Статьи QuantRise
Искусство имитации поиска: как оценить реалистичность запросов?
Автор: Денис Аветисян
В статье представлена систематизация методов оценки качества симуляции поисковых запросов, позволяющая выбрать наиболее эффективные подходы для исследований в области информационного поиска.
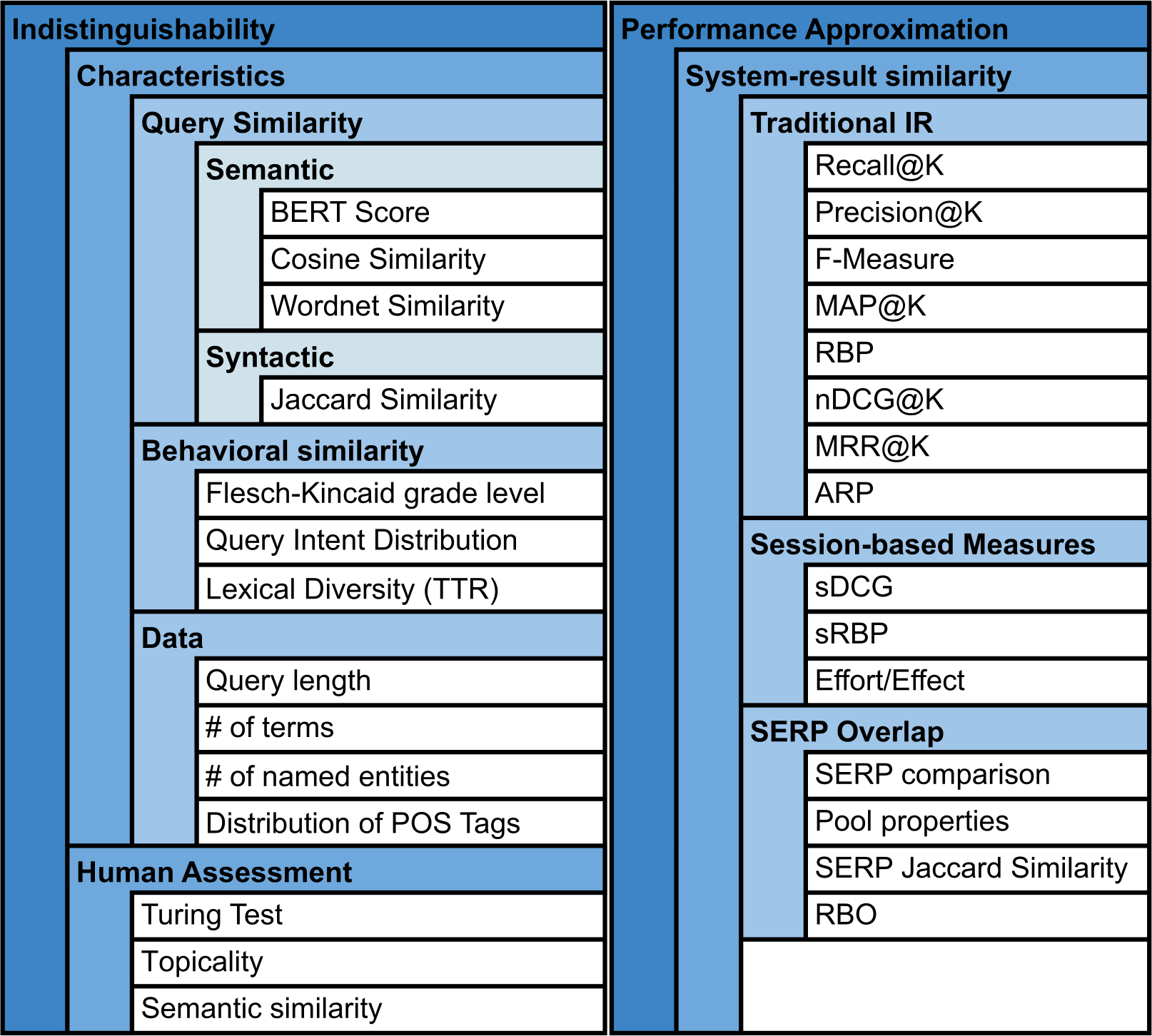
Предложена таксономия мер валидации, проведен эмпирический анализ избыточности и взаимодополняемости метрик, и представлена библиотека программного обеспечения для дальнейших исследований.
Оценка достоверности симуляций пользовательских запросов остается сложной задачей при оценке информационно-поисковых систем, ограничивая надежность результатов моделирования. В настоящей работе, ‘Validating Search Query Simulations: A Taxonomy of Measures’, предложена систематизация существующих метрик для валидации симулированных запросов относительно реальных поисковых паттернов. Разработанная таксономия, подкрепленная эмпирическим анализом на разнообразных датасетах, позволяет выявить избыточные и взаимодополняющие показатели оценки. Каким образом предложенный инструментарий и классификация могут способствовать более эффективной разработке и применению реалистичных симуляций пользовательского поведения в информационном поиске?
Вызов Реалистичного Моделирования Запросов
Для эффективной разработки и оценки систем информарного поиска требуются обширные наборы запросов, однако получение реальных пользовательских запросов сопряжено со значительными трудностями. Ограничения, связанные с конфиденциальностью персональных данных, а также высокая стоимость сбора и обработки таких данных, делают использование реальных запросов непрактичным для масштабных исследований и постоянной оптимизации систем. Это особенно актуально в контексте быстро меняющихся информационных потребностей пользователей и необходимости оперативного тестирования новых алгоритмов поиска. В результате, исследователи и разработчики вынуждены искать альтернативные решения для создания достаточного объема данных, необходимых для адекватной тренировки и оценки эффективности систем информарного поиска.
Для преодоления трудностей, связанных с получением реальных запросов пользователей, активно развивается метод имитации запросов — “Query Simulation”. Однако, ценность этого подхода напрямую зависит от того, насколько точно сгенерированные запросы отражают поведение реальных пользователей в процессе поиска информации. Имитация должна учитывать не только частотность ключевых слов, но и семантическую сложность запросов, вариативность формулировок, а также типичные ошибки и опечатки. Недостаточная точность моделирования пользовательского поведения может привести к тому, что оценка систем поиска будет проводиться на нерепрезентативных данных, что, в свою очередь, может привести к разработке неоптимальных алгоритмов и снижению качества поисковой выдачи для конечного пользователя. Таким образом, ключевым вызовом является создание моделей, способных достоверно воспроизводить сложность и многообразие реальных поисковых запросов.
Недостаточная проверка достоверности смоделированных запросов может привести к ошибочным оценкам эффективности систем информационного поиска. Если искусственно созданные запросы не отражают реальное поведение пользователей, результаты тестирования могут быть искажены, что приведет к принятию неверных решений при разработке и оптимизации поисковых систем. Такая ситуация особенно опасна, поскольку системы, успешно работающие на смоделированных данных, могут продемонстрировать значительно худшие результаты при взаимодействии с реальными пользователями, что снизит их полезность и приведет к неудовлетворенности пользователей. В конечном итоге, надежность и эффективность систем информационного поиска напрямую зависят от качества валидации используемых для обучения и оценки синтетических запросов.
Таксономия для Строгой Валидации
Эффективная валидация моделирования запросов требует структурированного подхода, и таксономия аспектов валидации предоставляет необходимую организацию. Данная таксономия классифицирует аспекты валидации по различным признакам, позволяя систематически оценивать качество симуляции по множеству измерений. Она обеспечивает возможность последовательного анализа и выявления слабых мест в процессе моделирования, что критически важно для обеспечения достоверности результатов. Использование таксономии позволяет перейти от неформальной оценки к количественно измеримому и воспроизводимому процессу валидации.
Таксономия аспектов валидации обеспечивает систематическую оценку качества моделирования по различным измерениям. Она позволяет классифицировать и структурировать различные параметры, используемые для проверки адекватности симулированных данных реальным запросам и поведению информационно-поисковых систем. В рамках данной таксономии, каждый аспект валидации рассматривается как отдельная категория, что позволяет проводить детальный анализ и выявлять слабые места в процессе моделирования. Это, в свою очередь, способствует повышению точности и надежности результатов, полученных с использованием симулированных данных, и оптимизации процессов разработки и тестирования информационно-поисковых систем.
Два ключевых аспекта строгой валидации симуляций информационного поиска — это “неразличимость” и “аппроксимация производительности”. Неразличимость относится к способности симулированных запросов быть неотличимыми от реальных пользовательских запросов с точки зрения различных метрик, таких как длина, сложность и тематика. Высокая степень неразличимости указывает на реалистичность симуляции. Аппроксимация производительности оценивает, насколько точно симулированные данные могут предсказать производительность системы информационного поиска (например, точность, полноту, NDCG) при обработке реальных запросов. Точная аппроксимация позволяет использовать симуляции для быстрой и экономичной оценки различных конфигураций и алгоритмов, избегая дорогостоящих экспериментов с реальными пользователями.
Измерение Качества Симуляции: Ключевые Метрики и Наборы Данных
Оценка «неотличимости» (indistinguishability) симулированных запросов от реальных основывается на использовании метрик схожести запросов (query similarity measures). Эти метрики позволяют количественно оценить, насколько симулированные запросы похожи на реальные пользовательские запросы, что является ключевым аспектом валидации симулятора. Наиболее часто используемые метрики включают в себя косинусное сходство, расстояние Левенштейна и Jaccard index, которые применяются к различным аспектам запросов, таким как термины, фразы и синтаксическая структура. Высокие значения этих метрик свидетельствуют о том, что симулированные запросы хорошо отражают характеристики реальных запросов, подтверждая адекватность симуляции.
Оценка приближения производительности поисковой системы требует сопоставления результатов, полученных на реальных запросах, с результатами, полученными на смоделированных запросах. Для этого используются стандартные метрики оценки информационного поиска (IR Performance Metrics), такие как точность (precision), полнота (recall), F-мера и NDCG. Дополнительно анализируется степень перекрытия (SERP Overlap Measures) в списках результатов поисковой выдачи (SERP) для реальных и смоделированных запросов, что позволяет количественно оценить сходство между ними. Высокая степень перекрытия SERP указывает на то, что смоделированные запросы генерируют результаты, сопоставимые с реальными запросами, подтверждая адекватность моделирования.
Для обеспечения надежной и воспроизводимой оценки качества симуляций поисковых запросов необходимо использовать эталонные наборы данных. В частности, набор данных UQV (Understanding Query Variation) предназначен для анализа вариативности запросов, Sim4IA (Simulation for Information Access) — для оценки симулированных поисковых сессий, а DL Seed Queries Dataset — для начального набора запросов, используемых в задачах глубокого обучения. Использование этих наборов данных позволяет стандартизировать процесс оценки, обеспечивая возможность сравнения различных методов симуляции и воспроизведения результатов другими исследователями. Это критически важно для объективной валидации и развития технологий симуляции в области информационного поиска.
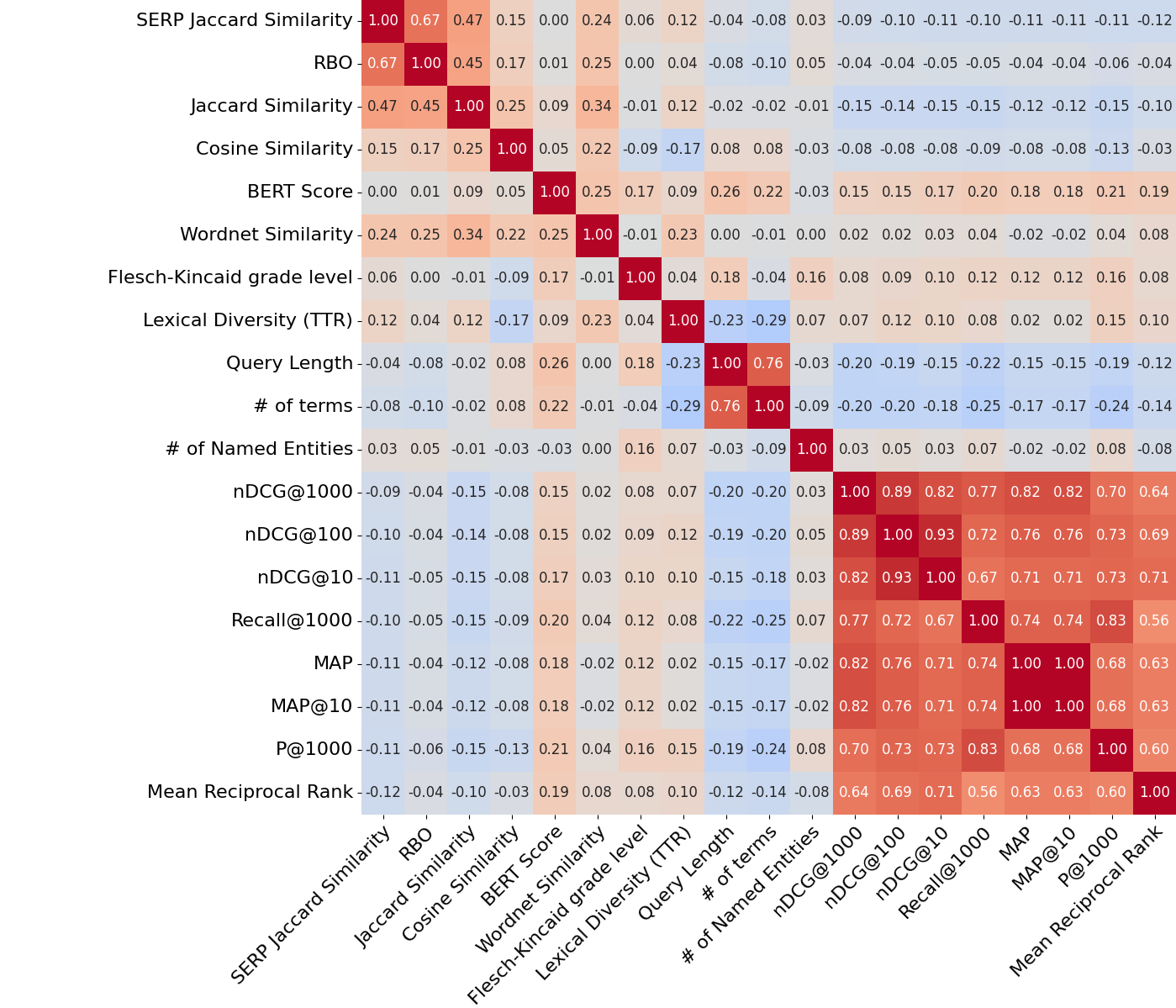
Анализ данных показывает высокую внутреннюю корреляцию между традиционными метриками информационного поиска (IR) — средний коэффициент корреляции Пирсона составляет ρ̄ = 0.77. Это указывает на определенную избыточность при использовании этих метрик для валидации и оценки систем поиска. Высокая корреляция означает, что изменение значения одной метрики с большой вероятностью повлечет за собой аналогичное изменение других метрик, что снижает информативность их совместного использования для всесторонней оценки качества.
Анализ базовых характеристик поисковых запросов, таких как длина, частота слов и сложность синтаксиса, выявил высокую внутреннюю корреляцию ( \rhō = 0.91 ). Это означает, что изменение одного из этих параметров часто предсказывает изменение других, что снижает информативность использования только этих характеристик для валидации симуляций. Следовательно, для получения надежной оценки качества симуляции необходимо применять дополнительные, взаимодополняющие подходы к валидации, учитывающие более широкий спектр факторов и обеспечивающие независимую оценку различных аспектов поведения запросов.
Раскрытие Скрытых Закономерностей Через Статистический Анализ
Для выявления взаимосвязей между различными метриками валидации применяются статистические методы, такие как корреляционный анализ и факторный анализ. Эти техники позволяют установить, какие показатели оказывают наибольшее влияние на качество симуляции. Корреляционный анализ, например, выявляет степень линейной зависимости между переменными, показывая, насколько изменение одной метрики связано с изменением другой. В свою очередь, факторный анализ позволяет выделить основные факторы, определяющие общую дисперсию в наборе метрик, тем самым упрощая понимание ключевых драйверов качества симуляции и помогая сосредоточиться на наиболее важных аспектах при её оптимизации. Такой подход способствует не только более глубокому пониманию валидации, но и разработке более эффективных стратегий улучшения симуляционных моделей.
Исследование характеристик запросов, таких как длина, лексическое разнообразие и уровень сложности по Флешу-Кинкейду, позволяет выявить, какие типы запросов наиболее успешно моделируются. Анализ этих параметров дает возможность определить, насколько реалистичны генерируемые симулятором запросы с точки зрения их структуры и сложности. В частности, запросы с определенной длиной и уровнем лексического разнообразия могут лучше соответствовать реальным пользовательским запросам, что свидетельствует о более качественной симуляции. Определение взаимосвязи между этими характеристиками и успешностью моделирования позволяет оптимизировать процесс генерации запросов и повысить достоверность полученных результатов, а также лучше понимать, какие типы запросов представляют наибольшую сложность для точного воспроизведения.
Применение методов распознавания именованных сущностей (Named Entity Recognition) позволяет оценить способность симулятора генерировать запросы, содержащие реалистичные и правдоподобные именованные сущности — такие как названия организаций, имена людей, географические объекты и даты. Высокая точность распознавания этих сущностей в сгенерированных запросах указывает на то, что симуляция способна воспроизводить естественный язык, характерный для реальных пользовательских поисковых запросов. Это, в свою очередь, существенно повышает валидность результатов, поскольку достоверность симулированных запросов напрямую влияет на надежность и применимость полученных данных для дальнейшего анализа и исследований.
Анализ данных показал высокую корреляцию между различными мерами пересечения результатов поисковой выдачи (SERP overlap), достигающую значения ρ̄ = 0.85. Это подтверждает значимость данных метрик для оценки качества симуляции поисковых запросов. В то же время, умеренная корреляция ( ρ̄ = 0.41 ) между схожестью запросов и пересечением SERP указывает на то, что эти показатели предоставляют взаимодополняющую информацию. Использование обеих групп метрик позволяет более полно и точно оценить, насколько адекватно симулятор воспроизводит реальное поведение пользователей и поисковых систем, обеспечивая более надежные результаты валидации.
Исследование, представленное в данной работе, акцентирует внимание на необходимости валидации методов моделирования поисковых запросов. Авторы предлагают таксономию мер, позволяющих оценить соответствие симуляций реальному поведению пользователей. Этот подход к оценке систем, где любое улучшение со временем устаревает, перекликается с высказыванием Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Подобно тому, как создание точных симуляций позволяет «создать» более предсказуемое будущее поисковых систем, так и валидация этих симуляций является критически важной для обеспечения их долгосрочной эффективности и актуальности, ведь системы стареют, и вопрос лишь в том, делают ли они это достойно.
Что дальше?
Предложенная таксономия валидации симуляций запросов, несомненно, структурирует поле, однако сама структура — лишь временное упорядочение хаоса. Любая метрика, даже тщательно валидированная, отражает лишь фрагмент сложной динамики пользовательского поведения. Попытка «зафиксировать» эту динамику — всё равно что пытаться остановить течение времени, лишь создавая иллюзию контроля. Вопрос не в достижении идеальной валидации, а в осознании её принципиальной невозможности.
Очевидно, что будущие исследования должны сместиться от поиска единой «правильной» метрики к изучению взаимосвязей между различными метриками и их чувствительности к изменениям в пользовательских запросах. Более того, необходимо учитывать контекст: запрос, рожденный в один момент времени, не тождественен запросу, возникшему спустя мгновение. Акцент должен быть сделан на адаптивных системах валидации, способных эволюционировать вместе с меняющимся ландшафтом информационного поиска.
Созданная библиотека инструментов — полезный артефакт, но, подобно любому инструменту, она устареет. Поэтому, истинная ценность этой работы заключается не в её конкретных результатах, а в стимулировании дальнейших исследований, направленных на понимание того, как системы стареют, и как сделать этот процесс более достойным. Ведь время — не метрика, а среда, в которой существуют системы, и лишь медленные изменения способны обеспечить их устойчивость.
Оригинал статьи: https://arxiv.org/pdf/2601.11412.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.