Статьи QuantRise
Искусственный интеллект на чипе: аппаратная суммаризация текстов
Автор: Денис Аветисян
- Когда Элегантность Встречает Реальность: Вызовы Масштабирования Автоматического Реферирования
- Математика Реферирования: Превращаем Текст в Оптимизационную Задачу
- Аппаратное Ускорение: От Изинговских Машин к Реальным Решениям
- Результаты и Эффективность: Когда Оптимизация Имеет Значение
- За Горизонтом: К Масштабируемому Автоматическому Реферированию Будущего
- Что дальше?
Новый подход к извлечению ключевой информации из текста использует низкоэнергетический CMOS Ising-процессор для значительного ускорения и снижения энергопотребления.
Исследование демонстрирует аппаратную реализацию алгоритма суммаризации, основанную на решении задачи квадратичной целочисленной оптимизации на специализированном оборудовании.
Современные методы извлечения ключевой информации из текста, несмотря на высокую точность, часто требуют значительных вычислительных ресурсов и энергопотребления. В данной работе, посвященной ‘Extractive summarization on a CMOS Ising machine’, исследуется возможность реализации алгоритмов извлечения информации на базе низкоэнергетических CMOS Ising-машин. Показано, что разработанный аппаратный подход позволяет добиться ускорения в 3-4.5 раза и снижения энергопотребления на два-три порядка величины по сравнению с традиционными программными методами, сохраняя при этом сопоставимое качество итоговой сводки. Может ли подобный подход открыть новые возможности для развертывания систем обработки естественного языка на периферийных устройствах с ограниченными ресурсами?
Когда Элегантность Встречает Реальность: Вызовы Масштабирования Автоматического Реферирования
Традиционные методы извлечения информации для автоматического реферирования сталкиваются с серьезными трудностями при обработке длинных текстов из-за экспоненциального роста вычислительной сложности. По мере увеличения объема документа, количество возможных комбинаций предложений, которые необходимо оценить для выбора наиболее репрезентативных, растет в геометрической прогрессии. Это приводит к значительному увеличению времени обработки и потреблению ресурсов, делая применение стандартных алгоритмов непрактичным для больших объемов текста. Таким образом, эффективность и масштабируемость извлечения информации становятся критическими проблемами, требующими разработки новых подходов, способных справляться с растущими объемами текстовых данных.
Процесс отбора наиболее репрезентативных предложений в задачах извлечения информации представляет собой сложную вычислительную задачу, требующую тонкого баланса между релевантностью и избыточностью. Выбор предложений, отражающих ключевые аспекты документа, должен учитывать не только их соответствие общей теме, но и необходимость избежания повторений. Каждое предложение оценивается по множеству критериев, включая его информативность, позицию в тексте и семантическую связь с другими предложениями. При этом, с ростом объема документа, количество возможных комбинаций предложений экспоненциально увеличивается, превращая задачу в проблему комбинаторной оптимизации, требующую значительных вычислительных ресурсов и сложных алгоритмов для эффективного решения. По сути, система должна уметь отличать действительно важную информацию от незначительных деталей, а также определять, какие предложения дополняют друг друга, а какие просто дублируют уже представленный контент.
Суть проблемы масштабируемости извлечения информации заключается в том, что выбор наиболее репрезентативных предложений из длинного текста превращается в задачу комбинаторной оптимизации. По мере увеличения длины документа количество возможных комбинаций предложений экспоненциально возрастает, что делает полный перебор вариантов невозможным даже при использовании современных вычислительных ресурсов. Фактически, для документа, состоящего из n предложений, существует 2^n возможных подмножеств, которые потенциально могут составить краткое изложение. Это означает, что алгоритмы, эффективно работающие с короткими текстами, быстро становятся непрактичными при обработке объемных документов, требуя разработки более эффективных и масштабируемых подходов к выбору предложений.
Математика Реферирования: Превращаем Текст в Оптимизационную Задачу
В основе подхода к извлечению ключевых фраз из текста лежит формулировка задачи как оптимизационной. Целевая функция f(S) предназначена для максимизации релевантности выбранного подмножества предложений S исходному документу и минимизации избыточности информации внутри этого подмножества. Релевантность обычно оценивается на основе статистических метрик, таких как TF-IDF или векторные представления предложений, в то время как избыточность определяется через меру сходства между выбранными предложениями, например, косинусное расстояние между их векторными представлениями. Формально, целевая функция может быть представлена как взвешенная сумма этих двух компонентов: f(S) = \alpha \cdot Relevance(S) - \beta \cdot Redundancy(S), где α и β — весовые коэффициенты, определяющие важность релевантности и минимизации избыточности соответственно.
Целочисленное линейное программирование (ЦЛП) предоставляет естественный способ моделирования задачи извлечения информации для суммаризации, где каждая фраза представляется бинарной переменной, указывающей на её включение или исключение из результирующего резюме. Формулировка включает в себя целевую функцию, максимизирующую релевантность и минимизирующую избыточность, а также ограничения, обеспечивающие когерентность и соблюдение заданной длины резюме. Однако, сложность ЦЛП растет экспоненциально с увеличением количества предложений в документе, что делает его вычислительно непрактичным для обработки больших объемов текста. В частности, количество переменных и ограничений пропорционально O(n^2), где n — количество предложений, что приводит к значительному увеличению времени вычислений и потребляемой памяти.
Преобразование задачи экстрактивной суммаризации к форме Quadratic Unconstrained Binary Optimization (QUBO) позволяет использовать специализированные решатели, оптимизированные для работы с данной структурой задач. В отличие от Integer Linear Programming (ILP), требующего решения целочисленных линейных уравнений, QUBO представляет собой задачу нелинейной оптимизации с бинарными переменными, определяемыми как 0 или 1. Это позволяет использовать алгоритмы, такие как Simulated Annealing или Quantum Annealing, которые более эффективно справляются с задачами QUBO, особенно для больших объемов текста, где ILP становится вычислительно непрактичным. Математически, задача QUBO определяется как минимизация или максимизация квадратичной функции от бинарных переменных, вида \sum_{i} Q_{ii}x_i + \sum_{i,j} Q_{ij}x_ix_j , где x_i — бинарные переменные, а Q — матрица коэффициентов.
Аппаратное Ускорение: От Изинговских Машин к Реальным Решениям
Формулировка QUBO (Quadratic Unconstrained Binary Optimization) имеет естественное соответствие модели Изинга, широко используемому в комбинаторной оптимизации. Модель Изинга описывает систему взаимодействующих спинов, принимающих значения +1 или -1, а энергия системы определяется взаимодействием между ними и внешними полями. Переменные в задаче QUBO напрямую соответствуют спинам в модели Изинга, а квадратичные члены в функции QUBO отображаются на взаимодействия между спинами. Это соответствие позволяет использовать аппаратные реализации модели Изинга, такие как специализированные процессоры, для эффективного решения задач QUBO, изначально сформулированных в другой, но эквивалентной форме. E = \sum_{i} h_i \sigma_i + \sum_{i,j} J_{ij} \sigma_i \sigma_j, где \sigma_i — спин, h_i — внешнее поле, а J_{ij} — взаимодействие между спинами i и j.
Реализация предложенного подхода была осуществлена с использованием CMOS-основанного решателя Изинга, COBI Solver. Ключевой особенностью COBI Solver является его полносвязная архитектура, обеспечивающая возможность одновременного взаимодействия между всеми вычислительными элементами. Это позволяет эффективно решать задачи, требующие оценки множества комбинаций, без ограничений, связанных с локальными связями, характерными для других аппаратных решений. Полносвязность архитектуры COBI Solver особенно важна для задач оптимизации, где корреляции между переменными могут быть сложными и нелокальными.
Использование Ising-машин и CMOS-решателей позволяет осуществлять параллельный поиск решения в пространстве возможных вариантов. В отличие от последовательных алгоритмов, применяемых в традиционных методах, данная архитектура обеспечивает одновременную оценку множества состояний, что потенциально ведет к значительному ускорению процесса оптимизации. Эффективность параллельного подхода особенно заметна при решении сложных комбинаторных задач, где объем вычислений экспоненциально растет с увеличением размера задачи. Возможность одновременной обработки данных снижает общее время, необходимое для нахождения оптимального или близкого к оптимальному решения.
Результаты и Эффективность: Когда Оптимизация Имеет Значение
Экспериментальные исследования показали, что подход, основанный на QUBO-Ising решателе, демонстрирует сопоставимое с другими методами качество автоматического реферирования текстов. Данный подход позволяет получать краткие и информативные выжимки из исходного материала, не уступая по эффективности традиционным алгоритмам. Анализ полученных результатов указывает на способность QUBO-Ising решателя эффективно выявлять наиболее важные фрагменты текста и формировать на их основе связные и логичные резюме, что подтверждается сравнительными оценками с результатами, полученными с использованием альтернативных методов обработки естественного языка.
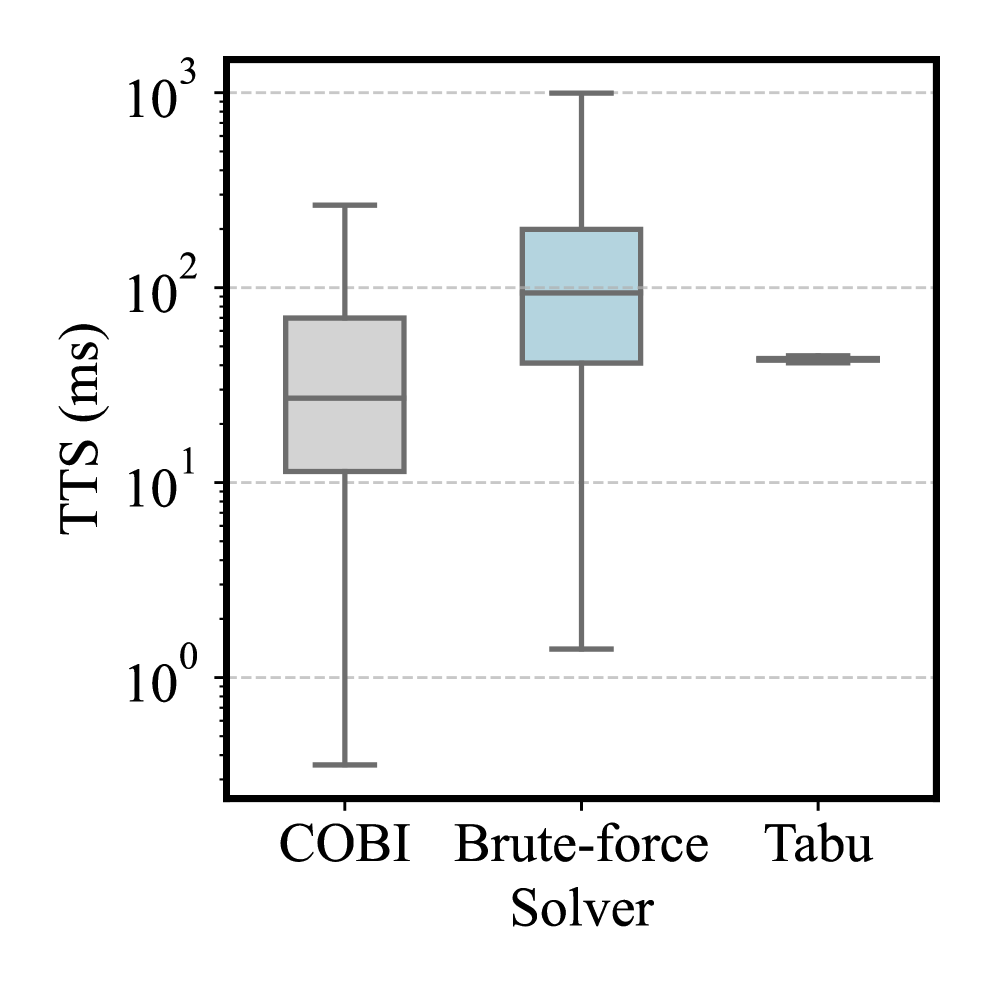
В ходе экспериментов было зафиксировано существенное сокращение времени, необходимого для получения решения, при использовании нового подхода по сравнению с традиционными методами, такими как поиск с запретами (Tabu Search). Наблюдается ускорение в 3-4,5 раза, что позволяет значительно повысить эффективность обработки данных. Это достигается благодаря оптимизации алгоритма и более рациональному использованию вычислительных ресурсов, что особенно важно при работе с большими объемами информации и в задачах, требующих оперативного получения результата. Более быстрое время решения открывает возможности для применения в реальном времени и в интерактивных системах, где важна мгновенная реакция на запросы.
В ходе экспериментов продемонстрировано значительное ускорение процесса решения задач по сравнению с традиционными методами. На тестовых примерах, состоящих из 20 предложений, время решения составило 16,59 миллисекунд, что на 3,6 миллисекунды быстрее, чем у алгоритма Tabu Search, потребовавшего 20,19 миллисекунд. Аналогично, при увеличении размера тестового набора до 50 предложений, достигнутое время решения составило 21,62 миллисекунды против 24,56 миллисекунд, затраченных Tabu Search. Полученные результаты свидетельствуют о существенном повышении эффективности предложенного подхода в задачах, требующих быстрого получения решения.
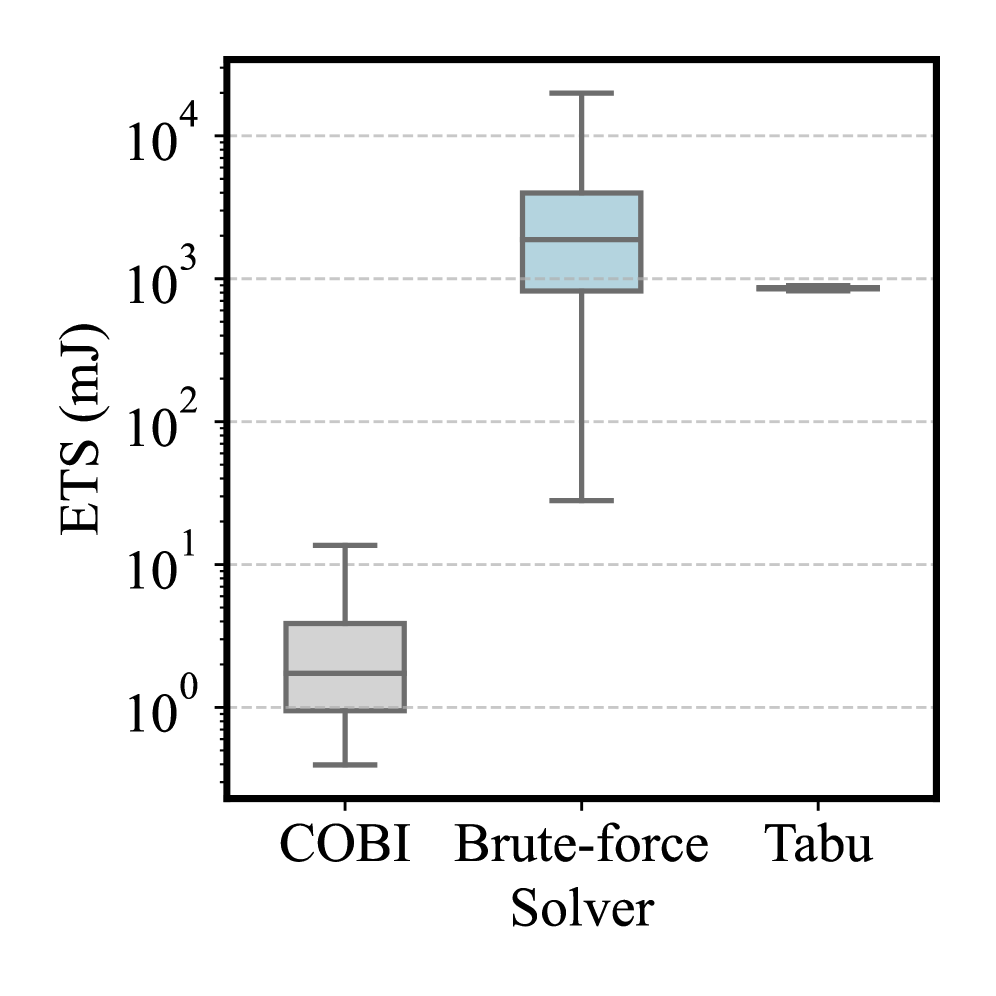
Оптимизация энергопотребления стала ключевым аспектом разработки эффективных алгоритмов. Применение методов стохастической округлизации и нормализации позволило значительно снизить показатель «Энергия на решение» — метрику, характеризующую затраты энергии на получение результата. В ходе исследований было зафиксировано уменьшение энергопотребления на два-три порядка величины по сравнению с традиционными CPU-ориентированными подходами. Это означает, что предложенная методика не только обеспечивает сопоставимое качество обработки данных, но и позволяет существенно снизить эксплуатационные расходы и повысить экологичность вычислений, открывая перспективы для применения в ресурсоограниченных средах и масштабных системах обработки информации.
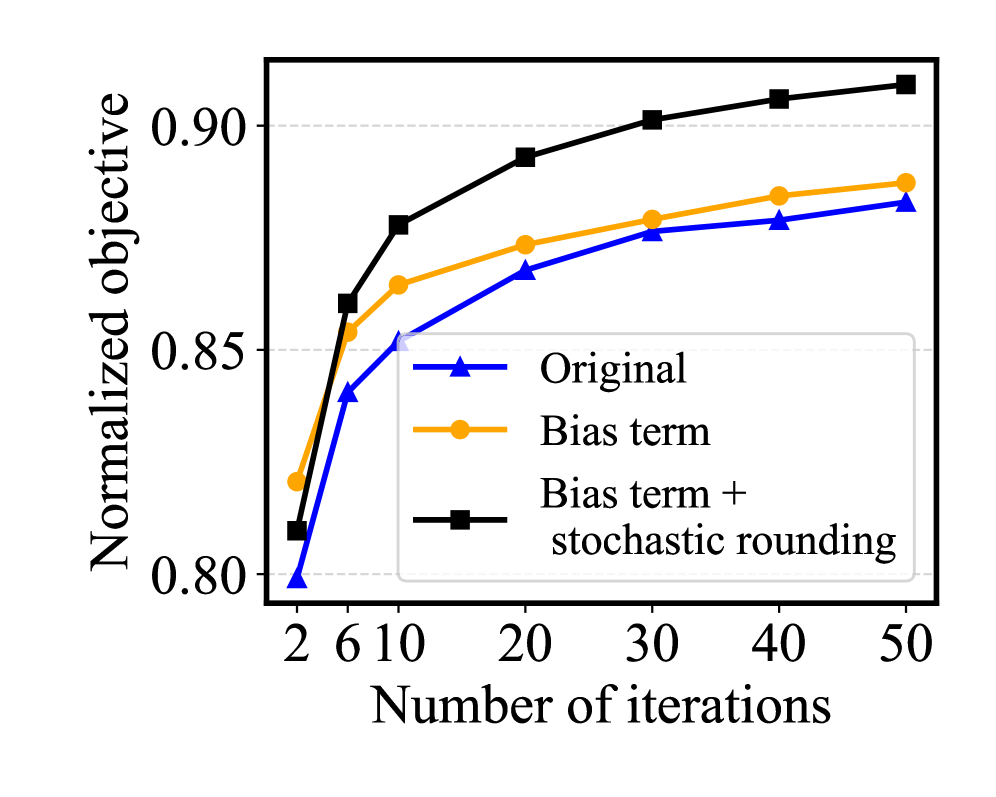
За Горизонтом: К Масштабируемому Автоматическому Реферированию Будущего
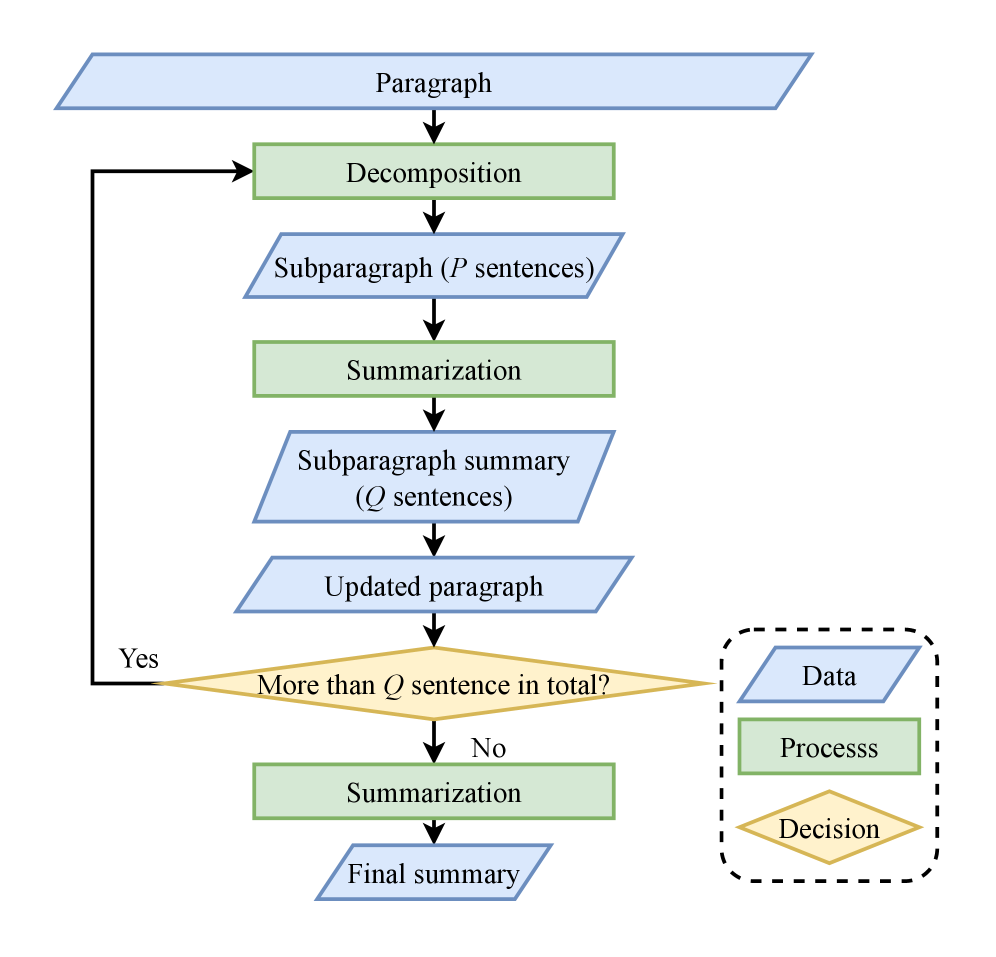
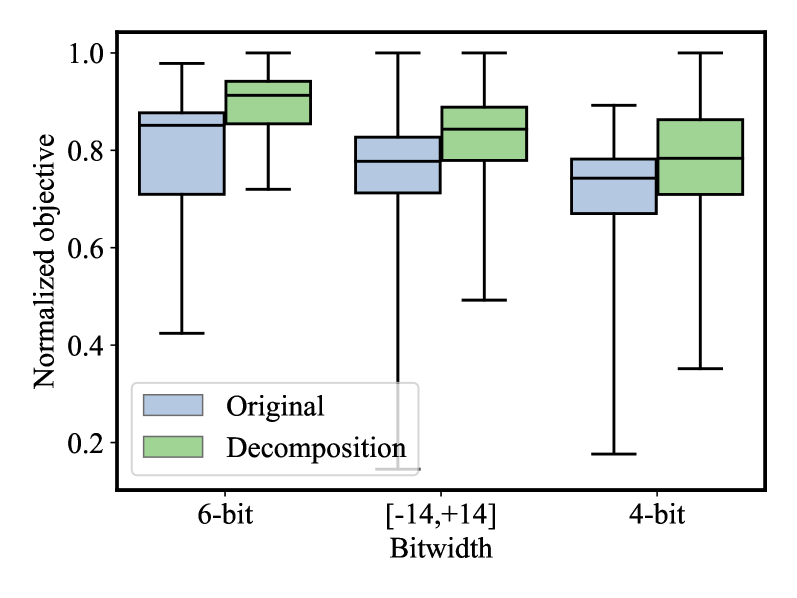
Стратегия декомпозиции представляет собой эффективный подход к масштабированию задач автоматического реферирования больших документов. Вместо обработки всего текста целиком, данный метод предполагает его разделение на более мелкие, логически связанные фрагменты. Такой подход значительно снижает вычислительную сложность и требования к памяти, позволяя обрабатывать документы, которые ранее были недоступны из-за их размера. Разделение позволяет параллельно обрабатывать отдельные части, что дополнительно ускоряет процесс создания реферата. В результате, достигается не только повышение производительности, но и возможность работы с документами, содержащими миллионы слов, без существенных ограничений по ресурсам.
Исследования направлены на изучение возможностей квантовых алгоритмов, в частности, алгоритма квантовой аппроксимации оптимизации (QAOA), для значительного повышения эффективности задач суммирования. Традиционные алгоритмы сталкиваются с экспоненциальным ростом вычислительных затрат при увеличении объема обрабатываемого текста. QAOA, используя принципы квантовой механики, потенциально способен находить оптимальные решения для сложных комбинаторных задач, лежащих в основе суммирования, гораздо быстрее. Данный подход позволяет исследовать возможности решения задач, непосильных для классических алгоритмов, и открывает новые перспективы в обработке больших объемов текстовой информации, где требуется выделение наиболее значимых фрагментов.
В дальнейшем планируется объединить разработанные стратегии декомпозиции и перспективные квантовые алгоритмы, такие как Quantum Approximate Optimization Algorithm, для решения задач автоматического реферирования, характеризующихся беспрецедентной сложностью и объемом обрабатываемых данных. Эта интеграция позволит не только повысить эффективность и масштабируемость существующих методов, но и открыть возможности для анализа и обобщения текстов, которые ранее оказывались недоступны из-за вычислительных ограничений. Особое внимание будет уделено адаптации этих подходов к различным типам текстов, включая научные статьи, юридические документы и большие объемы новостных лент, с целью создания интеллектуальных систем, способных извлекать наиболее важную информацию и представлять ее в сжатой и понятной форме.
Исследование демонстрирует, что даже элегантные математические модели, такие как Ising Machine, неизбежно сталкиваются с суровой реальностью аппаратной реализации. Авторы предлагают подход к экстрактивной суммаризации, оптимизированный для CMOS Ising Machine, стремясь к снижению энергопотребления и повышению скорости. Однако, как показывает опыт, любое «аппаратное ускорение» — это лишь перенос вычислительной нагрузки из программного обеспечения в кремний, где она приобретает новые, часто неочевидные формы. Как однажды заметил Джон Маккарти: «Всякий раз, когда вы пытаетесь сделать что-то полезное, кто-нибудь всегда пытается сделать это по-другому.» Эта фраза как нельзя лучше отражает суть происходящего: стремление к оптимизации неизбежно порождает новые компромиссы и альтернативные решения, а «революционные» технологии быстро превращаются в технический долг. В данном случае, экстрактивная суммаризация — лишь очередной пример того, как сложные алгоритмы упрощаются до примитивных операций, чтобы вписаться в рамки аппаратных ограничений.
Что дальше?
Представленная работа демонстрирует, казалось бы, неизбежный путь: перенос алгоритмов, элегантно работающих на бумаге, в кремний. Ускорение и снижение энергопотребления — это, безусловно, приятные бонусы, но история показывает, что каждый «прорыв» порождает новую волну проблем. Уже сейчас можно предвидеть, что масштабирование этой системы столкнётся с ограничениями, связанными не только с физическими размерами чипа, но и с необходимостью эффективной обработки всё возрастающих объёмов данных. Иначе говоря, «бесконечная масштабируемость» окажется знакомым эхом из 2012-го.
Более того, акцент на экстрактивной суммаризации, хоть и является логичным первым шагом, неизбежно натолкнётся на стену качественной генерации текста. Искусственный интеллект, стремящийся к «пониманию» текста, а не просто к выделению ключевых фраз, потребует принципиально иных архитектур. А это, в свою очередь, означает, что текущая реализация, даже если будет доведена до совершенства, станет лишь очередным элементом в постоянно меняющемся ландшафте аппаратного обеспечения.
В конечном счёте, стоит помнить, что зелёные тесты говорят лишь об одном — тесты ничего не проверяют. Настоящий вызов заключается не в скорости вычислений, а в способности системы справляться с реальными, непредсказуемыми данными. И в этом смысле, предстоит ещё многое сделать, прежде чем «железо» действительно сможет «думать».
Оригинал статьи: https://arxiv.org/pdf/2601.11491.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.