Искусственный интеллект
Квантовые нейросети: новый взгляд на семантический анализ
Автор: Денис Аветисян
Исследование посвящено применению принципов квантовых вычислений для анализа и обработки семантической информации в больших языковых моделях.
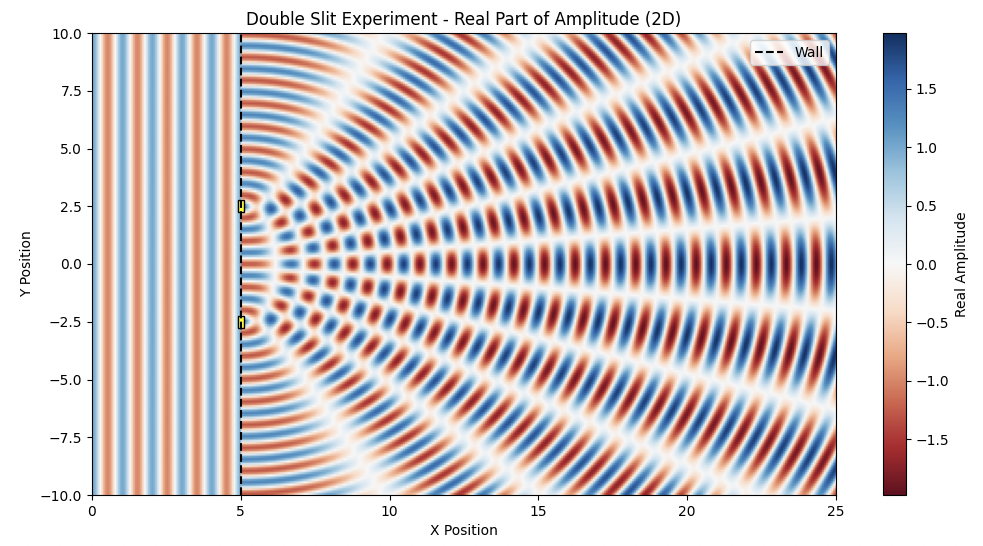
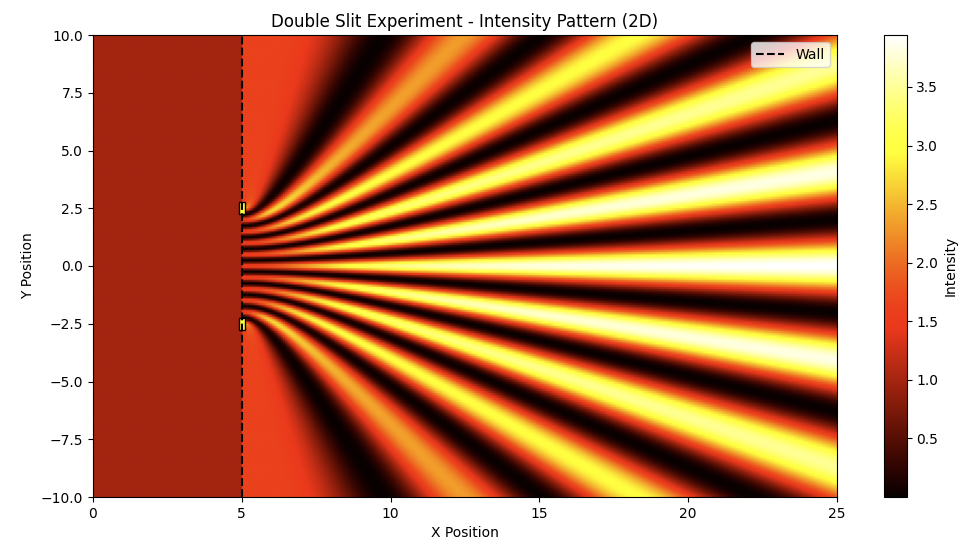
В работе исследуется возможность представления семантических связей с помощью квантовых цепей и сложных векторных представлений, демонстрируя связь между языковыми моделями и квантовой механикой.
Несмотря на впечатляющие успехи больших языковых моделей (LLM), их возможности в обработке семантической информации остаются областью для дальнейшего развития. В статье ‘Quantum LLMs Using Quantum Computing to Analyze and Process Semantic Information’ представлен квантовый подход к анализу LLM-вложений, использующий комплексные представления и моделирование семантических связей посредством принципов квантовой механики. Показано, что прямое отображение семантических пространств LLM на квантовые схемы позволяет оценить семантическое сходство с использованием квантового оборудования, что подтверждено экспериментальным расчетом косинусного сходства между вложениями Google Sentence Transformer на реальном квантовом компьютере. Может ли интеграция квантовых вычислений открыть новые горизонты в представлении и обработке семантической информации, и какие алгоритмы для обработки естественного языка будут разработаны в будущем?
Семантическая Интерференция: Пределы Классических Векторных Представлений
Современные векторные представления, используемые в больших языковых моделях, несмотря на свою эффективность, сталкиваются с трудностями при улавливании тонкостей значения. Существующие модели оперируют с семантикой как с фиксированным вектором в многомерном пространстве, что не позволяет адекватно отразить многогранность и контекстуальную зависимость смысла. Например, слово «банк» может обозначать финансовое учреждение или берег реки, однако стандартные векторные представления зачастую усредняют эти значения, теряя важные нюансы. Это ограничение особенно заметно при обработке сложных текстов, где значение слова определяется его окружением и подразумеваемыми ассоциациями. В результате, модели испытывают затруднения при разрешении неоднозначности и понимании скрытых смыслов, что снижает качество анализа и генерации текста.
Подобно тому, как в знаменитом эксперименте с двумя щелями частица демонстрирует волновые свойства, проявляя себя одновременно в нескольких местах, значение слова или фразы может быть многогранным и неоднозначным. В классических векторных пространствах, используемых для представления семантики в современных языковых моделях, эта способность к “семантической суперпозиции” утрачивается. Вместо того чтобы отражать потенциал значения, модели фиксируют единственное, доминирующее представление. Это ограничение приводит к тому, что нюансы, контекстуальные различия и потенциальные интерпретации упускаются из виду, снижая способность моделей к тонкому пониманию языка и генерации осмысленного текста. Идея заключается в том, что значение не является фиксированной точкой в векторном пространстве, а скорее вероятностным распределением, отражающим множество возможных интерпретаций.
В рамках изучения семантической интерференции, матрица плотности представляется перспективным теоретическим инструментом для преодоления ограничений, присущих классическим векторным представлениям значений. В отличие от традиционных моделей, фиксирующих единственное значение для каждого слова или фразы, матрица плотности позволяет зафиксировать “семантическую суперпозицию” — возможность одновременного существования множественных значений и интерпретаций. Подобно тому, как в квантовой механике состояние частицы описывается вероятностным распределением, матрица плотности представляет семантическое значение не как фиксированную точку в векторном пространстве, а как распределение вероятностей по различным возможным значениям. Такой подход позволяет моделировать неоднозначность и контекстуальную зависимость смысла, улавливая тонкие нюансы, которые ускользают от классических моделей. Использование матрицы плотности открывает путь к созданию языковых моделей, способных более точно отражать сложность и богатство человеческого языка, приближаясь к пониманию смысла, как вероятностного, а не детерминированного явления.
За пределами Величины: Комплексные Вложения и Квантовское Вдохновение
В отличие от традиционных векторных представлений (embeddings) в больших языковых моделях (LLM), которые кодируют семантическую информацию исключительно в виде величины вектора, комплексные embeddings добавляют к этому фазовую информацию. Это достигается путем представления каждого вектора как комплексного числа, где модуль вектора соответствует его величине, а аргумент — фазе. Включение фазы позволяет улавливать более тонкие семантические связи, которые теряются при использовании только величины, поскольку фаза может кодировать, например, контекст или нюансы значения, не отражаемые в простой величине сходства. Такой подход позволяет более точно представлять отношения между словами и фразами, особенно в случаях, когда семантическое сходство не является прямым и линейным.
Принцип использования комплексных вложений в моделях обработки естественного языка аналогичен описанию состояния квантовой частицы в квантовой механике. В квантовой механике состояние частицы определяется не только амплитудой волновой функции (), но и ее фазой (). Фаза содержит информацию о взаимном расположении волн и играет критическую роль в определении вероятности и интерференции. В комплексных вложениях фазовая компонента вектора представления позволяет модели учитывать более тонкие семантические нюансы, которые теряются при использовании только величины (амплитуды) вектора.
Повышенная точность вычисления семантической близости, обеспечиваемая комплексными эмбеддингами, критически важна для задач вопросно-ответных систем и информационного поиска. Традиционные методы вычисления близости векторов эмбеддингов часто игнорируют фазовую информацию, что приводит к неточностям при сравнении семантически схожих, но не идентичных запросов и документов. Использование комплексных чисел в эмбеддингах позволяет учитывать как амплитуду, так и фазу, что значительно улучшает способность системы различать нюансы в значениях слов и фраз. Это, в свою очередь, приводит к более релевантным ответам в системах QA и повышает эффективность поиска информации, особенно в случаях, когда требуется учитывать контекст и подтекст запроса. Ожидается, что повышение точности семантического сравнения окажет значительное влияние на производительность приложений, использующих LLM.
Квантовые Алгоритмы для Семантической Близости
Квантовые алгоритмы, в частности алгоритм квантовой оценки фазы (Quantum Phase Estimation, QPE), представляют собой перспективный подход к ускорению вычислений семантической близости, использующих комплексные векторные представления (embeddings). В отличие от классических методов, QPE позволяет экспоненциально ускорить поиск в пространстве embeddings за счет использования принципов суперпозиции и запутанности. Данный алгоритм эффективно оценивает скалярное произведение между векторами embeddings, что напрямую связано с косинусной мерой схожести, являющейся ключевой метрикой для определения семантической близости. Применение QPE позволяет потенциально значительно сократить время вычислений при обработке больших объемов текстовых данных и высокоразмерных векторных представлений.
Квантовые алгоритмы, такие как оценка квантовой фазы, используют принципы суперпозиции и запутанности для экспоненциального ускорения исследования пространства вложений. Суперпозиция позволяет квантовому биту одновременно представлять 0 и 1, что обеспечивает параллельную обработку данных. Запутанность создает корреляцию между кубитами, позволяя им действовать согласованно, даже на больших расстояниях. В контексте вычисления семантического сходства, это означает, что алгоритм может одновременно оценивать сходство между несколькими парами вложений, что приводит к значительному сокращению времени вычислений по сравнению с классическими методами, которым требуется последовательная оценка каждой пары.
В ходе проведенного исследования была продемонстрирована возможность оценки косинусного сходства между векторными представлениями (embeddings) языковых моделей (LLM) с использованием квантовых схем на реальном квантовом компьютере. Для двух предложений, представленных в виде усеченных 128-мерных векторных представлений, квантовый алгоритм показал сходство 0.8635. Данный результат тесно соответствует классически вычисленному значению косинусного сходства, составившему 0.8682, что подтверждает принципиальную реализуемость и высокую точность квантового подхода к задаче определения семантической близости текстов.
Оптимизация Вложений с Вариационными Квантовыми Эйнзольверами
В настоящее время, для оптимизации векторных представлений (embeddings) больших языковых моделей (LLM) активно применяются вариационные квантовые алгоритмы поиска собственных значений (VQEs). Этот подход объединяет возможности классических вычислений и квантовых алгоритмов, позволяя достичь более высокой точности и эффективности по сравнению с традиционными методами. VQE позволяет находить оптимальные параметры embeddings, минимизируя энергию Гамильтониана, представляющего пространство встраиваний. В результате, модели получают более качественные векторные представления слов и фраз, что способствует улучшению их способности понимать и генерировать естественный язык. Этот гибридный подход представляет собой перспективное направление в развитии искусственного интеллекта, позволяющее использовать преимущества квантовых вычислений для решения задач обработки естественного языка.
В основе оптимизации векторных представлений с использованием вариационных квантовых эйнзольверов (ВКЭ) лежит поиск основного состояния Гамильтониана, который моделирует пространство встраивания. Гамильтониан, по сути, кодирует взаимосвязи между словами и фразами в этом пространстве. ВКЭ, используя принципы квантовой механики, эффективно минимизирует энергию этого Гамильтониана, что приводит к более точной и компактной семантической репрезентации. В результате, векторные представления становятся более чувствительными к контексту и нюансам языка, позволяя языковым моделям лучше понимать и генерировать текст. Такой подход позволяет найти оптимальную конфигурацию векторов, отражающую истинную семантику данных, что значительно превосходит традиционные методы оптимизации, особенно в задачах, требующих высокой точности и способности к обобщению.
Использование квантовых вычислений для оптимизации языковых моделей открывает перспективы создания значительно более устойчивых и контекстуально осведомленных систем. Процесс оптимизации, осуществляемый с помощью вариационных квантовых эйнзольверов, позволяет находить оптимальные представления слов и фраз в многомерном семантическом пространстве. Это приводит к улучшению способности модели понимать нюансы языка, разрешать неоднозначности и более точно улавливать взаимосвязи между понятиями. В результате, языковые модели, оптимизированные таким образом, способны генерировать более связные, релевантные и осмысленные тексты, а также демонстрируют повышенную устойчивость к шуму и неполноте данных. Такой подход обещает значительный прогресс в области обработки естественного языка и открывает новые возможности для создания интеллектуальных систем, способных к глубокому пониманию и генерации человеческого языка.
Будущее Семантического Понимания
В настоящее время семантическое понимание языка часто основывается на сравнении векторных представлений слов и фраз, что, несмотря на свою эффективность, ограничивает способность систем улавливать тонкие нюансы и контекстуальные значения. Однако, использование квантовых вычислений открывает принципиально новые возможности в этой области. Квантовые алгоритмы позволяют моделировать сложные взаимосвязи между понятиями, выходя за рамки линейных представлений и учитывая вероятностную природу языка. Это приводит к более глубокому и многогранному пониманию смысла, поскольку квантовые вычисления способны обрабатывать информацию в экспоненциально большем пространстве состояний, чем классические компьютеры. Таким образом, переход к квантовым методам анализа текста может революционизировать обработку естественного языка, позволяя создавать системы, способные не просто распознавать слова, а действительно понимать их значение в контексте.
Квантовые методы ядра представляют собой перспективный подход к эффективной обработке и представлению сложных векторных представлений, или эмбеддингов, в задачах семантического анализа. В отличие от классических методов, требующих экспоненциального увеличения вычислительных ресурсов при работе со сложными данными, квантовые ядра позволяют компактно кодировать взаимосвязи между элементами, используя принципы квантовой механики, такие как суперпозиция и запутанность. Это открывает возможности для выявления тонких семантических различий и связей, которые остаются незамеченными при использовании традиционных алгоритмов. Благодаря этому, квантовые ядра могут значительно повысить точность и эффективность задач, связанных с пониманием естественного языка, таких как анализ тональности, классификация текстов и машинный перевод, позволяя создавать более интеллектуальные и контекстно-чувствительные языковые модели.
В настоящее время активно ведутся исследования, направленные на масштабирование квантовых алгоритмов для обработки естественного языка. Основной задачей является интеграция этих алгоритмов в существующие конвейеры NLP, что позволит значительно повысить эффективность и точность семантического анализа. Успешное внедрение квантовых вычислений в лингвистические модели откроет путь к созданию принципиально новых систем, способных не просто распознавать слова, но и понимать их глубинное значение и контекст, приближая нас к созданию поистине интеллектуальных языковых моделей, способных к рассуждениям и генерации осмысленного текста. Разработка эффективных методов для работы с большими объемами данных и оптимизация квантовых схем являются ключевыми аспектами текущих исследований в этой области.
Исследование демонстрирует интересную взаимосвязь между представлением семантической информации в больших языковых моделях и принципами квантовой механики. Подобно тому, как квантовые состояния могут существовать в суперпозиции, сложные векторные представления в LLM улавливают многогранность смысла, позволяя моделям понимать нюансы языка. Как заметил Эрвин Шрёдингер: «Всё, что мы знаем, — это то, что ничего не знаем». Эта фраза отражает глубину неизвестного в области искусственного интеллекта и необходимость постоянного исследования, чтобы расширить границы возможного. Использование квантовых схем для обработки этих сложных представлений, как показано в статье, может стать следующим шагом к созданию более мощных и эффективных языковых моделей, способных к истинному пониманию языка.
Что дальше?
Представленная работа, безусловно, открывает новые горизонты в исследовании взаимодействия между большими языковыми моделями и квантовыми вычислениями. Однако, следует признать, что связь между сложными векторными представлениями семантики и квантовыми цепями пока остается, скорее, аналогией, чем строгим математическим соответствием. Вопрос о том, действительно ли квантовые алгоритмы способны предложить существенное преимущество в обработке семантической информации, требует дальнейшей, более глубокой проработки. Очевидно, что текущие реализации сталкиваются с ограничениями, связанными с масштабируемостью и когерентностью квантовых систем.
Перспективы развития лежат, вероятно, не в прямой замене классических алгоритмов на квантовые, а в создании гибридных систем, использующих сильные стороны обеих парадигм. Инфраструктура должна развиваться без необходимости перестраивать весь квартал. Необходимо сосредоточиться на выявлении конкретных задач, где квантовые вычисления могут принести ощутимую пользу — например, в области нечеткого сопоставления или разрешения неоднозначностей в естественном языке. Структура определяет поведение, и понимание этой структуры в контексте семантических представлений — ключ к успеху.
В конечном итоге, истинный прогресс потребует не только развития квантовых алгоритмов, но и углубленного понимания самой природы семантики и того, как она кодируется в нейронных сетях. Возможно, в поисках ответов придется взглянуть за пределы существующих моделей и обратиться к более фундаментальным принципам когнитивной науки.
Оригинал статьи: https://arxiv.org/pdf/2512.02619.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.