Аналитика и данные
Адаптация моделей к новым данным: квантильная коррекция для нейросетей
Автор: Денис Аветисян
Новый метод позволяет нейронным сетям, как трансформерам, так и сверточным сетям, эффективно адаптироваться к меняющимся данным без переобучения.
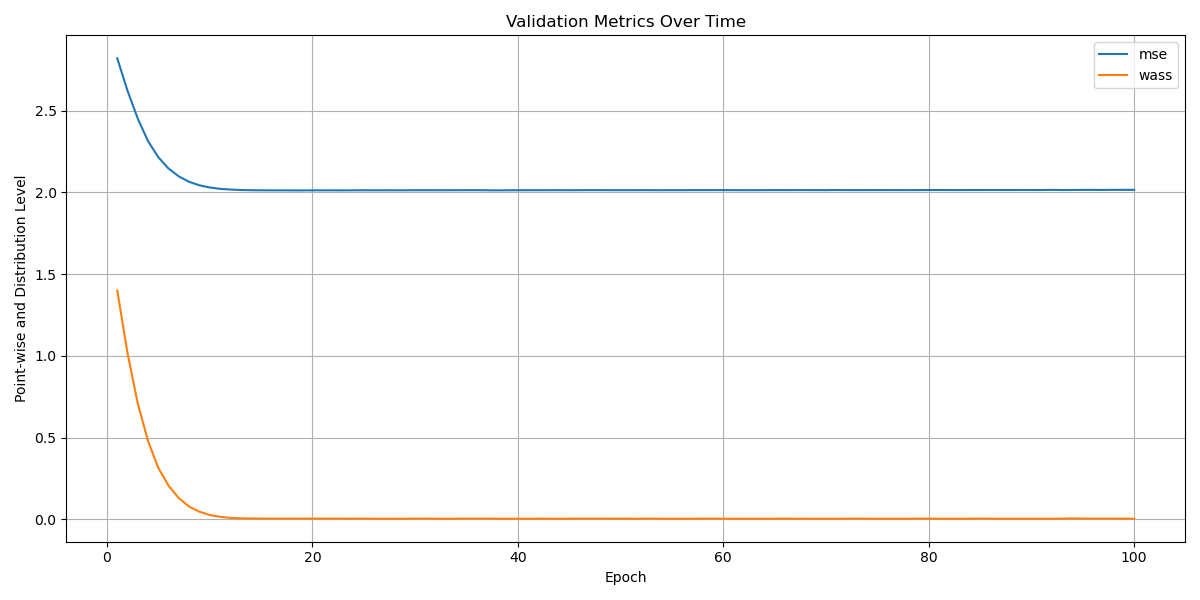
Предлагается архитектурно-независимый подход к адаптации моделей во время работы, основанный на сопоставлении квантилей распределений признаков.
Несмотря на успехи глубокого обучения, обобщение моделей на данные с отличающимся распределением остается сложной задачей. В статье ‘Matching High-Dimensional Geometric Quantiles for Test-Time Adaptation of Transformers and Convolutional Networks Alike’ предложен архитектурно-независимый подход к адаптации к данным во время тестирования, основанный на сопоставлении квантилей геометрических признаков. Предложенный метод позволяет обучать адаптер, корректирующий распределение входных данных, не изменяя параметры классификатора, что обеспечивает устойчивость к сдвигу ковариаты. Возможно ли дальнейшее расширение принципов сопоставления квантилей для решения более широкого круга задач, связанных с адаптацией и обобщением моделей глубокого обучения?
Вызов ковариационного сдвига
Глубокие нейронные сети, особенно архитектуры, такие как ResNet, демонстрируют впечатляющую производительность в контролируемых лабораторных условиях, однако их надёжность существенно снижается при столкновении с изменением распределения входных данных — так называемым ковариатным сдвигом. Этот сдвиг возникает из-за естественных вариаций в реальном мире, например, из-за постепенной деградации сенсоров, изменений в освещении или других факторов, приводящих к несоответствию между данными, на которых обучалась модель, и данными, которые она получает в процессе эксплуатации. В результате, даже незначительные отклонения от изначальных условий могут приводить к резкому падению точности и, как следствие, к ошибочным решениям, что критически важно учитывать при разработке систем искусственного интеллекта, предназначенных для работы в динамичной и непредсказуемой среде.
Смещение распределения данных, возникающее из-за реальных изменений, таких как деградация сенсоров или колебания условий окружающей среды, представляет собой серьёзную проблему для надёжности систем машинного обучения. Изначально обученная модель, прекрасно работающая с данными, полученными в контролируемой среде, может демонстрировать значительное снижение точности при обработке данных, собранных в иных условиях. Например, камера, подверженная износу, может выдавать изображения с отличающимися оттенками и контрастностью, что приведет к ошибочной классификации. Подобный разрыв между распределением данных, использованных при обучении, и распределением данных, поступающих в реальном времени, приводит к несоответствию и снижает общую эффективность системы. Поэтому понимание и смягчение последствий этого смещения является критически важным для обеспечения стабильной работы искусственного интеллекта в динамичной среде.
Для оценки устойчивости моделей глубокого обучения к изменению распределения данных, активно используются специализированные бенчмарки, такие как MNIST-C, CIFAR10-C и ImageNet-C. Эти наборы данных искусственно вводят различные типы искажений — шум, размытие, изменения освещения и контраста — в исходные изображения, имитируя тем самым реальные условия эксплуатации, где сенсоры со временем деградируют или меняется окружающая среда. Использование этих бенчмарков позволяет количественно оценить степень уязвимости моделей к ковариатному сдвигу и служит мощным инструментом для разработки и тестирования более надёжных и устойчивых алгоритмов, способных сохранять высокую производительность даже при значительном расхождении между тренировочными и тестовыми данными. Именно благодаря этим эталонным наборам данных стало возможным отслеживать прогресс в области робастного машинного обучения и стимулировать создание моделей, пригодных для развертывания в динамичных и непредсказуемых реальных условиях.
Разработка надёжных систем искусственного интеллекта, способных функционировать в реальных условиях, неразрывно связана с преодолением проблемы смещения распределений данных. Неизбежные изменения в окружающей среде, деградация сенсоров и другие факторы приводят к расхождению между данными, на которых обучалась модель, и теми, с которыми она сталкивается в процессе эксплуатации. Пренебрежение этой проблемой может привести к резкому снижению точности и надёжности алгоритмов, что особенно критично для приложений в автономных транспортных средствах, медицине и других областях, где ошибки могут иметь серьёзные последствия. Поэтому усилия, направленные на создание моделей, устойчивых к смещению распределений, являются ключевыми для успешного внедрения искусственного интеллекта в динамично меняющийся мир.
Адаптация во время тестирования: Мост к устойчивости
Адаптация во время тестирования (Test-Time Adaptation, TTA) представляет собой перспективный подход к повышению устойчивости моделей машинного обучения к изменениям в распределении тестовых данных. В отличие от традиционных методов, требующих наличия размеченных данных для переобучения, TTA позволяет модели динамически корректировать свои параметры непосредственно во время инференса, используя только неразмеченные тестовые примеры. Это особенно актуально в сценариях, где получение размеченных данных является дорогостоящим или невозможным, и позволяет модели адаптироваться к специфическим особенностям входных данных без необходимости в дополнительном обучении на размеченной выборке.
Методы BNStats и TENT используют динамическую перекалибровку параметров модели, опираясь на статистику пакетной нормализации (Batch Normalization) или энтропию предсказаний. BNStats адаптирует параметры пакетной нормализации, используя статистику текущего тестового пакета данных для снижения расхождения между тренировочным и тестовым распределениями. TENT (Test-Time Entropy Minimization) минимизирует энтропию предсказаний модели на тестовых данных, что способствует повышению уверенности и точности предсказаний в условиях сдвига распределения. Оба подхода позволяют модели адаптироваться к особенностям тестовых данных без использования размеченных примеров, что делает их эффективными решениями для задач, где получение размеченных данных затруднено или невозможно.
Для повышения устойчивости моделей к смещению распределений тестовых данных, такие подходы, как CoTTA, EATA и SoTTA, используют различные стратегии оптимизации. CoTTA (Contextual Test-Time Adaptation) применяет аугментацию данных для расширения представленности тестовых примеров. EATA (Entropy Adaptive Test-Time Adaptation) использует регуляризацию на основе информации о предсказаниях, стремясь минимизировать энтропию и повысить уверенность модели. SoTTA (Self-Supervised Test-Time Adaptation) использует оптимизацию на основе возмущений входных данных для улучшения обобщающей способности модели в условиях смещения распределений.
Методы RoTTA (Robust Test-Time Adaptation), SAR (Self-Adaptive Refinement) и MedBN (Median Batch Normalization) предлагают различные стратегии для уточнения адаптации модели во время тестирования. RoTTA использует робастные оценки статистики для снижения влияния выбросов в тестовых данных. SAR динамически корректирует параметры модели на основе оценки неопределенности предсказаний, что позволяет более эффективно адаптироваться к изменениям в распределении данных. MedBN применяет медианную нормализацию пакетов, что делает процесс адаптации менее чувствительным к шумам и выбросам в тестовом наборе, повышая общую производительность модели при смещении распределений.
Визуальные трансформаторы: Новая архитектурная основа
Визуальные трансформаторы (ViT) отличаются от традиционных сверточных нейронных сетей (CNN) принципом работы с изображениями. CNN обрабатывают изображения локально, применяя сверточные фильтры к небольшим участкам. ViT, напротив, используют механизм самовнимания (self-attention) для установления связей между всеми участками изображения, что позволяет учитывать глобальный контекст и долгосрочные зависимости. Вместо последовательной обработки локальных признаков, ViT разбивает изображение на последовательность патчей, которые рассматриваются как “токены”, аналогичные словам в обработке естественного языка. Само-внимание вычисляет взаимосвязь между этими патчами, определяя, какие части изображения наиболее важны для понимания общей картины. Это позволяет ViT эффективно моделировать отношения между удаленными участками изображения, что часто является проблемой для CNN.
Стандартные Vision Transformers (ViT) характеризуются высокой вычислительной сложностью, обусловленной квадратичной зависимостью потребляемых ресурсов от количества входных токенов (патчей изображения). Для снижения этих затрат были разработаны облегченные варианты, такие как CompactVisionTransformer и ViT-Lite. CompactVisionTransformer использует методы уменьшения размерности и оптимизации структуры внимания, а ViT-Lite применяет квантизацию весов и другие техники сжатия модели, позволяя снизить вычислительную нагрузку и объем памяти без значительной потери точности. Эти облегченные архитектуры делают ViT более применимыми для задач с ограниченными ресурсами, например, на мобильных устройствах или в системах реального времени.
Архитектура CompactConvolutionTransformer (CCT) представляет собой гибридный подход, объединяющий преимущества сверточных нейронных сетей (CNN) и трансформеров. CCT использует сверточные слои для извлечения локальных признаков и снижения вычислительной сложности, а затем применяет механизмы самовнимания (self-attention) для моделирования глобальных зависимостей между признаками. Такой подход позволяет уменьшить потребность в больших объемах данных для обучения по сравнению со стандартными Vision Transformers (ViT), сохраняя при этом способность к захвату долгосрочных связей в изображении. CCT обычно включает в себя сверточные блоки в качестве «патч-эмбеддинга» перед подачей данных в слои трансформера, что позволяет снизить размер входной последовательности и повысить эффективность обработки.
Интеграция геометрических квантилей и функции потерь на основе квантилей (Quantile Loss) с архитектурой Vision Transformer (ViT) позволяет получить более устойчивое и информативное представление данных изображений. В отличие от традиционных подходов, фокусирующихся на средних значениях, использование квантилей позволяет модели учитывать распределение значений пикселей, что особенно важно для изображений с неравномерным освещением или шумом. Quantile Loss минимизирует ошибку между предсказанными и фактическими квантилями, что приводит к улучшению робастности модели к выбросам и повышению точности в сложных условиях. Данный подход позволяет ViT более эффективно извлекать признаки, важные для решения задач компьютерного зрения, таких как обнаружение объектов и сегментация изображений.
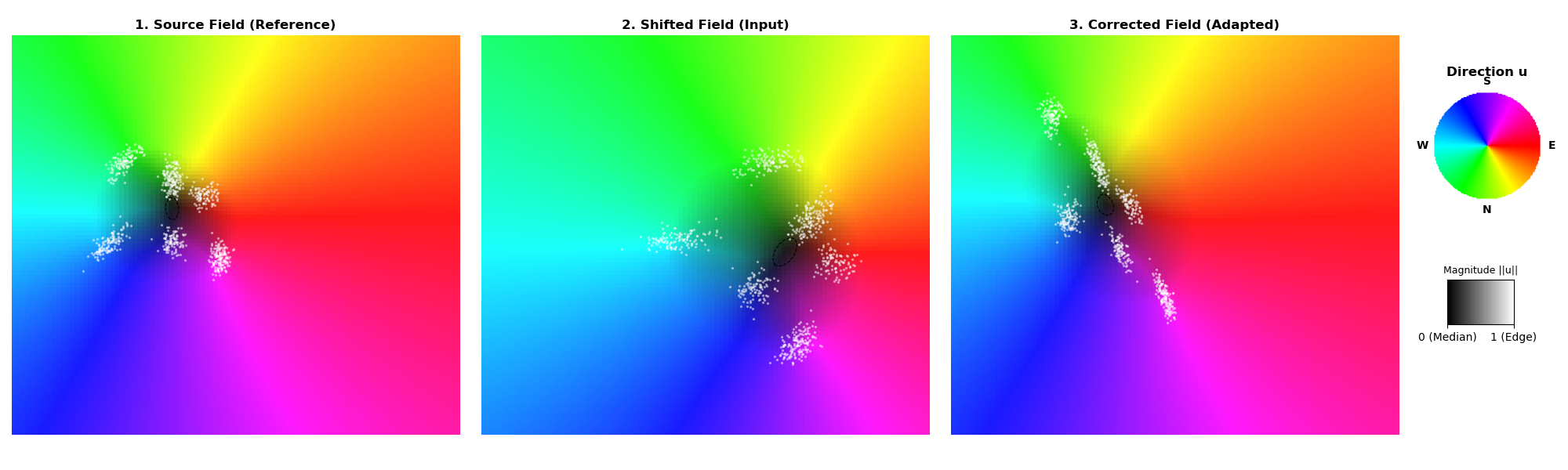
Усиление робастности с помощью передовых техник
Сочетание методов адаптации во время тестирования с передовыми архитектурами, такими как Vision Transformers, позволяет создавать системы искусственного интеллекта, значительно более устойчивые к смещению ковариаты. Данный подход особенно важен, поскольку реальные данные часто отличаются от тех, на которых обучалась модель, что приводит к снижению производительности. Vision Transformers, благодаря своей способности эффективно обрабатывать глобальный контекст изображения, в сочетании с адаптацией во время тестирования, позволяют модели приспосабливаться к новым, ранее не встречавшимся условиям, сохраняя высокую точность даже при значительных изменениях входных данных. Это позволяет создавать более надёжные и универсальные системы, способные успешно функционировать в различных, непредсказуемых средах.
Для повышения эффективности современных моделей машинного обучения, особенно при адаптации к изменяющимся условиям, активно применяется концепция MemoryBank. Суть заключается в сохранении промежуточных результатов вычислений, что позволяет избежать повторных, ресурсоемких операций. Вместо того, чтобы каждый раз заново вычислять необходимые данные, модель обращается к MemoryBank, извлекая уже готовые результаты. Это значительно сокращает время обработки и снижает потребность в вычислительных ресурсах, особенно при работе с большими объемами данных и сложными архитектурами, такими как Vision Transformers. Использование MemoryBank позволяет модели более эффективно использовать накопленные знания и быстро адаптироваться к новым ситуациям, что особенно важно в условиях ограниченных ресурсов или необходимости обработки данных в режиме реального времени.
Включение расстояния Вассерштейна в процесс обучения позволяет более эффективно согласовать представления, формируемые моделью, с реальным распределением данных. Этот подход, в отличие от традиционных метрик, таких как евклидово расстояние, учитывает структуру вероятностных распределений, что особенно важно при наличии ковариатного сдвига. Использование расстояния Вассерштейна способствует созданию более устойчивых и обобщающих моделей, поскольку оно минимизирует расхождения между предсказанными и истинными распределениями данных, даже при изменениях входных данных. В результате, модель лучше адаптируется к новым, ранее не встречавшимся условиям, повышая свою надёжность и точность в реальных сценариях использования. Данный метод позволяет не просто классифицировать объекты, но и понимать лежащие в основе закономерности в данных, что является ключевым для создания интеллектуальных систем.
В ходе экспериментов предложенный подход продемонстрировал значительное повышение точности на датасете CIFAR100C. При использовании архитектуры ResNet18, модель достигла показателя в 65.0%, что превосходит результат SoTTA, составивший 60.5% при той же архитектуре. Более того, при использовании CCT, наблюдается прирост точности в 4.5% по сравнению с SoTTA. Данные результаты подтверждают эффективность предложенных техник в повышении устойчивости моделей к изменениям в данных и демонстрируют потенциал для применения в задачах, требующих высокой надёжности и обобщающей способности.
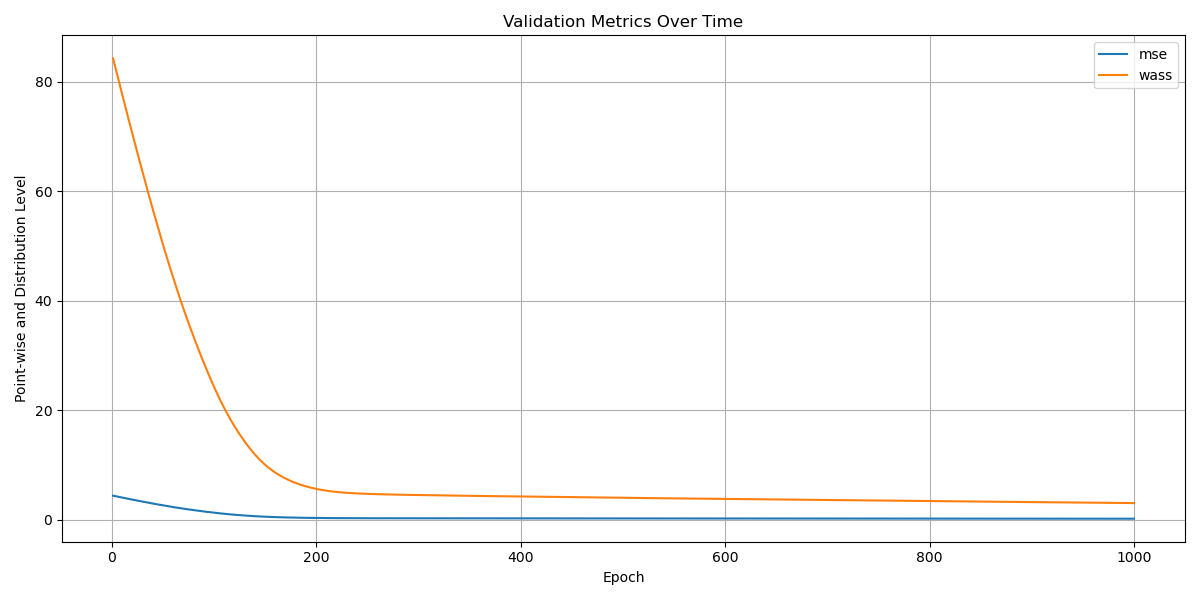
Исследование демонстрирует элегантность подхода к адаптации моделей во время тестирования, фокусируясь на сопоставлении квантилей признаков. Этот метод, не зависящий от архитектуры сети, позволяет моделям эффективно обобщать данные, сталкиваясь с изменениями в распределении входных данных. Подобно тому, как тщательно продуманная структура обеспечивает стабильность системы, данная работа акцентирует внимание на важности декодера, который корректирует признаки, обеспечивая более точную классификацию. Грейс Хоппер однажды заметила: «Лучший способ предсказать будущее — это создать его». Эта фраза отражает суть исследования — не просто адаптироваться к новым данным, но и активно формировать способность модели к обобщению, предвосхищая проблемы, связанные с изменением распределений.
Что дальше?
Предложенный подход к адаптации моделей в условиях меняющихся распределений, основанный на сопоставлении квантилей, демонстрирует элегантность простоты. Однако, как часто бывает, решение одной проблемы неизбежно обнажает другие. Чрезмерная уверенность в универсальности декодера, не зависящего от архитектуры, представляется несколько наивной. Подобно механическому устройству, каждая деталь которого взаимосвязана, глубинная сеть — сложный организм, и игнорирование специфики конкретной модели может привести к неоптимальным результатам.
Перспективным направлением представляется исследование взаимодействия между декодером и классификатором. Вместо абсолютного разделения, возможно, более эффективным окажется совместная оптимизация, позволяющая декодеру учитывать особенности классификатора и, наоборот. Более того, вопрос о стабильности декодера при экстремальных сдвигах ковариаты остается открытым. Необходимо изучить, насколько хорошо предложенный подход справляется с ситуациями, когда тестовое распределение значительно отличается от обучающего.
В конечном итоге, ценность предложенного подхода заключается не столько в достижении максимальной точности в конкретном сценарии, сколько в предоставлении концептуально простой и гибкой платформы для дальнейших исследований. Подобно строителю, возводящему фундамент, данная работа закладывает основу для создания более надежных и адаптивных систем глубокого обучения, способных успешно функционировать в постоянно меняющемся мире.
Оригинал статьи: https://arxiv.org/pdf/2601.11022.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.