Квантовые технологии
Квантовые схемы: поиск оптимальной архитектуры с помощью искусственного интеллекта
Автор: Денис Аветисян
Новый подход, основанный на многоагентном обучении с подкреплением, позволяет значительно ускорить процесс разработки квантовых схем, адаптированных к конкретным задачам.

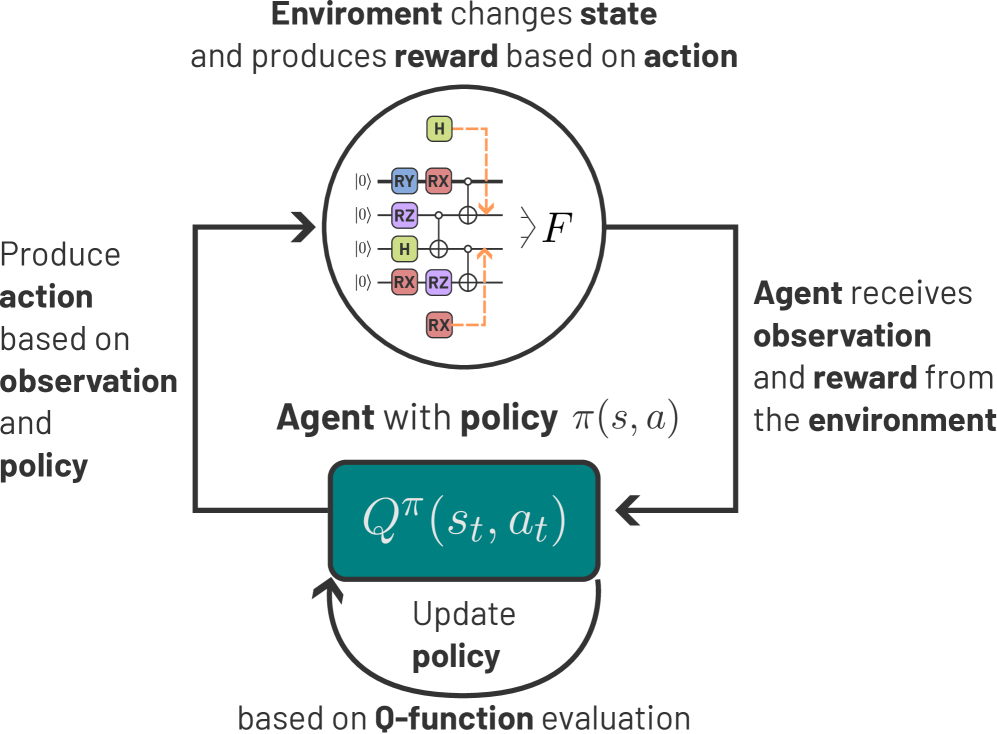
В статье представлен метод распределенного поиска архитектур квантовых схем с использованием алгоритмов многоагентного обучения с подкреплением и QMIX.
Поиск оптимальной структуры квантовых схем для вариационных алгоритмов представляет собой сложную задачу, масштабируемость которой ограничена ростом размерности пространства действий. В работе, озаглавленной ‘Distributed quantum architecture search using multi-agent reinforcement learning’, предложен новый алгоритм обучения с подкреплением, основанный на использовании множества агентов, каждый из которых оптимизирует отдельный блок квантовой схемы. Такой подход позволяет значительно ускорить сходимость процесса поиска и снизить вычислительные затраты, демонстрируя эффективность на задачах MaxCut и оценки основного состояния для гамильтониана Швингера. Способен ли предложенный алгоритм стать основой для разработки эффективных квантовых алгоритмов, адаптированных к современным промежуточным квантовым устройствам?
В поисках Истинного Интеллекта: Вызов Сложности
Разработка по-настоящему интеллектуальных агентов неразрывно связана с их способностью принимать надежные решения в сложных, динамично меняющихся условиях. Такие агенты должны не просто реагировать на текущую ситуацию, но и прогнозировать последствия своих действий, учитывать множество взаимосвязанных факторов и адаптироваться к неожиданным обстоятельствам. Успех в этой области требует создания алгоритмов, способных эффективно обрабатывать большие объемы информации, находить оптимальные стратегии в условиях неопределенности и обучаться на собственном опыте, что значительно превосходит возможности традиционных подходов к искусственному интеллекту. Способность к надежному принятию решений является краеугольным камнем для создания агентов, способных автономно функционировать и решать сложные задачи в реальном мире.
Традиционные подходы к созданию интеллектуальных агентов, такие как основанные на жестко запрограммированных правилах или ограниченных алгоритмах поиска, зачастую демонстрируют недостаточную масштабируемость и адаптивность в сложных, динамично меняющихся средах. Эти методы, эффективные в узкоспециализированных задачах, быстро теряют свою функциональность при увеличении объема данных или при появлении новых, непредвиденных ситуаций. Ограниченность в способности к обобщению и переобучению препятствует созданию агентов, способных эффективно функционировать в реальном мире, где информация неполна, а обстоятельства постоянно меняются. Таким образом, существующие решения, несмотря на определенные успехи, не позволяют в полной мере реализовать потенциал интеллектуальных систем и требуют разработки принципиально новых подходов, способных к самообучению и адаптации к неопределенности.
Коллективный Разум: Многоагентное Обучение с Подкреплением
Многоагентное обучение с подкреплением (MARL) представляет собой расширение традиционного обучения с подкреплением, в котором несколько агентов взаимодействуют в общей среде и обучаются совместно для достижения общей цели. В отличие от классического RL, где один агент оптимизирует политику для максимизации вознаграждения, MARL предполагает, что каждый агент разрабатывает собственную политику, учитывая действия и политики других агентов. Это создает более сложную задачу обучения, поскольку пространство состояний и действий значительно увеличивается, а также возникает необходимость в механизмах координации и коммуникации между агентами. MARL находит применение в задачах, где требуется коллективное принятие решений, таких как робототехника, управление транспортными потоками и сетевые игры.
Алгоритм QMIX представляет собой мощный фреймворк в многоагентном обучении с подкреплением (MARL), сочетающий в себе преимущества децентрализованного выполнения и централизованного обучения. В процессе обучения, централизованный критик использует глобальное состояние и действия всех агентов для оценки общей ценности, что позволяет более эффективно координировать действия агентов. В отличие от полностью децентрализованных подходов, QMIX позволяет избежать проблемы неоптимальных стратегий, возникающих из-за ограниченной информации у каждого агента. При выполнении, агенты действуют независимо, используя локальные наблюдения и собственные стратегии, полученные в процессе обучения. Это сочетание обеспечивает масштабируемость и устойчивость системы, сохраняя при этом возможность эффективной координации действий для достижения общей цели.
Эффективное обучение с подкреплением для мультиагентных систем (MARL) критически зависит от точного определения пространства действий каждого агента и разработки адекватной структуры сигнала вознаграждения. Пространство действий определяет набор возможных действий, доступных агенту в каждой ситуации, и его неправильное определение может ограничить возможности обучения и привести к субоптимальным решениям. Сигнал вознаграждения, в свою очередь, должен четко отражать желаемое поведение агентов и стимулировать сотрудничество или конкуренцию, в зависимости от поставленной задачи. Неправильно спроектированный сигнал вознаграждения может привести к нежелательным побочным эффектам или к тому, что агенты будут оптимизировать не ту метрику. Оптимальное проектирование этих двух компонентов требует тщательного анализа задачи и понимания взаимодействия между агентами, а также часто требует итеративного подхода с экспериментальной валидацией.

Автоматизированный Дизайн: Квантовый Поиск Архитектур
Поиск квантовой архитектуры (QAS) использует возможности обучения с подкреплением для автоматического обнаружения оптимальных конструкций квантовых схем. В основе QAS лежит итеративный процесс, в котором агент обучения с подкреплением исследует различные конфигурации квантовых цепей, оценивая их производительность на задаче. Агент получает вознаграждение за конструкции, демонстрирующие улучшенные результаты, и использует эти сигналы для корректировки своей стратегии и дальнейшего улучшения дизайна схемы. Этот подход позволяет автоматизировать процесс, традиционно требующий значительных усилий и экспертных знаний в области квантовых вычислений, и потенциально находить решения, превосходящие те, что разработаны вручную.
Исследования, применяющие поиск квантовой архитектуры (QAS) к задачам ‘Max-Cut’ и модели Швингера, направлены на оценку эффективности данного подхода в решении сложных оптимизационных проблем. Задача ‘Max-Cut’ представляет собой классическую задачу комбинаторной оптимизации, требующую разделения вершин графа на два подмножества таким образом, чтобы максимизировать число ребер, соединяющих эти подмножества. Модель Швингера, в свою очередь, является моделью квантовой электродинамики, используемой для изучения взаимодействия частиц и полей. Применение QAS к этим задачам позволяет оценить способность алгоритма автоматически находить оптимальные квантовые схемы для решения проблем, которые сложно решить традиционными методами, и служит эталоном для оценки производительности QAS в различных областях.
Применение подхода квантового архитектурного поиска (QAS) на базе многоагентного обучения с подкреплением (MARL) позволило добиться приблизительно 5-кратного сокращения количества шагов обучения по сравнению с методами обучения с подкреплением с одним агентом. Данное снижение было продемонстрировано при решении задач Max-Cut и модели Швингера, что указывает на повышенную эффективность MARL-QAS в задачах оптимизации квантовых схем. Сокращение вычислительных затрат является ключевым преимуществом, особенно при масштабировании алгоритмов QAS для более сложных проблем.

Оптимизация Квантовых Схем: Усиление Производительности
Вариационные квантовые алгоритмы (ВКА) представляют собой инновационный гибридный подход к решению сложных вычислительных задач, объединяющий сильные стороны классических и квантовых вычислений. В отличие от полностью квантовых алгоритмов, требующих масштабных квантовых компьютеров, ВКА используют квантовую схему с настраиваемыми параметрами, оптимизируемыми с помощью классических методов. Квантовая часть алгоритма, выполняемая на квантовом процессоре, генерирует вероятностные результаты, которые затем анализируются классическим компьютером. Этот процесс итеративно повторяется, подстраивая параметры квантовой схемы до достижения оптимального решения. Такой гибридный подход позволяет эффективно использовать доступные квантовые устройства, даже при наличии шума и ограниченном количестве кубитов, открывая новые возможности для решения задач в химии, материаловедении и машинном обучении.
Параметризованные квантовые схемы, в сочетании с оптимизатором ADAM и подходом «Hardware Efficient Ansatz», представляют собой эффективный инструмент для обучения квантовых алгоритмов на современных, несовершенных квантовых устройствах. Данный метод позволяет минимизировать сложность квантовых схем, используя операции, которые наиболее эффективно реализуются на конкретном оборудовании. Оптимизатор ADAM, основанный на градиентном спуске, оперативно адаптирует параметры схемы, стремясь к минимизации целевой функции. Такое сочетание позволяет значительно ускорить процесс обучения и добиться высокой точности результатов, несмотря на ограничения, связанные с шумом и когерентностью кубитов. В результате, параметризованные схемы с ADAM и “Hardware Efficient Ansatz” открывают путь к практическому применению квантовых вычислений в задачах, где требуется оптимизация и машинное обучение, даже на доступных сегодня квантовых платформах.
Исследование, посвященное оптимизации квантовых схем, демонстрирует значительные улучшения в эффективности за счет подхода MARL-QAS. В рамках изучения модели Швингера, данный метод позволил снизить количество необходимых управляемых-НЕ (CNOT) вентилей примерно на 50% по сравнению со стандартным Hardware Efficient Ansatz (HEA). При этом, MARL-QAS не только сокращает вычислительную сложность, но и существенно уменьшает количество вариационных параметров, необходимых для достижения сопоставимой точности аппроксимации. Это достигается за счет интеллектуального выбора структуры квантовой схемы и оптимизации ее параметров, что делает MARL-QAS перспективным инструментом для реализации сложных квантовых алгоритмов на ближайших квантовых устройствах и открывает новые возможности для решения задач, ранее недоступных из-за ограничений аппаратных ресурсов.

Будущее Интеллектуальных Систем: Квантовый Скачок
Распределенные квантовые вычисления представляют собой ключевой фактор масштабирования квантовых алгоритмов, таких как квантовый отжиг () и вариационные квантовые алгоритмы (), для решения задач, ранее недоступных из-за вычислительных ограничений. Вместо создания единого, чрезвычайно мощного квантового компьютера, эта парадигма предполагает объединение нескольких, относительно небольших квантовых процессоров посредством квантовых сетей. Такой подход позволяет эффективно распределять вычислительную нагрузку, обходить ограничения по количеству кубитов в одном устройстве и значительно увеличить скорость решения сложных оптимизационных задач, моделирования молекул и анализа больших объемов данных. По мере развития технологий квантовых сетей и повышения надежности квантовых процессоров, распределенные квантовые вычисления откроют возможности для решения проблем в области логистики, машинного обучения и финансового моделирования, требующих экспоненциальных вычислительных ресурсов.
Сочетание мультиагентного обучения с подкреплением (MARL) и квантовых алгоритмов открывает путь к созданию интеллектуальных агентов, способных решать задачи, ранее считавшиеся неразрешимыми. В то время как MARL позволяет агентам учиться взаимодействовать и координировать свои действия в сложных средах, квантовые алгоритмы предоставляют экспоненциальное ускорение вычислений, необходимое для обработки огромных объемов данных и оптимизации стратегий. Это симбиотическое взаимодействие позволяет агентам эффективно исследовать пространство решений, находить оптимальные стратегии и адаптироваться к динамически меняющимся условиям, что особенно важно в задачах, требующих высокой степени сложности и неопределенности, таких как моделирование финансовых рынков или разработка новых материалов с заданными свойствами. В перспективе, подобные системы способны превзойти возможности классических алгоритмов и совершить прорыв в решении наиболее сложных научных и инженерных задач.
Синергия между квантовыми алгоритмами и обучением с подкреплением, основанным на мультиагентном подходе, открывает беспрецедентные возможности для прорывных исследований в различных областях. В частности, в сфере разработки лекарственных препаратов, эта комбинация позволит моделировать молекулярные взаимодействия с беспрецедентной точностью, значительно ускоряя процесс поиска новых терапевтических средств. В материаловедении, предсказание свойств материалов на основе квантовых вычислений позволит создавать инновационные материалы с заданными характеристиками. Финансовое моделирование, в свою очередь, получит возможность более эффективно оценивать риски и оптимизировать инвестиционные стратегии, используя сложные квантовые алгоритмы для анализа больших объемов данных. Таким образом, данный подход обещает революционизировать эти и многие другие сферы, предоставляя инструменты для решения задач, ранее считавшихся неразрешимыми.

Исследование демонстрирует стремление к оптимизации квантовых архитектур посредством распределенного обучения с подкреплением. Авторы предлагают систему, где агенты совместно проектируют квантовые схемы, сокращая время обучения и повышая эффективность. Это напоминает подход к взлому сложной системы: разделение задачи на более мелкие, управляемые компоненты, каждый из которых оптимизируется независимо, а затем интегрируется в единое целое. Как заметил Джон Белл: «Если вы не можете объяснить что-то простыми словами, значит, вы сами этого не понимаете». В данном случае, упрощение процесса проектирования квантовых схем через распределенное обучение — это и есть попытка донести сложность до уровня, доступного для практической реализации. Каждый патч в алгоритме — философское признание несовершенства изначальной модели.
Куда Ведет Этот Кроличий Нора?
Представленный подход к поиску квантовых архитектур, использующий обучение с подкреплением на основе мультиагентных систем, обнажает интересную закономерность: скорость освоения ландшафта возможностей зачастую превосходит скрупулезность заранее заданных правил. Однако, сама суть «оптимальности» квантовой схемы, полученной таким путем, требует более глубокого анализа. Не является ли ускорение обучения лишь иллюзией, маскирующей поиск локального, а не глобального минимума? Реальное преимущество проявится лишь при столкновении с задачами, требующими не просто скорости, но и устойчивости к шуму, неизбежному на текущих квантовых устройствах.
Очевидным направлением для дальнейших исследований представляется интеграция механизмов, позволяющих агентам обмениваться не только информацией о полученных результатах, но и о своих внутренних представлениях о пространстве поиска. Иными словами, необходимо перейти от простого «копирования успешных стратегий» к формированию коллективного «понимания» квантовой задачи. В конечном счете, истинный прогресс заключается не в автоматизации процесса проектирования, а в создании систем, способных к самообучению и адаптации к постоянно меняющимся условиям.
Наконец, следует признать, что представленный подход — это лишь один из возможных путей. Вероятно, наиболее эффективным окажется не конкуренция различных методов, а их симбиоз, сочетающий в себе преимущества обучения с подкреплением, эволюционных алгоритмов и даже, возможно, элементов случайного поиска. Ведь, как известно, хаос иногда оказывается более продуктивным, чем порядок.
Оригинал статьи: https://arxiv.org/pdf/2511.22708.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.