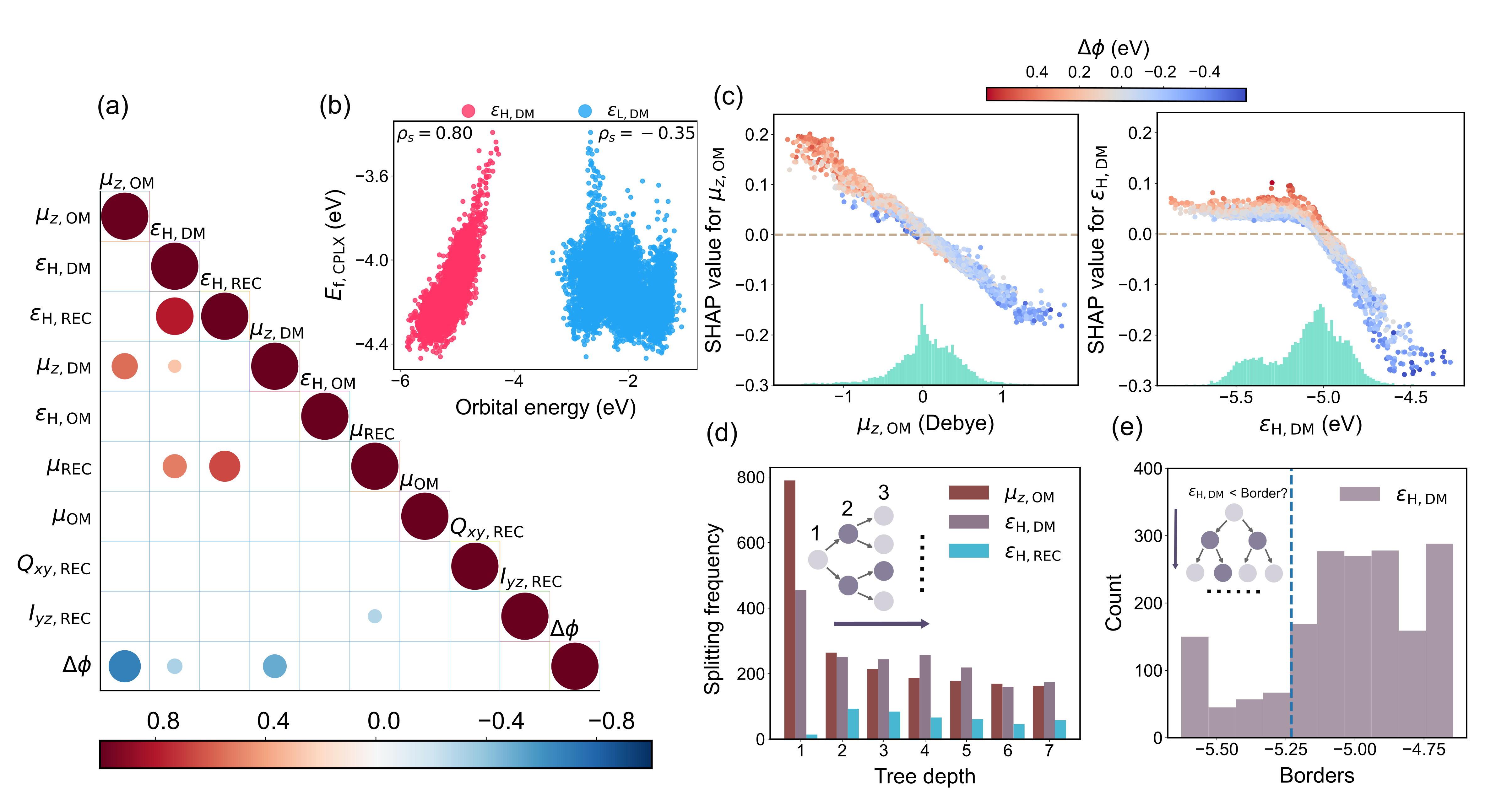
Применение квантово-механических расчетов к набору данных MORE-QX, включающему 23 838 конформаций димеров, позволяет предсказывать ключевые характеристики взаимодействия — энергию адсорбции, изменение рабочей функции и перенос заряда. Энергия адсорбции определяет прочность связи между молекулой запаха и сенсором, изменение рабочей функции отражает изменение электронных свойств сенсора при взаимодействии, а перенос заряда указывает на степень изменения электронной плотности. Совместное определение этих параметров позволяет моделировать и прогнозировать отклик сенсора на различные запахи, обеспечивая основу для разработки высокочувствительных и селективных сенсорных устройств.
Выбор подложки, в частности графена, оказывает существенное влияние на ключевые параметры взаимодействия между молекулой-одорaнтом и рецептором, определяющие чувствительность сенсора. Изменения рабочей функции и энергии адсорбции, рассчитанные с использованием методов квантовой механики, напрямую зависят от электронных свойств подложки. Графен, благодаря своей высокой электропроводности и двумерной структуре, способен эффективно модулировать эти параметры, изменяя распределение электронной плотности и влияя на энергию переноса заряда между молекулой-одорaнтом и сенсором. В результате, оптимизация материала подложки является критически важной для достижения высокой чувствительности и селективности сенсорных устройств.
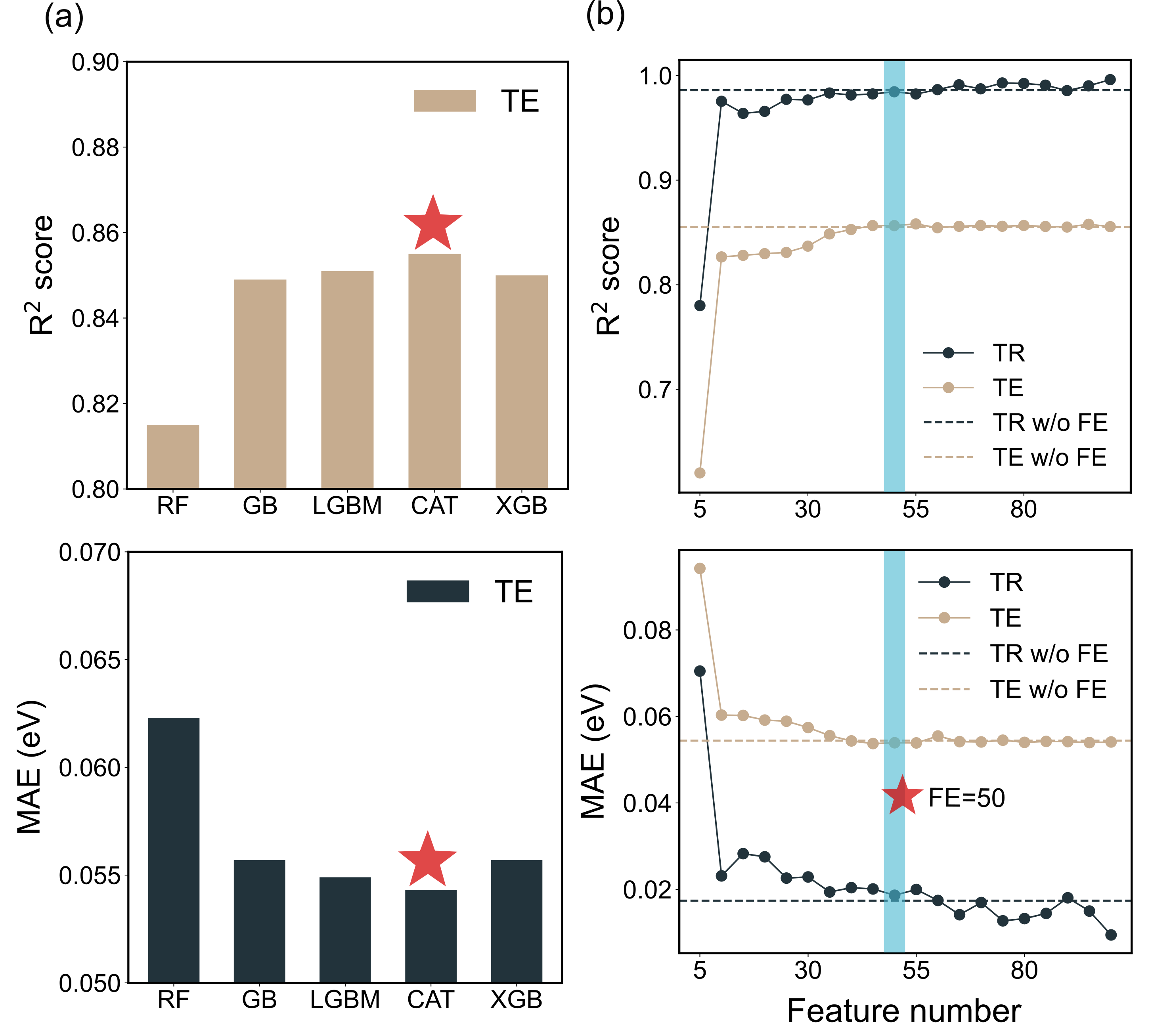
Машинное обучение: Прогнозирование отклика сенсоров
Для прогнозирования отклика сенсоров на различные обоняющие вещества используются модели машинного обучения, в частности, CatBoost. Обучение моделей происходит на основе вычислительно полученных характеристик связывания (binding features), описывающих взаимодействие молекул с сенсорной поверхностью. CatBoost был выбран благодаря своей эффективности в обработке гетерогенных данных и устойчивости к переобучению. Использование этих моделей позволяет предсказывать сенсорный отклик без проведения дорогостоящих и трудоемких физических экспериментов, что значительно ускоряет процесс разработки и оптимизации сенсоров.
Для повышения точности и обобщающей способности моделей машинного обучения применяются методы отбора данных и оптимизации гиперпараметров. В частности, для создания обучающего набора данных используется метод Farthest Point Sampling, позволяющий отобрать наиболее разнообразные и информативные образцы из химического пространства. Оптимизация гиперпараметров модели осуществляется с помощью Bayesian Optimization, алгоритма, эффективно исследующего пространство параметров и находящего конфигурацию, максимизирующую производительность модели на валидационном наборе данных. Данный подход позволяет снизить риск переобучения и обеспечить высокую предсказательную способность модели при работе с новыми, ранее не встречавшимися соединениями.
Использование обученной модели машинного обучения позволяет проводить скрининг обширного химического пространства различных обоняющих веществ для выявления соединений, демонстрирующих наиболее выраженный сигнал для специфических рецепторов. В ходе тестирования, модель показала высокие показатели корреляции, достигающие 0.86 для энергии адсорбции, 0.76 для изменения функции работы и 0.81 для переноса заряда. Данные значения R² подтверждают эффективность подхода для прогнозирования взаимодействия обоняющих веществ с сенсорами и оптимизации их чувствительности.
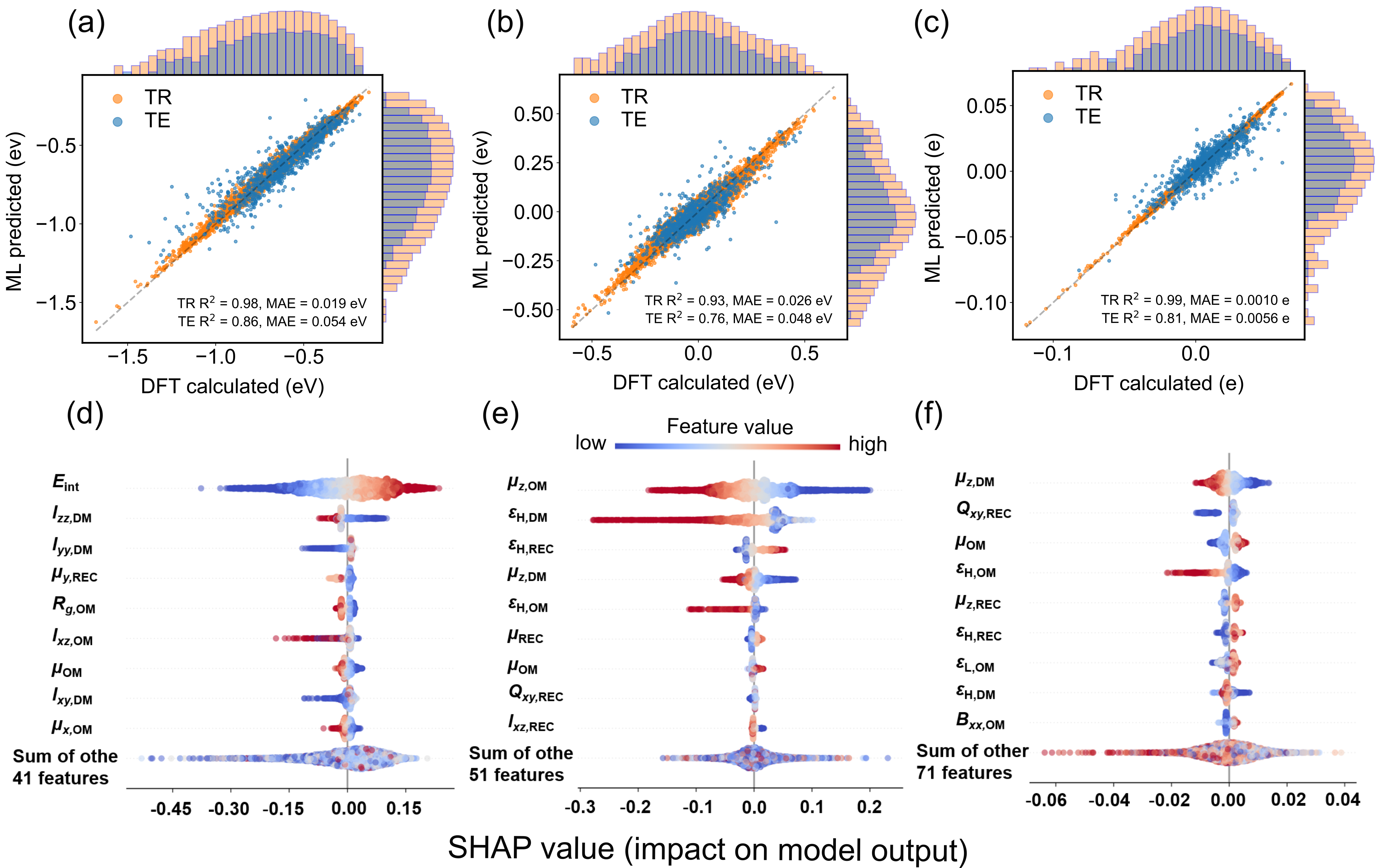
Раскрывая секреты сенсоров: Интерпретируемое машинное обучение
Применение значений SHAP к моделям машинного обучения позволяет выявить ключевые характеристики, определяющие реакцию сенсоров, и точно интерпретировать прогнозы модели. Этот метод обеспечивает детальное понимание того, какие именно особенности данных оказывают наибольшее влияние на результат, позволяя не просто предсказывать, но и объяснять, почему модель пришла к тому или иному выводу. Анализ с использованием SHAP значений дает возможность определить наиболее значимые признаки, ответственные за активацию сенсора, и оценить их вклад в конечный результат, что значительно повышает доверие к модели и облегчает ее применение в различных областях, включая диагностику заболеваний и мониторинг окружающей среды. По сути, SHAP значения раскрывают “черный ящик” машинного обучения, предоставляя ценные сведения о внутренних механизмах принятия решений.
Интерпретируемость моделей машинного обучения открывает уникальную возможность для углубленного понимания физико-химических процессов, лежащих в основе взаимодействия молекул запаха с рецепторами. Анализ влияния отдельных признаков позволяет выявить, какие структурные особенности молекул наиболее значимы для активации рецепторов, раскрывая закономерности, определяющие восприятие запаха. Это не просто описание корреляций, но и возможность получить представление о силах притяжения, стерических факторах и электронных свойствах, формирующих специфичность связывания. Подобный подход способствует созданию более точных моделей, имитирующих биологические механизмы обоняния, и позволяет прогнозировать, как изменения в структуре молекулы запаха повлияют на ее восприятие, что имеет решающее значение для разработки новых сенсорных технологий.
Разработка более чувствительных и селективных электронных носов становится возможной благодаря данному подходу. В процессе обучения моделей, алгоритмы UMAP и SHAP позволили идентифицировать и исключить 932 системы, признанные выбросами, что повысило точность и надежность предсказаний. Это открывает перспективы для широкого спектра применений — от ранней диагностики заболеваний по запаху выдыхаемого воздуха и неинвазивного мониторинга состояния здоровья, до контроля качества продуктов питания и обнаружения загрязняющих веществ в окружающей среде. Возможность рационального проектирования сенсоров, основанная на глубоком понимании принципов взаимодействия между молекулами и рецепторами, значительно расширяет потенциал применения электронных носов в различных областях науки и техники.
Исследование демонстрирует, что предсказание свойств молекулярных строительных блоков для электронных носов требует не просто статистической обработки данных, но и глубокого понимания квантово-механических взаимодействий. Попытки упростить сложные системы неизбежно приводят к искажениям, и эта работа признаёт, что даже самые передовые модели машинного обучения — лишь приближение к реальности. Как заметил Нильс Бор: «Противоположности не уничтожают друг друга, а объединяются». Эта фраза отражает суть подхода MORE-ML: интеграция квантовых данных и машинного обучения позволяет нивелировать недостатки каждой из методик, создавая более точную и интерпретируемую модель для распознавания биомаркеров запаха тела. Игнорирование фундаментальных принципов квантовой механики в угоду удобству расчётов — это все равно что строить дом на песке.
Что дальше?
Представленная работа, как и большинство попыток примирить квантовую механику и машинное обучение, демонстрирует скорее техническую возможность, чем фундаментальное понимание. Модель MORE-ML успешно предсказывает свойства молекул, но остается вопросом, предсказывает ли она понимание этих свойств, или лишь эффективно оперирует корреляциями. Человек, в конце концов, не ищет причин, а находит подтверждения своим ожиданиям — и алгоритм, обученный на данных, не сильно отличается.
Очевидным направлением для дальнейших исследований является расширение набора молекулярных дескрипторов и включение данных о динамике взаимодействия молекул с рецепторами. Однако, истинный прогресс потребует отказа от иллюзии «нейтрального» машинного обучения. Необходимо учитывать, что выбор дескрипторов, алгоритма и даже метрики оценки — это всегда субъективные решения, отражающие предвзятости исследователя. Электронный нос, предсказывающий запах, может быть создан, но понять, как он «чувствует» — задача, требующая не только вычислительных ресурсов, но и самокритики.
В конечном счете, успех подобного подхода зависит не от точности предсказаний, а от способности признать ограниченность самой модели. Человек не ищет идеальную карту, а учится ориентироваться в хаосе. Искусственный интеллект, претендующий на роль «носа», должен научиться тому же.
Оригинал статьи: https://arxiv.org/pdf/2601.00503.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.