Квантовые технологии
Сжатие моделей: новый подход к борьбе с ошибками квантования
Автор: Денис Аветисян
Исследователи предлагают эффективный метод уменьшения потерь точности при сжатии нейронных сетей с помощью квантования, основанный на генерации более качественных данных для калибровки.
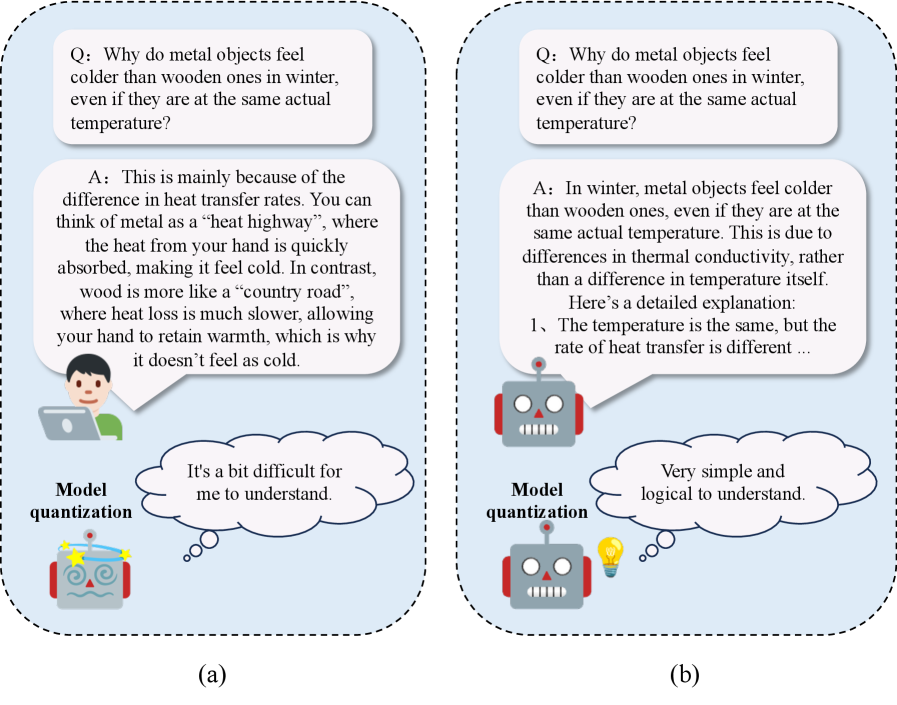
Предлагаемый метод FAQ использует большие языковые модели для синтеза калибровочных данных, учитывая семейство активаций, что позволяет снизить ошибки квантования.
Несмотря на эффективность постобработочной квантизации (PTQ) для сжатия больших языковых моделей (LLM), точность квантования критически зависит от репрезентативности калибровочных данных. В статье ‘FAQ: Mitigating Quantization Error via Regenerating Calibration Data with Family-Aware Quantization’ предложен метод FAQ, использующий знания о семействе моделей для генерации высококачественных калибровочных данных, что позволяет точнее отражать распределение активаций. Эксперименты на моделях Qwen3-8B показали, что FAQ снижает потерю точности до 28.5% по сравнению с использованием исходных данных, демонстрируя потенциал для эффективного сжатия LLM. Возможно ли дальнейшее улучшение качества калибровочных данных за счет использования более сложных методов генерации и отбора?
Квантование: Баланс между Точностью и Эффективностью
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, однако их масштабные размеры создают значительные трудности при практическом внедрении. Огромное количество параметров, необходимое для достижения высокой производительности, влечет за собой колоссальные вычислительные затраты и требования к объему памяти. Это затрудняет развертывание таких моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы, а также увеличивает энергопотребление и задержки при обработке запросов. В связи с этим, актуальной задачей является разработка методов, позволяющих эффективно сжимать модели без существенной потери качества, чтобы сделать их более доступными и удобными в использовании.
Послетренировочная квантизация (PTQ) представляет собой перспективный подход к уменьшению размера больших языковых моделей, однако её применение часто сопряжено с ухудшением точности. Этот феномен объясняется введением квантованного шума — погрешности, возникающей при замене вещественных чисел на целочисленные представления с меньшей разрядностью. Кроме того, распределение активаций, то есть выходных значений нейронов, может смещаться в процессе квантизации, что приводит к дополнительным ошибкам и снижению производительности модели. Степень деградации точности напрямую зависит от выбранной разрядности и особенностей архитектуры модели, требуя тщательной проработки методов калибровки и компенсации возникающих искажений.
Традиционные методы постобработочной квантизации (PTQ) зачастую испытывают трудности с сохранением производительности, особенно при снижении точности до крайне низких значений, таких как INT4. Это связано с тем, что уменьшение числа бит, используемых для представления весов и активаций, приводит к увеличению квантованного шума и искажению распределения активаций. В результате, модель теряет способность эффективно обобщать данные, что проявляется в снижении точности и ухудшении качества генерируемого текста или результатов классификации. Несмотря на значительные усилия по оптимизации PTQ, достижение приемлемого уровня производительности при экстремально низких битовых разрядностях остается сложной задачей, требующей разработки новых алгоритмов и стратегий калибровки.
Для успешной квантизации больших языковых моделей, критически важны репрезентативные данные калибровки, позволяющие минимизировать потери точности, возникающие при снижении разрядности. Однако, сбор и обработка таких данных представляют собой значительные вычислительные затраты. Процесс требует анализа большого объема информации, необходимого для точного определения распределения активаций и весов модели. Особенно остро эта проблема проявляется при переходе к экстремально низким разрядностям, таким как INT4, где даже незначительные отклонения в калибровочных данных могут приводить к существенной деградации производительности. Таким образом, оптимизация методов сбора и обработки данных калибровки является ключевой задачей для эффективного развертывания квантованных больших языковых моделей, требующей баланса между вычислительными ресурсами и сохранением высокой точности.
Семейная Осведомленность: Новый Подход к Калибровке
Предлагаемый фреймворк FAQ использует концепцию “Семейной осведомленности” (Family Awareness), основанную на выявленной закономерности: модели, разработанные в рамках единой линии развития, демонстрируют существенную согласованность в паттернах активации. Это означает, что внутренние представления и реакции на входные данные у моделей из одного “семейства” имеют высокую степень корреляции. FAQ эксплуатирует эту особенность, предполагая, что знания, полученные от более крупных моделей в рамках данного семейства, могут быть эффективно перенесены на меньшие модели для улучшения калибровки, снижая необходимость в обширной и дорогостоящей ручной разметке данных.
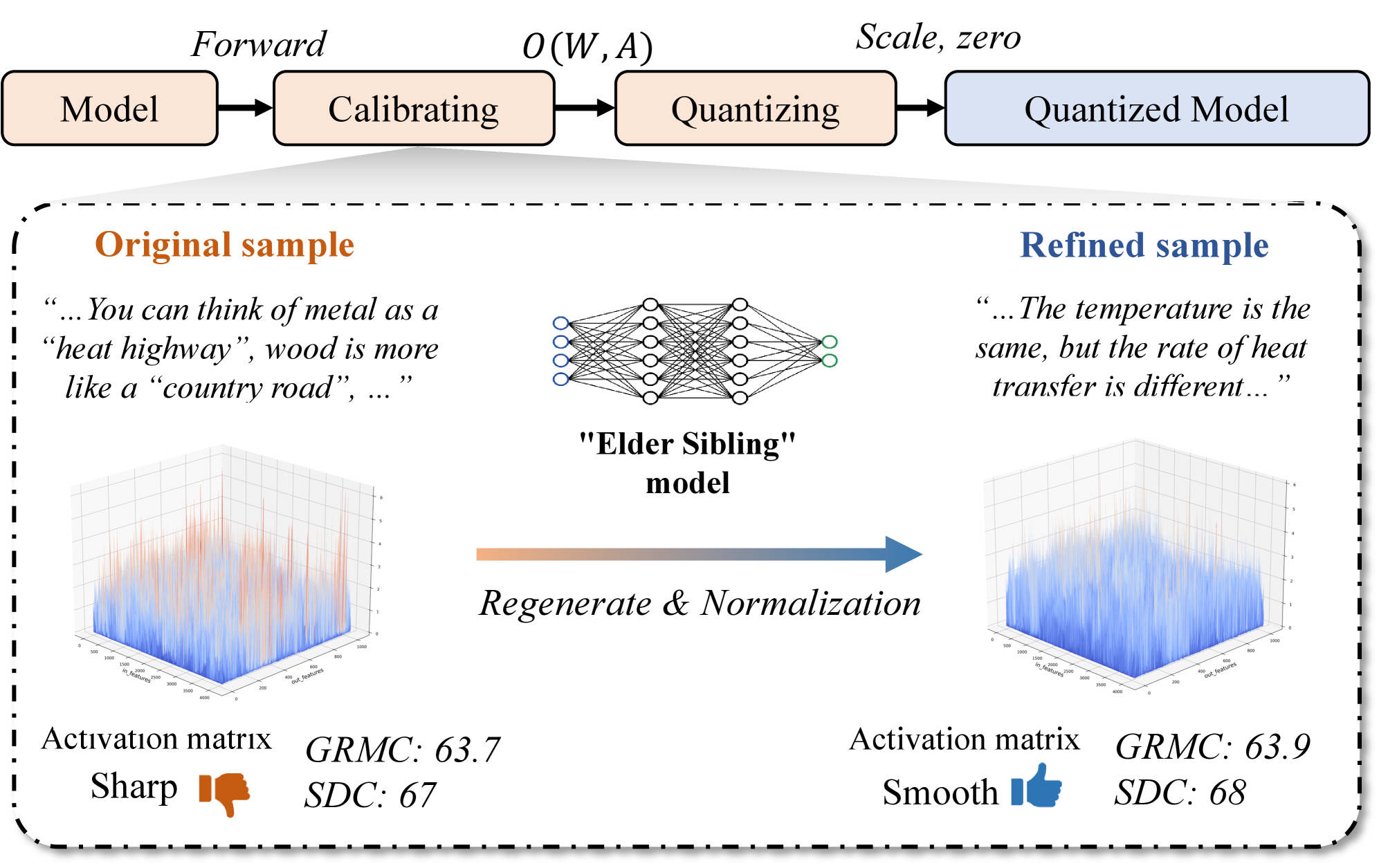
Методика FAQ (Family Awareness Calibration) использует более крупные модели, принадлежащие к одной и той же «семье» (разработанные на основе одного и того же базового алгоритма и обучающие данные), для генерации высококачественных данных для калибровки. Это позволяет существенно снизить потребность в сборе обширных и дорогостоящих наборов данных, необходимых для традиционных методов калибровки. Вместо этого, FAQ использует возможности более мощных моделей для синтеза данных, отражающих желаемые характеристики калибровки, что повышает эффективность и экономичность процесса.
Синтез калибровочных данных внутри семейства моделей осуществляется с использованием методики Chain-of-Thought (CoT) промптинга. Этот подход предполагает генерацию промежуточных рассуждений, имитирующих процесс принятия решений целевой моделью, что позволяет создать данные, точно отражающие распределение активаций. CoT промпты направляют более крупную модель из того же семейства на генерацию ответов, в которых явно прослеживается ход мысли, необходимый для получения результата. В результате формируется набор данных, который учитывает внутренние характеристики целевой модели и обеспечивает более эффективную калибровку, чем использование произвольных данных.
Нормализация калибровки, как этап обработки синтезированных данных, обеспечивает совместимость и репрезентативность выборки. Процесс включает в себя оценку соответствия синтезированных активаций распределению активаций целевой модели, отбраковывая образцы, демонстрирующие значительные отклонения. Отбор репрезентативных образцов осуществляется на основе метрик, отражающих разнообразие активаций, что позволяет избежать перекоса в калибровочном наборе данных. Данный этап критически важен для повышения точности и обобщающей способности калибровки, поскольку позволяет использовать только те данные, которые наиболее точно отражают поведение целевой модели в различных сценариях.
Эмпирическое Подтверждение: Результаты на Различных Моделях
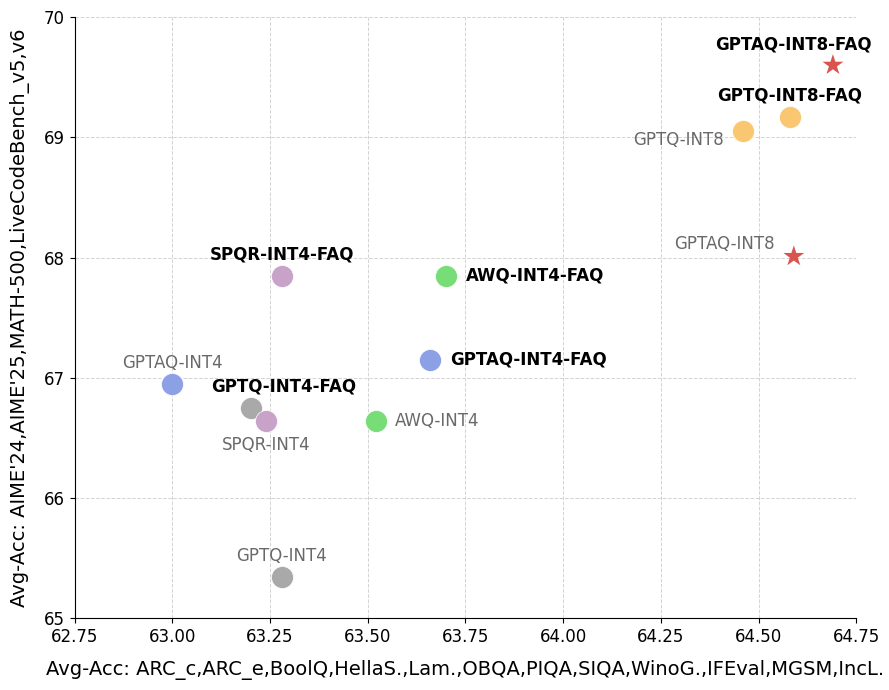
Эксперименты, проведенные с моделями Qwen3-8B и Qwen3-30B-A3B, показали, что предложенный метод FAQ последовательно превосходит существующие методы квантизации, включая GPTQ, AWQ, SmoothQuant и OmniQuant. В ходе тестирования наблюдалась более высокая производительность FAQ по сравнению с указанными альтернативами, что подтверждает его эффективность в снижении потерь точности при уменьшении разрядности моделей. Результаты демонстрируют стабильное превосходство FAQ в различных сценариях и архитектурах, что делает его перспективным решением для оптимизации больших языковых моделей.
Оценка предложенного метода FAQ на стандартных наборах данных Wikitext2, C4 и LAMBADA с использованием метрики Perplexity подтвердила его превосходство над существующими методами квантизации как при 8-битной (INT8), так и при 4-битной (INT4) точности. В ходе экспериментов было показано, что FAQ обеспечивает более низкое значение Perplexity на указанных наборах данных по сравнению с альтернативными подходами, что свидетельствует о лучшем сохранении языкового моделирования после квантизации. Данный результат подтверждает эффективность предложенного метода в минимизации потери точности при значительном сжатии модели.
Предложенный метод позволяет минимизировать потерю точности при квантизации, достигая снижения до 28.5% по сравнению с базовыми методами Post-Training Quantization (PTQ). Это достигается за счет существенного сжатия модели, что обеспечивает возможность ее эффективного развертывания на устройствах с ограниченными ресурсами. Снижение потерь точности позволяет сохранять высокую производительность модели при значительном уменьшении ее размера, делая ее пригодной для использования в сценариях, требующих оптимизации ресурсов, таких как мобильные устройства или системы с ограниченной памятью.
Экспериментальные результаты демонстрируют устойчивость метода FAQ к изменениям размера модели и архитектуры. На специализированных задачах, включающих AIME, MATH и LiveCodeBench, достигнута точность в диапазоне от 67.84% до 68.74%. Кроме того, наблюдается улучшение возможностей языкового моделирования, что подтверждается снижением показателя Perplexity на датасете LAMBADA, что свидетельствует о повышении качества генерируемого текста и более эффективном прогнозировании последовательностей.
К Повсеместным Языковым Моделям: Влияние и Перспективы
Значительное уменьшение размера языковых моделей, достигнутое благодаря методу FAQ, открывает новые возможности для их развертывания на периферийных устройствах и в средах с ограниченными ресурсами. Такая оптимизация позволяет интегрировать передовые возможности обработки естественного языка непосредственно в мобильные телефоны, встроенные системы и другие устройства, не требующие постоянного подключения к облачным серверам. Это особенно важно для приложений, требующих конфиденциальности данных, низкой задержки или надежной работы в условиях нестабильного интернет-соединения. Благодаря FAQ, сложные модели становятся более доступными и применимыми в широком спектре сценариев, от персональных помощников и автоматического перевода до анализа данных в режиме реального времени и управления «умными» устройствами.
Значительное уменьшение размеров языковых моделей открывает новые возможности для их применения в самых разнообразных сферах и делает передовые технологии обработки естественного языка доступными для более широкой аудитории. Ранее требовавшие мощных серверов и значительных вычислительных ресурсов, сложные алгоритмы анализа текста и генерации контента теперь могут быть реализованы на мобильных устройствах, встроенных системах и других платформах с ограниченными ресурсами. Это расширяет спектр потенциальных приложений, включая персонализированных виртуальных ассистентов, интеллектуальные системы поддержки принятия решений, автоматизированные сервисы клиентской поддержки и образовательные инструменты, доступные даже в регионах с ограниченной инфраструктурой. Повышение доступности передовых NLP-технологий способствует демократизации знаний и расширяет возможности для инноваций в различных областях, от медицины и образования до бизнеса и развлечений.
Перспективные исследования направлены на расширение концепции «семейной осведомленности» при квантовании моделей, переходя от работы внутри одной архитектуры к эффективному квантованию моделей, принадлежащих к различным семействам. Это предполагает разработку методов, способных учитывать специфические характеристики каждой архитектуры для достижения оптимального баланса между точностью и размером модели. Кроме того, активно изучаются адаптивные стратегии квантования, позволяющие динамически изменять степень квантования различных частей модели в зависимости от их чувствительности к потерям точности. Такой подход позволит еще более эффективно сжимать большие языковые модели, открывая возможности для их развертывания на широком спектре устройств и в различных приложениях, требующих минимальных ресурсов.
Постоянное совершенствование процесса генерации калибровочных данных и исследование новых методов квантизации остаются ключевыми направлениями для дальнейшего повышения эффективности больших языковых моделей. Ученые стремятся к разработке алгоритмов, позволяющих с минимальными потерями точности представлять модели в более компактном виде. Особое внимание уделяется автоматизации подбора наиболее репрезентативных калибровочных данных, что позволит снизить зависимость от ручной настройки и повысить обобщающую способность моделей. Исследование инновационных техник квантизации, таких как смешанная точность и адаптивные стратегии, открывает перспективы для создания моделей, способных эффективно работать на устройствах с ограниченными ресурсами, расширяя возможности применения передовых технологий обработки естественного языка.
Изучение методов сжатия моделей, представленное в данной работе, напоминает кропотливую работу садовника, взращивающего редкое растение. Авторы предлагают подход FAQ, где калибровка данных производится не случайным образом, а с использованием более крупной модели из того же семейства. Этот процесс тонкой настройки, направленный на выравнивание распределений активаций и снижение ошибок квантования, требует терпения и глубокого понимания внутренних механизмов системы. Как заметил Карл Фридрих Гаусс: «Недостаточно быть гением, нужно еще уметь использовать свой гений». В контексте квантования, это означает, что даже самые передовые алгоритмы нуждаются в тщательной калибровке и адаптации к конкретным условиям, чтобы раскрыть свой истинный потенциал и избежать непредсказуемых сбоев. В конечном счете, стабильность системы определяется не только архитектурными решениями, но и заботой о деталях в процессе ее взращивания.
Что дальше?
Представленная работа, как и многие другие в области пост-тренировочной квантизации, пытается обуздать неумолимый закон энтропии. Создание калибровочных данных, пусть и с использованием более крупных моделей, — это лишь временная передышка. Распределение активаций, будучи хаотичным по своей природе, неизбежно отклонится от идеала, и ошибки квантизации вновь дадут о себе знать. Архитектура же — это не структура, а компромисс, застывший во времени, и любой выбор в пользу определенной схемы квантизации — это пророчество о будущих сбоях.
Более глубокое понимание природы активаций — вот куда следует направить усилия. Не просто синтез данных, а создание моделей, способных предсказывать изменения в распределении активаций в процессе эксплуатации. Это требует отказа от упрощенных предположений о стационарности и принятия неизбежной сложности реальных систем. Технологии сменяются, зависимости остаются — и зависимость от качественных калибровочных данных, вероятно, никуда не денется.
В конечном итоге, задача не в том, чтобы минимизировать ошибку квантизации, а в том, чтобы создать системы, устойчивые к ней. Эволюция нейронных сетей, подобно эволюции жизни, не стремится к совершенству, а к адаптации. И эта адаптация, возможно, заключается не в точности вычислений, а в способности функционировать в условиях неопределенности.
Оригинал статьи: https://arxiv.org/pdf/2601.11200.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.