Статьи QuantRise
Финансовый интеллект машин: новый тест на прочность
Автор: Денис Аветисян
- Выявление Количественных Ограничений в Больших Языковых Моделях
- QuantEval: Строгий Эталон для Оценки Количественных Способностей
- Масштабирование Генерации Данных с Использованием Многоагентных Систем
- Квантификация Производительности LLM: Метрики и Валидация
- К Более Надежному Финансовому Искусственному Интеллекту
- Куда Далее?
Исследователи представили комплексный инструмент для оценки способностей больших языковых моделей в решении задач количественного финансового анализа.
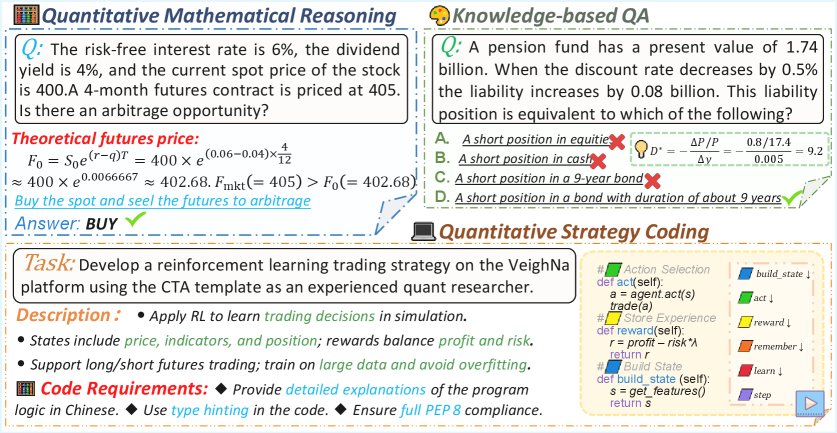
QuantEval: эталон для оценки навыков больших языковых моделей в области финансового количественного анализа, включая знания, рассуждения и разработку стратегий с бэктестингом.
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в различных областях, их оценка в контексте количественного финансового анализа остается фрагментированной и часто ограничивается проверкой знаний. В данной работе представлена ‘QuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models’ — новая методика оценки LLM по трем ключевым направлениям: знаниевым вопросам, количественному рассуждению и кодированию торговых стратегий. В отличие от существующих бенчмарков, QuantEval включает в себя бэктестинг, позволяющий оценить работоспособность сгенерированных моделей с использованием финансовых показателей. Сможет ли QuantEval ускорить внедрение LLM в реальные торговые процессы и повысить эффективность количественного анализа?
Выявление Количественных Ограничений в Больших Языковых Моделях
Несмотря на впечатляющие способности в обработке и генерации естественного языка, современные большие языковые модели (LLM) демонстрируют существенные трудности при решении сложных количественных задач. В то время как LLM способны понимать и формулировать вопросы, связанные с числами и величинами, их возможности в области строгого логического мышления и точных вычислений ограничены. Это проявляется в неспособности последовательно применять математические принципы, выполнять многоступенчатые расчеты или интерпретировать данные, требующие глубокого количественного анализа. Несмотря на кажущуюся уверенность в ответах, LLM часто допускают ошибки в арифметике, неверно применяют формулы или делают необоснованные предположения, что ставит под сомнение их надежность в приложениях, где требуется абсолютная точность и бесперебойная логика, например, в финансовом моделировании или научном анализе данных. Проблема заключается не в отсутствии знаний, а в недостатке способности к последовательному, формальному рассуждению, необходимому для корректного применения этих знаний.
Существующие наборы данных для оценки количественных способностей больших языковых моделей (LLM) зачастую не отражают реальной сложности финансовых задач, что приводит к неточной оценке их возможностей. Для восполнения этого пробела разработан QuantEval — новый эталон, содержащий 1575 примеров, призванных обеспечить более глубокую и реалистичную оценку. Данный набор данных включает в себя разнообразные финансовые расчеты и сценарии, требующие не только знания формул, но и умения применять их в контексте, что позволяет более точно определить потенциал LLM в области финансовых решений и выявить области, требующие дальнейшего совершенствования.
Недостаточность количественного рассуждения в больших языковых моделях (LLM) существенно ограничивает их применение в критически важных финансовых процессах принятия решений. В сферах, где точность является первостепенной, например, в управлении инвестициями, оценке рисков или прогнозировании рыночных тенденций, даже незначительные ошибки в расчетах могут привести к существенным финансовым потерям. Использование LLM в этих областях требует гарантированной надежности в обработке числовых данных и логических операций, что на данный момент представляет собой серьезную проблему. Вследствие этого, широкое внедрение этих моделей в финансовый сектор сдерживается необходимостью обеспечения беспрецедентного уровня точности и предотвращения потенциальных ошибок, способных нанести ущерб финансовой стабильности.

QuantEval: Строгий Эталон для Оценки Количественных Способностей
QuantEval предназначен для оценки больших языковых моделей (LLM) по трем основным направлениям: проверка знаний в области финансов (Knowledge-Based QA), решение количественных математических задач (Quantitative Mathematical Reasoning) и разработка стратегий кодирования для количественного анализа (Quantitative Strategy Coding). Данный подход позволяет комплексно оценить возможности LLM в сфере количественного анализа, проверяя не только теоретические знания, но и способность к практическому применению математических методов и программированию для финансовых вычислений и бэктестинга.
Бенчмарк QuantEval использует многогранный подход к оценке, сочетая проверку концептуального понимания с практическим применением в реалистичных финансовых вычислениях и бэктестинге. Набор данных состоит из 660 вопросов и ответов, проверяющих знания (Knowledge QA), 855 задач на количественное рассуждение (Reasoning), и 60 примеров кодирования финансовых стратегий (Strategy Coding). Такое разделение позволяет комплексно оценить языковую модель в области количественного анализа, охватывая как теоретические знания, так и способность к практическому применению и программированию.
Бенчмарк QuantEval обеспечивает всестороннюю оценку количественных возможностей больших языковых моделей (LLM), выходя за рамки поверхностных проверок. В отличие от традиционных методов оценки, QuantEval анализирует производительность LLM в трех ключевых областях: ответы на вопросы, основанные на знаниях, количественное математическое рассуждение и кодирование количественных стратегий. Такой многогранный подход позволяет выявить сильные и слабые стороны моделей в решении практических финансовых задач, включающих не только теоретическое понимание, но и реализацию вычислений и бэктестинг стратегий. Общий объем данных, используемых в бенчмарке, составляет 660 примеров для проверки знаний, 855 примеров для оценки рассуждений и 60 примеров для кодирования стратегий, что обеспечивает надежную и полную оценку.
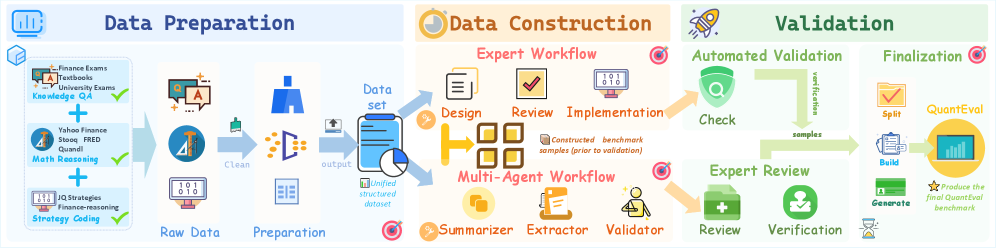
Масштабирование Генерации Данных с Использованием Многоагентных Систем
Для удовлетворения потребностей QuantEval была применена методика автоматизированного построения на основе многоагентной системы, объединяющая экспертную аннотацию с автоматической генерацией контента. Этот подход позволил масштабировать процесс создания данных, сочетая точность, обеспечиваемую ручной проверкой специалистов, с эффективностью автоматизированного создания примеров. Эксперты осуществляли контроль качества и валидацию сгенерированных данных, что позволило обеспечить высокую надежность и релевантность итогового набора данных для оценки моделей.
Для масштабирования генерации данных в QuantEval используется система, объединяющая модели Claude-4.5-sonnet и GPT-4o. Распределение рабочей нагрузки между этими моделями позволяет оптимизировать процесс создания данных. Claude-4.5-sonnet эффективно справляется с задачами, требующими более длинных и детализированных ответов, в то время как GPT-4o демонстрирует высокую скорость и точность в генерации коротких и лаконичных вопросов и ответов. Такой подход позволяет максимизировать общую производительность и снизить затраты времени на создание необходимого объема данных для оценки моделей.
Для обеспечения релевантности и точности вопросов в бенчмарке QuantEval, в конвейер генерации данных включены финансовые учебники в качестве основного источника информации для Knowledge-Based QA (вопросов и ответов на основе знаний). Использование структурированных и проверенных учебных материалов гарантирует, что вопросы ориентированы на фундаментальные финансовые концепции и подкреплены надежной информацией. Такой подход позволяет создавать бенчмарк, который адекватно оценивает способность моделей понимать и применять финансовые знания, избегая неточностей или вводящих в заблуждение вопросов.
Квантификация Производительности LLM: Метрики и Валидация
Для оценки производительности больших языковых моделей (LLM) используется комплекс метрик, адаптированных к различным типам задач. Для задач, связанных с ответами на вопросы, требующие знаний (Knowledge-Based QA) и количественным математическим рассуждением, ключевой метрикой является точность (Accuracy). Для оценки эффективности LLM в разработке количественных торговых стратегий применяются два показателя: процент успешного выполнения кода (Execution Rate) и средняя абсолютная ошибка (Mean Absolute Error, MAE), которая измеряет среднее отклонение предсказанных значений от фактических. Использование этих метрик позволяет объективно сравнивать производительность различных моделей и отслеживать прогресс в развитии LLM для конкретных задач.
Задачи количественного математического рассуждения строятся на основе исторических рыночных данных, что обеспечивает реалистичный контекст для вычислений и практическую значимость результатов. Использование исторических данных позволяет оценивать способность модели к решению задач, непосредственно связанных с реальными рыночными условиями и тенденциями. Это отличается от абстрактных математических задач и позволяет более точно оценить применимость модели в сфере финансов и торговли. Данные включают в себя исторические цены активов, объемы торгов и другие релевантные показатели, необходимые для выполнения расчетов и прогнозирования.
Для повышения производительности и анализа процесса принятия решений, в процессе тестирования языковых моделей используется методика Chain-of-Thought Prompting (CoT). Данный подход заключается в формировании запросов, стимулирующих модель к последовательному изложению промежуточных шагов рассуждений перед выдачей окончательного ответа. Это позволяет не только оценить логику модели, но и повысить точность выполнения задач. Для количественной оценки результатов, по каждой протестированной модели фиксируются три ключевых показателя: точность (Accuracy) — доля корректных ответов, процент успешно выполненных запросов (Executable Rate), и средняя абсолютная ошибка (Mean Absolute Error, MAE), отражающая среднее отклонение прогнозируемых значений от фактических.
К Более Надежному Финансовому Искусственному Интеллекту
Детальная оценка возможностей больших языковых моделей (LLM) посредством QuantEval способна существенно ускорить инновации в ключевых областях финансового анализа. Исследование выявляет сильные и слабые стороны LLM в решении сложных количественных задач, что позволяет разработчикам алгоритмической торговли создавать более эффективные стратегии, а специалистам по управлению рисками — точнее оценивать потенциальные убытки. Кроме того, детальный анализ способствует усовершенствованию моделей финансового прогнозирования, позволяя предсказывать рыночные тенденции с большей уверенностью. По сути, QuantEval предоставляет необходимую основу для создания более надежных и точных финансовых инструментов, основанных на искусственном интеллекте, открывая новые возможности для оптимизации инвестиционных процессов и повышения финансовой стабильности.
Разработанная платформа QuantEval представляет собой стандартизированный инструмент для сопоставления возможностей различных больших языковых моделей (LLM) в области количественного рассуждения. Она позволяет объективно оценивать и сравнивать производительность моделей при решении финансовых задач, таких как анализ данных, прогнозирование рыночных тенденций и оценка рисков. Благодаря унифицированному подходу к тестированию, QuantEval обеспечивает возможность отслеживания прогресса в развитии LLM, позволяя исследователям и разработчикам определять сильные и слабые стороны каждой модели и направлять усилия по улучшению их функциональности. Это способствует повышению надежности и точности систем искусственного интеллекта, применяемых в финансовой сфере, и созданию более эффективных алгоритмических стратегий.
Оценка QuantEval выявляет слабые места современных больших языковых моделей (LLM) в решении количественных задач, что становится ориентиром для дальнейших исследований и разработок в области искусственного интеллекта для финансов. Анализ конкретных ошибок и ограничений, проявляющихся в бенчмарках, позволяет целенаправленно улучшать алгоритмы и архитектуры LLM, повышая их точность и надежность в таких критически важных областях, как алгоритмическая торговля и управление рисками. Идентифицируя проблемные зоны, QuantEval способствует созданию более устойчивых и заслуживающих доверия финансовых систем, основанных на искусственном интеллекте, и открывает путь к разработке новых, более эффективных моделей, способных к более глубокому пониманию и анализу финансовых данных.
Представленный труд акцентирует внимание на необходимости строгой оценки возможностей больших языковых моделей в области количественных финансов. Разработка QuantEval, как нового эталона, направлена на проверку не только знаний, но и способности к логическому мышлению и генерации исполняемого кода для бэктестинга. В этом контексте, замечание Марвина Мински: «Искусственный интеллект — это не попытка сделать машины умными, а попытка понять, что такое интеллект.» приобретает особую значимость. Ведь оценка способности модели к решению сложных финансовых задач требует глубокого понимания не только алгоритмов, но и самой природы количественного анализа, что, по сути, является проверкой её «интеллекта» в данной предметной области. Акцент на масштабируемости и асимптотической устойчивости алгоритмов, заложенный в работе, полностью соответствует принципам математической чистоты и доказуемости, которые являлись ключевыми в подходе Мински к разработке искусственного интеллекта.
Куда Далее?
Без точного определения задачи любое решение — шум. Представленный бенчмарк QuantEval, несомненно, является шагом вперед в оценке возможностей больших языковых моделей в области количественных финансов. Однако, следует признать, что успешное прохождение тестов — это лишь демонстрация способности к манипулированию символами, а не гарантия истинного понимания лежащих в основе финансовых принципов. Истинно элегантное решение должно быть доказуемо корректным, а не просто “работать на тестах”.
Основным ограничением остается необходимость в создании действительно строгих метрик для оценки не просто синтаксической правильности кода, но и его экономической осмысленности. Бенчмарк должен включать сценарии с неявными ошибками, требующие от модели не только навыков кодирования, но и критического анализа. Кроме того, необходимо учитывать влияние шума в исторических данных, что требует от моделей способности к робастному моделированию.
В конечном счете, задача состоит не в создании моделей, которые имитируют финансовые стратегии, а в создании моделей, способных к самостоятельному открытию новых, действительно эффективных подходов. Это требует перехода от оценки “способности к кодированию” к оценке “способности к доказательству”. И лишь тогда можно будет говорить о реальном прогрессе в этой области.
Оригинал статьи: https://arxiv.org/pdf/2601.08689.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.