Статьи QuantRise
Автономный поисковик научных статей: новый подход
Автор: Денис Аветисян
Исследователи представили PaperScout — систему, способную самостоятельно находить релевантные научные публикации, используя методы обучения с подкреплением.
PaperScout использует оптимизацию последовательной политики (PSPO) для адаптивного поиска и извлечения научных статей, повышая эффективность академических исследований.
Несмотря на фундаментальную важность поиска научной литературы, существующие подходы часто опираются на жесткие, заранее заданные алгоритмы, неспособные эффективно решать сложные поисковые запросы. В данной работе, ‘PaperScout: An Autonomous Agent for Academic Paper Search with Process-Aware Sequence-Level Policy Optimization’, представлен автономный агент, рассматривающий поиск статей как последовательный процесс принятия решений. Ключевым нововведением является метод PSPO — оптимизация политики на уровне последовательностей, учитывающий динамику взаимодействия агента с внешней средой, что позволяет значительно превзойти традиционные и основанные на обучении с подкреплением подходы в задачах поиска релевантной научной литературы. Какие перспективы открывает адаптивная агентурная система для автоматизации научных исследований и анализа больших объемов информации?
За гранью Ключевых Слов: Ограничения Традиционного Поиска
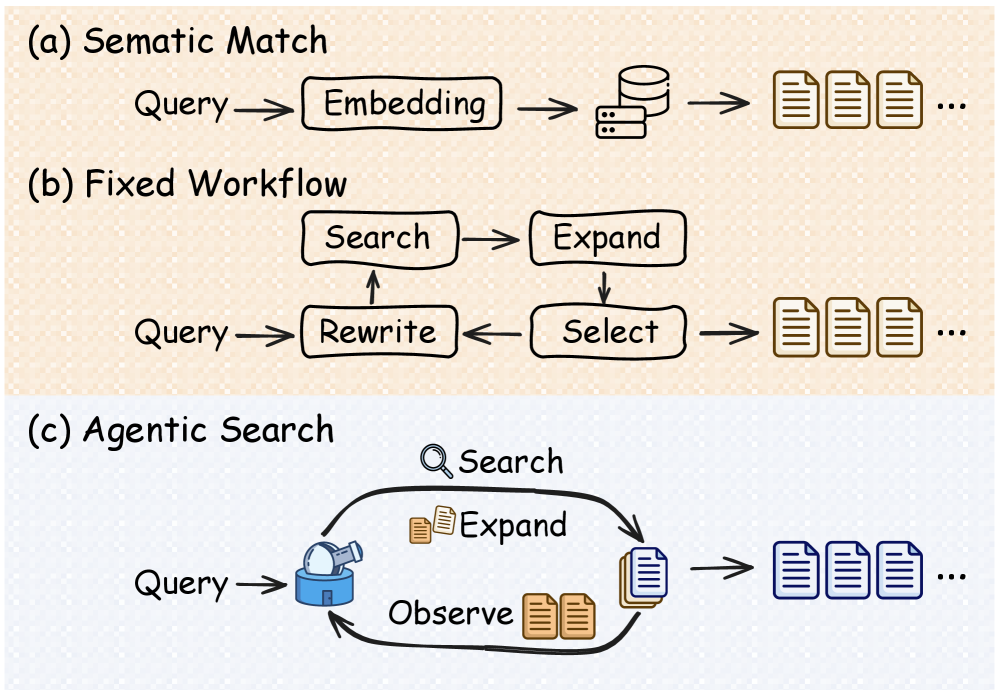
Традиционный академический поиск, как правило, основывается на сопоставлении лексики, то есть на прямом сравнении слов в запросе и в научных публикациях. Этот подход часто упускает из виду тонкие связи между статьями, поскольку не учитывает синонимы, контекст и различные способы выражения одной и той же идеи. В результате, даже если статья релевантна теме исследования, она может быть пропущена, если в ней не используются те же самые ключевые слова, что и в запросе. Данное ограничение особенно заметно в быстро развивающихся областях науки, где терминология постоянно меняется, а авторы используют разнообразные формулировки для описания схожих концепций. Вследствие этого, исследователям зачастую приходится тратить значительное время на ручной просмотр большого количества публикаций, чтобы убедиться, что они не упустили важные работы.
Несмотря на значительный прогресс по сравнению с простым поиском по ключевым словам, семантическое сопоставление все еще испытывает трудности в понимании сложной структуры научной литературы. Научный дискурс характеризуется многозначностью, использованием специализированной терминологии и постоянным развитием предметных областей. По мере появления новых исследований и переосмысления старых, значение терминов и контекст их использования меняются, что создает проблемы для алгоритмов, основанных на фиксированных семантических связях. Таким образом, существующие методы часто упускают из виду актуальные исследования, использующие новые формулировки или рассматривающие знакомые темы под новым углом, что ограничивает возможности для всестороннего анализа и инновационных открытий.
Традиционные методы поиска научной литературы, ориентированные на точное совпадение ключевых слов, зачастую упускают из виду неявные связи между исследованиями. Это приводит к неполноте обзоров литературы и затрудняет обнаружение новых, неожиданных взаимосвязей между различными областями знаний. Научные работы, посвященные схожим проблемам или использующие аналогичные подходы, могут оставаться незамеченными, если в них не используются те же самые ключевые слова, что и в запросе. В результате, исследователям становится сложнее получить полное представление о текущем состоянии дел в интересующей их области и выявить перспективные направления для дальнейших исследований, что замедляет темпы научных открытий и инноваций.
PaperScout: Переосмысление Поиска как Последовательного Принятия Решений
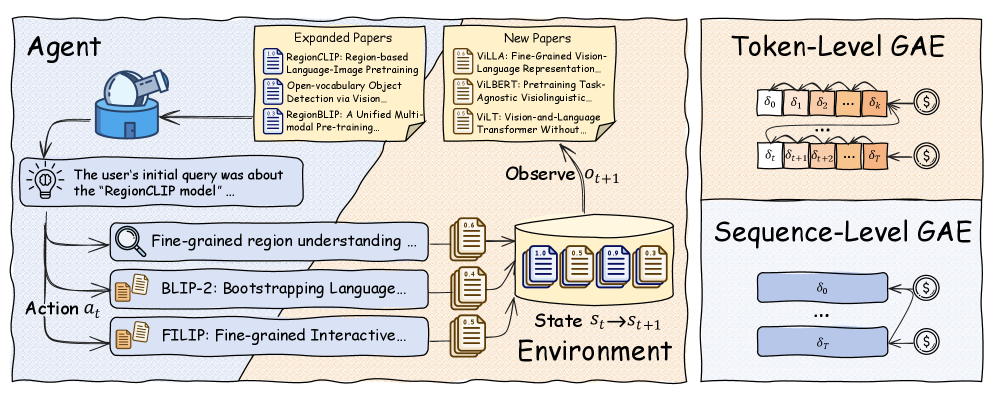
PaperScout представляет новый подход к поиску академической литературы, моделируя процесс как частично наблюдаемый марковский процесс принятия решений (POMDP). В рамках данной модели, состояние системы представляет текущее понимание поискового запроса и релевантности найденных документов, а действия — это конкретные поисковые запросы или выбор документов для дальнейшего анализа. Неполная наблюдаемость обусловлена тем, что полная релевантность документа не всегда очевидна сразу, и требует оценки на основе доступной информации, такой как название, аннотация и ключевые слова. POMDP позволяет агенту (системе PaperScout) оптимизировать последовательность действий для максимизации вероятности обнаружения наиболее релевантных научных работ, учитывая неопределенность и стоимость каждого действия.
В рамках подхода PaperScout, агент на каждом шаге поиска научной литературы принимает обоснованные решения, активно формируя запросы для получения релевантных публикаций. Вместо однократного выполнения запроса и пассивного получения результатов, система динамически корректирует стратегию поиска на основе полученной информации. Это включает в себя не только изменение ключевых слов, но и оценку релевантности найденных статей для определения дальнейших направлений поиска, что позволяет более эффективно исследовать пространство научных работ и находить наиболее подходящие публикации.
В отличие от традиционных систем поиска научной литературы, которые осуществляют пассивный поиск по заданному запросу, PaperScout представляет поиск как последовательный процесс принятия решений. Это означает, что система активно исследует пространство исследований, формируя новые запросы и оценивая релевантность полученных результатов на каждом шаге. Вместо однократного извлечения документов, PaperScout итеративно уточняет стратегию поиска, что позволяет более эффективно находить релевантные публикации, даже если исходный запрос был неполным или неточным. Такой подход позволяет системе адаптироваться к особенностям конкретной исследовательской области и находить публикации, которые могли бы быть пропущены при использовании стандартных методов поиска.
Оптимизация Стратегии Агента: Обучение на Уровне Последовательностей
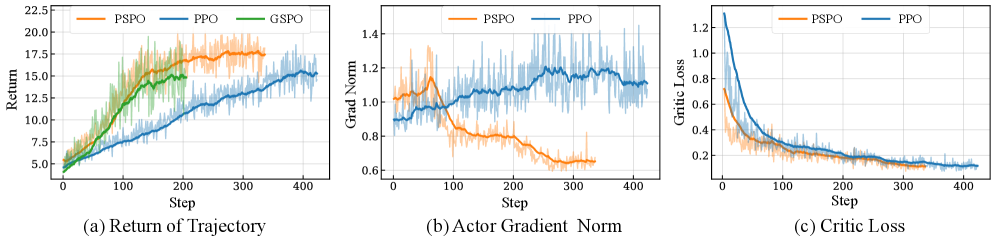
Для обучения PaperScout используется метод Proximal Sequence Policy Optimization (PSPO), который согласовывает гранулярность оптимизации с многоходовыми взаимодействиями агента. В отличие от оптимизации на уровне токенов, PSPO оптимизирует последовательности действий как единое целое, что позволяет более эффективно учитывать долгосрочные последствия каждого шага. Это особенно важно для задач, требующих планирования и стратегического принятия решений, таких как поиск релевантных научных публикаций. PSPO обеспечивает более стабильное обучение за счет ограничения изменений в политике на каждом шаге, предотвращая резкие колебания и улучшая сходимость алгоритма.
Метод, используемый для обучения PaperScout, представляет собой расширение Sequence-Level Policy Optimization (Оптимизация политики на уровне последовательностей). В отличие от точечной оптимизации, данный подход оптимизирует политику агента непосредственно на уровне всей последовательности действий, что обеспечивает повышенную стабильность процесса обучения. Оптимизация на уровне последовательностей позволяет более эффективно учитывать долгосрочные последствия каждого действия и снижает чувствительность к кратковременным колебаниям в сигналах вознаграждения. Это приводит к более быстрой сходимости и повышению эффективности при изучении оптимальной стратегии поиска, поскольку агент учится принимать решения, максимизирующие общую полезность на протяжении всей последовательности взаимодействий.
В отличие от оптимизации на уровне токенов (Token-Level Policy Optimization), которая подвержена проблеме зашумленного распределения ответственности (noisy credit assignment) из-за оценки каждого отдельного токена, используемый подход, оптимизация на уровне последовательностей, предоставляет более надежный и эффективный сигнал обучения. Это достигается за счет оценки всей последовательности действий агента как единого целого, что позволяет более точно определить, какие действия привели к положительному результату и, следовательно, должны быть усилены. Такой подход уменьшает влияние случайных флуктуаций и обеспечивает более стабильное обучение стратегии поиска.
Формирование вознаграждения в PaperScout направлено на максимизацию полноты извлечения релевантных научных работ, стимулируя агента к обнаружению ценных исследований. Данный подход предполагает, что вознаграждение агента напрямую зависит от количества правильно идентифицированных релевантных статей в ответ на запрос. Использование данной формулы вознаграждения позволяет оптимизировать стратегию поиска таким образом, чтобы агент уделял приоритетное внимание обнаружению наиболее значимых работ, улучшая общую эффективность поиска и повышая полезность результатов для пользователя. Эффективность данной формулы подтверждается достижением PaperScout показателя Recall в 0.574 на бенчмарке RealScholarQuery.
В ходе тестирования на бенчмарке RealScholarQuery, PaperScout достиг показателя Recall в 0.574. Этот результат превосходит показатели лучшего из сравниваемых базовых алгоритмов. Показатель Recall измеряет долю релевантных документов, успешно найденных системой, и в данном случае демонстрирует более высокую эффективность PaperScout в извлечении актуальной научной литературы по сравнению с существующими подходами.
В ходе оценки на бенчмарке RealScholarQuery, PaperScout достиг показателя LLM-score в 2.576. Данный показатель, оцениваемый с помощью большой языковой модели, служит мерой качества и релевантности найденных научных работ. Полученный результат демонстрирует превосходство PaperScout над другими исследованными методами, подтверждая эффективность предложенного подхода к оптимизации стратегии поиска и извлечения информации.
Расширение Горизонтов Поиска: Использование Визуально-Языковых Моделей
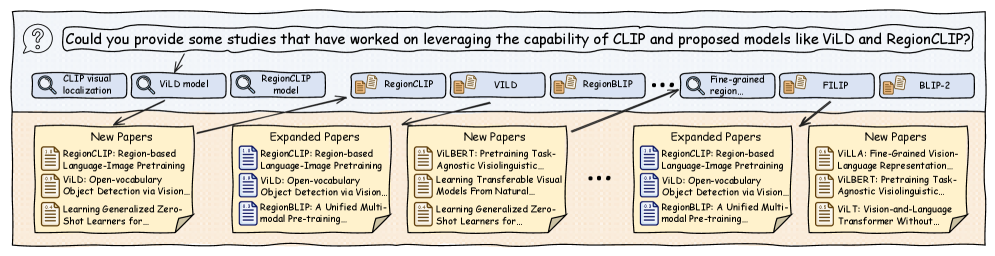
Для эффективного сбора информации и расширения области поиска связанных исследований, система PaperScout использует комплекс специализированных инструментов, включая модуль поиска и модуль расширения. Модуль поиска позволяет находить релевантные научные работы по заданным критериям, в то время как модуль расширения углубляет исследование, автоматически выявляя и анализируя работы, косвенно связанные с исходным запросом. Такой подход, основанный на последовательном поиске и расширении, позволяет PaperScout не просто находить публикации по ключевым словам, но и выявлять более сложные взаимосвязи между статьями, значительно повышая полноту и глубину анализа научной литературы.
Агент PaperScout использует возможности моделей CLIP и их модификаций, таких как RegionCLIP и ViLD, для извлечения детальных визуальных представлений из научных публикаций. Эти модели позволяют не просто идентифицировать изображения в статьях, но и понимать их содержание на более глубоком уровне, анализируя отдельные области на графиках, схемах и иллюстрациях. В отличие от традиционных методов, опирающихся на текстовые метки, визуальный анализ с помощью CLIP позволяет выявлять взаимосвязи и закономерности, которые остаются незамеченными при простом поиске по ключевым словам. Такой подход значительно расширяет возможности понимания научных работ и способствует обнаружению скрытых связей между различными исследованиями.
Система PaperScout, используя в своей работе языковые модели (LLM) в сочетании с визуальным анализом, способна понимать содержание научных статей на качественно новом уровне. В отличие от традиционных методов поиска, основанных на простом сопоставлении ключевых слов, PaperScout анализирует не только текст, но и визуальные элементы, такие как графики и диаграммы. Это позволяет выявлять скрытые связи и закономерности между исследованиями, которые остаются незамеченными при обычном поиске. Благодаря такому комплексному подходу, система способна находить релевантные работы, даже если в их названиях или аннотациях не используются те же термины, что и в исходном запросе, значительно расширяя возможности для всестороннего анализа научной литературы.
Интегрированный подход, используемый в системе PaperScout, значительно повышает эффективность и полноту обзора научной литературы. Вместо традиционного поиска по ключевым словам, система использует комбинацию моделей CLIP и больших языковых моделей (LLM) для извлечения и анализа визуальной информации из научных статей. Это позволяет выявлять связи и релевантные исследования, которые могли бы остаться незамеченными при обычном поиске. В результате, исследователи получают более полное представление о существующей литературе за меньшее время, что способствует более глубокому и продуктивному научному анализу. Достигнутый показатель Recall в 0.459 на бенчмарке AutoScholarQuery подтверждает превосходство данного подхода над существующими методами и открывает новые возможности для автоматизации и улучшения процесса обзора литературы.
В ходе тестирования на бенчмарке AutoScholarQuery система PaperScout продемонстрировала показатель Recall в 0.459, что позволило ей установить новый стандарт производительности в области поиска и анализа научной литературы. Этот результат свидетельствует о значительном превосходстве над существующими подходами в способности системы находить релевантные исследования, даже если они не содержат явных ключевых слов. Высокий показатель Recall указывает на то, что PaperScout эффективно извлекает важную информацию из научных статей, обеспечивая более полное и всестороннее представление о текущем состоянии исследований в заданной области, и существенно повышая эффективность работы с научными публикациями.
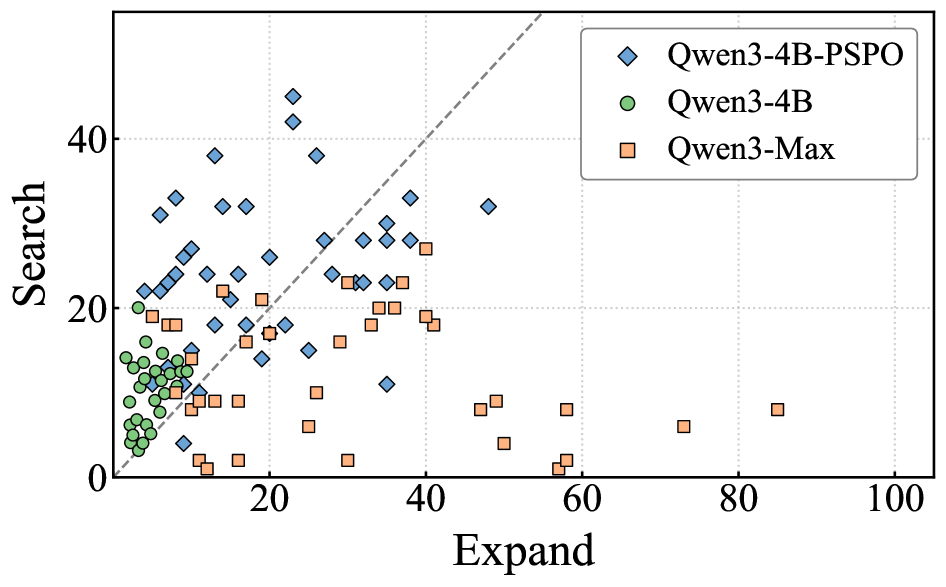
Исследование демонстрирует стремление к нарушению установленных границ в области поиска научных работ. PaperScout, как автономный агент, не просто следует заданным алгоритмам, а активно исследует пространство возможностей, адаптируясь и оптимизируясь посредством обучения с подкреплением. Этот подход перекликается с мыслью Барбары Лисков: «Программы должны быть спроектированы так, чтобы их можно было изменять без риска сломать другие части». PaperScout, подобно хорошо спроектированной программе, способен к эволюции и адаптации, не нарушая целостность процесса поиска. PSPO, как ключевой элемент системы, позволяет агенту экспериментировать с различными стратегиями, проверяя, что произойдёт, если нарушить привычный порядок действий в последовательности запросов, что и является сутью предлагаемого подхода.
Что дальше?
Представленный подход, безусловно, открывает двери для автоматизированного исследования академической литературы, но истинный скептик не может не заметить, что сама концепция “релевантности” остается зыбкой. Что если наиболее ценные открытия скрыты в статьях, изначально пропущенных алгоритмом, посчитанным “нерелевантным”? Упор на последовательную оптимизацию политики (PSPO) — это шаг вперёд, но реальная проблема заключается не в совершенствовании поиска, а в переосмыслении самой цели. Необходимо исследовать, как подобные агенты могут генерировать новые исследовательские вопросы, а не просто отвечать на существующие.
Ограничения текущих больших языковых моделей (LLM) также представляют собой серьезную преграду. Способность агента к обобщению и адаптации к новым, узкоспециализированным областям знаний требует критической оценки. Простое увеличение масштаба модели — это лишь временное решение. Более перспективным представляется разработка гибридных систем, объединяющих возможности LLM с символьными подходами и экспертными знаниями, создавая нечто большее, чем просто статистический оракул.
В конечном счете, успех подобных агентов будет определяться не точностью поиска, а способностью провоцировать интеллектуальное любопытство. Истинное открытие редко следует предсказуемой траектории. Поэтому, будущее автоматизированного исследования литературы лежит не в оптимизации существующих алгоритмов, а в создании систем, способных к непредсказуемым, творческим поискам, способных сломать шаблоны и увидеть скрытые связи, ускользающие от человеческого взгляда.
Оригинал статьи: https://arxiv.org/pdf/2601.10029.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.