Статьи QuantRise
Проверка на прочность: Новый тест для кодирующих ИИ
Автор: Денис Аветисян
Исследователи представили OctoBench — комплексную платформу для оценки способности искусственного интеллекта следовать инструкциям и решать сложные задачи кодирования с учетом реальных ограничений.
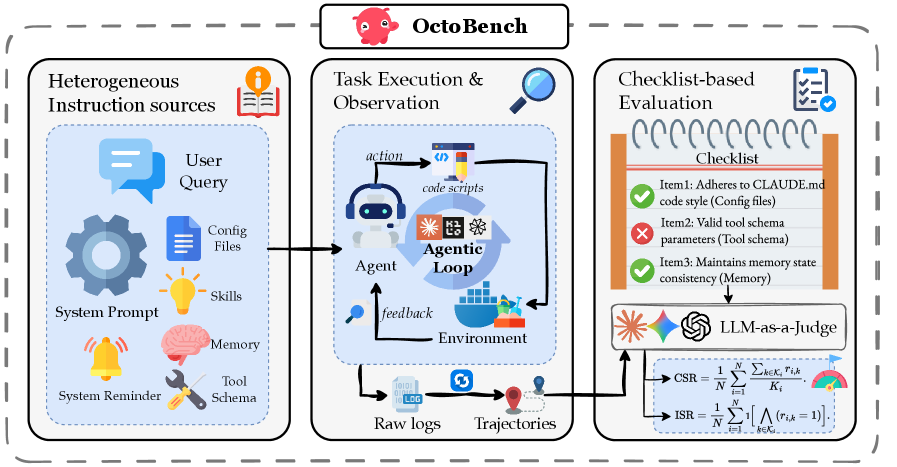
OctoBench — это бенчмарк для оценки возможностей ИИ в области агентного кодирования, ориентированный на проверку соблюдения ограничений и долгосрочное выполнение задач.
Несмотря на успехи современных языковых моделей в генерации кода, оценка их способности следовать сложным инструкциям, особенно при работе с реальными ограничениями и долгосрочными задачами, остаётся сложной проблемой. В данной работе представлена OctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding — новая платформа для всесторонней оценки способности агентов, использующих шаблоны (scaffolds), следовать инструкциям в процессе кодирования. Эксперименты с восемью моделями выявили существенный разрыв между успешным решением задачи и соблюдением заданных ограничений, подчеркивая необходимость разработки специализированных методов обучения и оценки. Сможем ли мы создать действительно надежных и предсказуемых кодирующих агентов, способных эффективно работать в сложных, реальных условиях?
Автоматизация Кодирования: Новый Рубеж и Его Сложности
Автоматизированное кодирование с использованием больших языковых моделей (LLM), известное как агентное кодирование, представляет собой перспективный подход к значительному повышению производительности разработчиков и автоматизации рутинных задач. Данная технология позволяет LLM самостоятельно выполнять полный цикл разработки программного обеспечения — от понимания требований до генерации, тестирования и отладки кода. Вместо того, чтобы разработчик вручную выполнял каждый этап, LLM выступает в роли интеллектуального ассистента, способного самостоятельно принимать решения и адаптироваться к изменяющимся условиям. Это открывает возможности для ускорения процесса разработки, снижения затрат и высвобождения ресурсов для решения более сложных и творческих задач. Ожидается, что агентное кодирование позволит значительно упростить создание программных продуктов и сделать разработку доступной для более широкого круга специалистов.
Надежность поведения кодирующих агентов напрямую зависит от их способности точно следовать инструкциям, особенно в ситуациях, требующих выполнения множества последовательных шагов. Сложность заключается в том, что агенты должны не просто понимать отдельные указания, но и сохранять контекст и последовательность действий на протяжении всего процесса разработки. Неспособность корректно интерпретировать сложные инструкции или отслеживать взаимосвязи между различными задачами приводит к ошибкам и снижает эффективность автоматизации. Поэтому обеспечение устойчивого следования инструкциям в многоступенчатых сценариях является ключевым вызовом при создании надежных и полезных кодирующих агентов, способных к автономной разработке программного обеспечения.
Существующие методы оценки производительности агентов, основанных на больших языковых моделях, зачастую не способны адекватно отразить сложность взаимодействия в длительных последовательностях действий и при наличии разнообразных ограничений. Традиционные метрики, фокусирующиеся на локальной корректности отдельных шагов, не учитывают кумулятивные ошибки и непредсказуемые последствия, возникающие в процессе выполнения многоэтапных задач. Неспособность этих методов выявлять тонкие нюансы в поведении агентов приводит к завышенным оценкам их надежности и эффективности, особенно в ситуациях, требующих адаптации к меняющимся условиям и соблюдения множественных, часто противоречивых, требований. Таким образом, возникает необходимость в разработке более совершенных и реалистичных инструментов оценки, способных достоверно отражать истинные возможности и ограничения агентов в сложных сценариях.
В связи с развитием автоматизированного кодирования с использованием больших языковых моделей, возникла острая потребность в более совершенных и реалистичных критериях оценки их возможностей. Существующие методы часто оказываются неспособны адекватно отразить сложность взаимодействия в долгосрочных задачах, особенно при наличии разнообразных ограничений. Наблюдается значительный разрыв между способностью модели корректно выполнять отдельные проверки и достижением общего успеха в решении поставленной задачи, что указывает на необходимость разработки новых оценочных методик, способных более точно измерять и прогнозировать эффективность агентов в реальных сценариях разработки программного обеспечения. Это позволит более эффективно выявлять слабые места и направлять дальнейшие исследования в области автоматизированного кодирования.
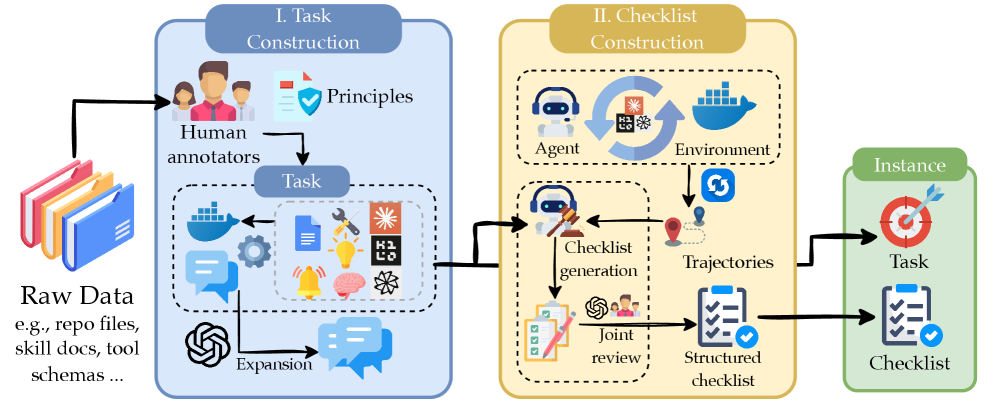
OctoBench: Испытательный Полигон для Агентов в Реальном Коде
OctoBench представляет собой новый подход к оценке агентов, выполняющих задачи кодирования, основанный на непосредственной работе агента внутри существующей кодовой базы. В отличие от традиционных бенчмарков, использующих изолированные задачи, OctoBench моделирует реальные сценарии разработки, где агенту необходимо взаимодействовать с существующим кодом, учитывать его структуру и соблюдать существующие соглашения. Это достигается путем предоставления агенту доступа к репозиторию кода и постановки задач, требующих внесения изменений или добавления новой функциональности непосредственно в этот репозиторий. Такой подход позволяет более точно оценить способность агента к адаптации, навигации по сложному коду и интеграции изменений в существующую кодовую базу.
Методология, основанная на работе с репозиторием кода, в OctoBench имитирует типичные сценарии разработки программного обеспечения, что повышает реалистичность и применимость бенчмарка. В отличие от изолированных задач, OctoBench требует от агента взаимодействия с существующей кодовой базой, включающей зависимости, историю изменений и необходимость соблюдения принятых соглашений о кодировании. Это позволяет более точно оценить способность агента к решению сложных задач, возникающих в реальных проектах, таких как рефакторинг, исправление ошибок и добавление новых функций в контексте уже существующего кода, а не в вакууме.
В основе OctoBench лежит оценка способности агента ориентироваться в сложных ограничениях и поддерживать следование инструкциям на протяжении длительных взаимодействий. Бенчмарк специально разработан для проверки не только начального понимания задачи, но и способности агента адаптироваться к новым требованиям и поддерживать согласованность действий при выполнении многоэтапных задач. Оценивается устойчивость агента к отклонениям от первоначальных инструкций и его способность к самокоррекции в процессе выполнения, что критически важно для реалистичных сценариев разработки программного обеспечения. Акцент делается на оценке долгосрочной производительности и надежности агента в динамичной среде, где требования и ограничения могут меняться.
Оценка в OctoBench автоматизирована посредством использования чек-листов и подхода LLM-as-a-judge. Чек-листы позволяют разбить задачу на отдельные критерии, что обеспечивает более детальную оценку. LLM-as-a-judge использует большую языковую модель для оценки соответствия выполнения каждого критерия и общей успешности. Результаты показывают существенный разрыв между высокой степенью выполнения отдельных проверок (79.75%-85.64%) и общей успешностью выполнения задачи (9.66%-28.11%), что указывает на трудности агентов в поддержании последовательности и целостности решения в процессе длительного взаимодействия с кодовой базой.
Разрешение Конфликтов и Соблюдение Ограничений: Основа Надежного Автоматического Кодирования
Эффективная работа агентов, основанная на кодировании, требует надежных механизмов разрешения конфликтов, поскольку агенты должны уметь правильно расставлять приоритеты между поступающими инструкциями. В ситуациях, когда несколько источников дают противоречивые указания, агент должен определить наиболее релевантные и важные директивы для достижения поставленной цели. Неспособность эффективно разрешать конфликты приводит к ошибкам в выполнении задач и снижает общую производительность системы. Разрешение конфликтов является критически важным аспектом обеспечения надежности и предсказуемости поведения агента, особенно в сложных сценариях с множеством взаимодействующих факторов.
Приоритизация инструкций, являющаяся ключевым аспектом успешного функционирования агентов, подразумевает способность агента выделять наиболее релевантные директивы из множества источников. Этот процесс включает в себя анализ поступающих команд, оценку их значимости и последовательность выполнения, чтобы избежать конфликтов и обеспечить достижение поставленных целей. Эффективная приоритизация необходима для обработки ситуаций, когда несколько источников предоставляют противоречивые или пересекающиеся инструкции, требуя от агента логического выбора и последовательного выполнения задач в соответствии с установленными критериями и приоритетами.
Проверка ограничений (Constraint Verification) является критически важным этапом в функционировании агентов, обеспечивающим соответствие их действий как системным инструкциям, заданным в промптах, так и установленным политикам, определенным в репозиториях данных. Этот процесс подразумевает автоматизированную верификацию каждого действия агента на предмет соблюдения заданных ограничений, предотвращая выполнение операций, которые могут нарушить целостность данных, привести к нежелательным последствиям или противоречить установленным правилам. Эффективная проверка ограничений напрямую влияет на надежность и предсказуемость поведения агента, являясь ключевым фактором успешного выполнения задач в сложных средах.
В рамках OctoBench для оценки возможностей агентов в разрешении конфликтов и соблюдении ограничений используются инструменты Droid, Kilo и Claude Code. Полученные данные демонстрируют существенный разрыв между успешностью выполнения отдельных проверок (Check Item Success Rate) в диапазоне 79.75%-85.64% и общим успехом решения задачи (Instance Success Rate), который составляет всего 9.66%-28.11%. Эта разница указывает на то, что агенты способны успешно выполнять отдельные шаги, но испытывают затруднения при комплексном решении задач, требующих последовательного применения инструкций и соблюдения всех ограничений.
Траектория Действий: Раскрывая Скрытые Механизмы Поведения Агентов
В основе OctoBench лежит детальный анализ траекторий действий агента, позволяющий получить глубокое понимание процесса принятия решений. Этот подход предполагает изучение последовательности шагов, предпринятых агентом при решении поставленной задачи, что позволяет выявить ключевые моменты, влияющие на успех или неудачу. Анализ траекторий не ограничивается простым отслеживанием действий, но и позволяет оценить эффективность каждой операции и выявить потенциальные ошибки в логике агента. Благодаря такому гранулярному исследованию, разработчики получают возможность понять, какие факторы приводят к сбоям и как оптимизировать архитектуру агента для повышения его производительности и надежности.
Анализ последовательности действий, совершаемых агентом, позволяет исследователям выявлять первопричины неудач и области для совершенствования. Вместо простого констатирования факта ошибки, данный подход предоставляет возможность детального разбора каждого шага, раскрывая логику, приведшую к нежелательному результату. Например, если агент не смог успешно выполнить задачу кодирования, анализ траектории его действий может показать, что проблема заключалась в неправильной интерпретации инструкций, неоптимальном выборе алгоритма или ошибках в синтаксисе. Такое глубокое понимание не только позволяет исправить конкретную ошибку, но и выявить системные недостатки в архитектуре агента или стратегии следования инструкциям, что является ключевым для создания более надежных и эффективных систем искусственного интеллекта.
Детальное понимание поведения агента, полученное в ходе анализа траекторий, открывает возможности для целенаправленной оптимизации его архитектуры и стратегий следования инструкциям. Исследователи могут не просто констатировать неудачу, но и выявлять конкретные этапы, где возникают ошибки, и на этой основе вносить изменения в алгоритмы принятия решений. Такой подход позволяет избегать глобальных переработок, фокусируясь на узких местах и повышая эффективность агента в решении поставленных задач. Благодаря возможности точной настройки, становится возможным создавать более надежные, производительные и автономные системы, способные к самостоятельному написанию и отладке кода.
Несмотря на текущие ограничения, отраженные в показателях успешности OctoBench — от 9,66% до 28,11% — наблюдаемый прогресс в анализе траекторий поведения агентов открывает путь к созданию более надежных, эффективных и автономных инструментов для разработки программного обеспечения. Эти усовершенствования потенциально способны трансформировать ландшафт разработки, позволяя агентам самостоятельно решать сложные задачи кодирования, оптимизировать процессы и снижать потребность в ручном вмешательстве. Хотя существующие модели еще далеки от совершенства, углубленное понимание причин неудач, полученное благодаря анализу последовательности действий, позволяет целенаправленно улучшать архитектуру агентов и стратегии следования инструкциям, приближая эру интеллектуальных помощников для программистов.
Исследование демонстрирует стремление понять границы и возможности современных систем кодирования, работающих по принципам агентности. Авторы OctoBench, по сути, проводят своего рода реверс-инжиниринг процесса следования инструкциям, выявляя слабые места существующих методов оценки. Как однажды заметил Линус Торвальдс: «Большинство хороших программистов делают вещи, которые не нужно делать, чтобы научиться чему-то новому.» Этот подход прекрасно иллюстрирует суть OctoBench — не просто проверить, насколько хорошо система выполняет задачи, а разобраться, как она мыслит и какие ограничения ей мешают, особенно при работе с длинными последовательностями и сложными условиями. Подобный анализ позволяет углубить понимание принципов работы подобных систем и найти пути для их улучшения.
Куда Дальше?
Представленный OctoBench, несомненно, выявляет узкие места в существующих системах агентного кодирования. Однако, каждая проверка — это лишь более сложный вопрос, а не окончательный ответ. Оценка следования инструкциям, особенно в контексте реалистичных ограничений, требует не просто количественных метрик, но и качественного анализа возникающих «обходных путей». Каждый эксплойт начинается с вопроса, а не с намерения. Истинная проверка — это попытка сломать систему, прежде чем она начнёт ломать вас.
Следующим шагом представляется не столько увеличение масштаба бенчмарка, сколько углубление понимания причин неудач. Важно исследовать, какие типы ограничений наиболее сложны для обработки, и как различные архитектуры LLM справляются с компромиссами между соответствием инструкциям и удовлетворением ограничений. Более того, необходимо разработать методы автоматического выявления и исправления «галлюцинаций», возникающих в процессе долгосрочного выполнения задач.
В конечном итоге, задача заключается не в создании идеального бенчмарка, а в разработке самообучающихся систем, способных самостоятельно выявлять и преодолевать свои ограничения. Понимание системы — значит взломать её, умом или руками. Истинное знание — это реверс-инжиниринг реальности, а не просто её описание.
Оригинал статьи: https://arxiv.org/pdf/2601.10343.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.