Квантовые технологии
Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
Автор: Денис Аветисян
Исследователи представили инновационную нейронную сеть, вдохновленную принципами квантовых вычислений, которая значительно повышает эффективность обучения с учителем.
В статье представлена архитектура Quantum Decision Transformer (QDT), объединяющая запутанность и многопутевые нейронные сети для улучшения алгоритмов обучения с учителем.
Несмотря на успехи обучения с подкреплением из статических наборов данных, существующие архитектуры, такие как Decision Transformer, испытывают трудности с долгосрочным планированием и сложными зависимостями между состояниями и действиями. В работе ‘Quantum Decision Transformers (QDT): Synergistic Entanglement and Interference for Offline Reinforcement Learning’ представлена новая архитектура, вдохновленная принципами квантовых вычислений, объединяющая квантово-вдохновленное внимание и многопутевые сети прямого распространения для значительного повышения эффективности обучения. Эксперименты демонстрируют, что предложенный Quantum Decision Transformer превосходит стандартные модели более чем в 20 раз, благодаря синергии между компонентами, захватывающими нелокальные корреляции и обеспечивающими адаптивное распределение ресурсов. Может ли такой подход к проектированию нейронных сетей, основанный на квантовых принципах, открыть новые горизонты в области последовательного принятия решений и архитектуры нейронных сетей в целом?
Преодоление Сложности: Обучение с Подкреплением в Реальных Условиях
Традиционные методы обучения с подкреплением зачастую требуют обширного взаимодействия со средой, что делает их применение в реальных условиях затруднительным. Для эффективной работы алгоритму необходимо совершить множество проб и ошибок, исследуя различные варианты действий и оценивая полученные результаты. Однако, во многих практических задачах, таких как управление роботами или оптимизация медицинских протоколов, активное исследование может быть дорогостоящим, опасным или попросту невозможным. Например, обучение автономного автомобиля путем реальных аварий недопустимо, а длительное тестирование новых лекарственных препаратов на пациентах неэтично. В связи с этим, возникает потребность в алгоритмах, способных эффективно обучаться на ограниченном объеме данных и без необходимости постоянного взаимодействия с внешней средой, что открывает путь к более безопасным и экономичным решениям в области искусственного интеллекта.
Основная сложность обучения с подкреплением в реальных условиях заключается в эффективном использовании офлайн-данных, где последовательность действий и их результаты уже определены. В отличие от традиционных методов, предполагающих активное взаимодействие со средой и исследовательское поведение, офлайн-обучение требует извлечения полезных знаний из статических наборов данных. Это представляет собой значительную проблему, поскольку алгоритм лишен возможности самостоятельно оценивать последствия различных стратегий и должен полагаться исключительно на существующие примеры. Ограниченность данных и потенциальная предвзятость в выборке действий усложняют задачу обобщения и требуют разработки инновационных подходов к оценке ценности действий и построению оптимальной политики без возможности проведения дополнительных экспериментов в среде.
Эффективное решение задачи последовательного принятия решений в условиях ограниченных данных требует разработки принципиально новых подходов к распределению ответственности за полученные результаты и обобщению опыта. Традиционные методы часто сталкиваются с трудностями при определении того, какие конкретно действия привели к тому или иному исходу, особенно когда данных недостаточно для статистически значимых выводов. Инновационные алгоритмы, такие как методы, основанные на оценке контрфактических сценариев, позволяют оценивать влияние каждого действия, даже в отсутствие достаточной информации. Более того, применение техник переноса обучения и мета-обучения позволяет обобщать знания, полученные из похожих задач или сред, что существенно повышает эффективность обучения на ограниченных данных и позволяет агентам быстро адаптироваться к новым ситуациям. Успех в этой области открывает возможности для применения обучения с подкреплением в критически важных областях, где активное взаимодействие с окружающей средой затруднено или невозможно.
Революция в Обучении: Decision Transformers как Новый Подход
Трансформеры решений (Decision Transformers) представляют собой новый подход к обучению с подкреплением, переосмысливающий задачу как проблему последовательного моделирования, решаемую с помощью архитектуры трансформеров. Вместо традиционного обучения агента взаимодействию со средой для максимизации вознаграждения, Decision Transformers рассматривают траектории как последовательности пар «состояние-действие». Это позволяет использовать существующие наборы данных, собранные ранее, для обучения политики без необходимости в активном сборе данных и взаимодействии со средой. Архитектура трансформера, изначально разработанная для обработки естественного языка, эффективно моделирует зависимости между состояниями, действиями и желаемыми результатами, что позволяет предсказывать оптимальные действия на основе предшествующей истории и целевых значений.
В основе Decision Transformer лежит обучение модели предсказывать будущие действия, основываясь на последовательности прошлых состояний и желаемой суммарной награды, кодируемой сигналом «Return-to-Go». Вместо традиционного обучения с подкреплением, требующего взаимодействия со средой, Decision Transformer использует исключительно статические наборы данных. Сигнал Return-to-Go представляет собой разницу между желаемой суммарной наградой и накопленной наградой на текущем шаге, что позволяет модели учитывать долгосрочные цели при выборе действий. Таким образом, задача обучения сводится к задаче последовательного моделирования, где модель обучается предсказывать следующее действие, учитывая историю состояний и желаемую награду, избегая необходимости в прямом взаимодействии со средой и позволяя эффективно использовать офлайн данные.
В основе обучения Decision Transformer лежит использование пар “Состояние-Действие” () в качестве базового элемента. Вместо традиционных методов обучения с подкреплением, требующих взаимодействия со средой, Decision Transformer анализирует статические наборы данных, состоящие из последовательностей состояний, действий и полученных наград. Обрабатывая эти данные, модель учится предсказывать оптимальные действия, соответствующие заданным желаемым возвратам (Return-to-Go), основываясь на текущем состоянии. Такой подход позволяет эффективно строить устойчивые политики, используя только исторические данные, без необходимости в онлайн-обучении или исследованиях в реальном времени, что особенно важно при ограниченном доступе к среде или высокой стоимости взаимодействия с ней.
Вдохновение Квантовой Механики: Новые Горизонты Представления Данных
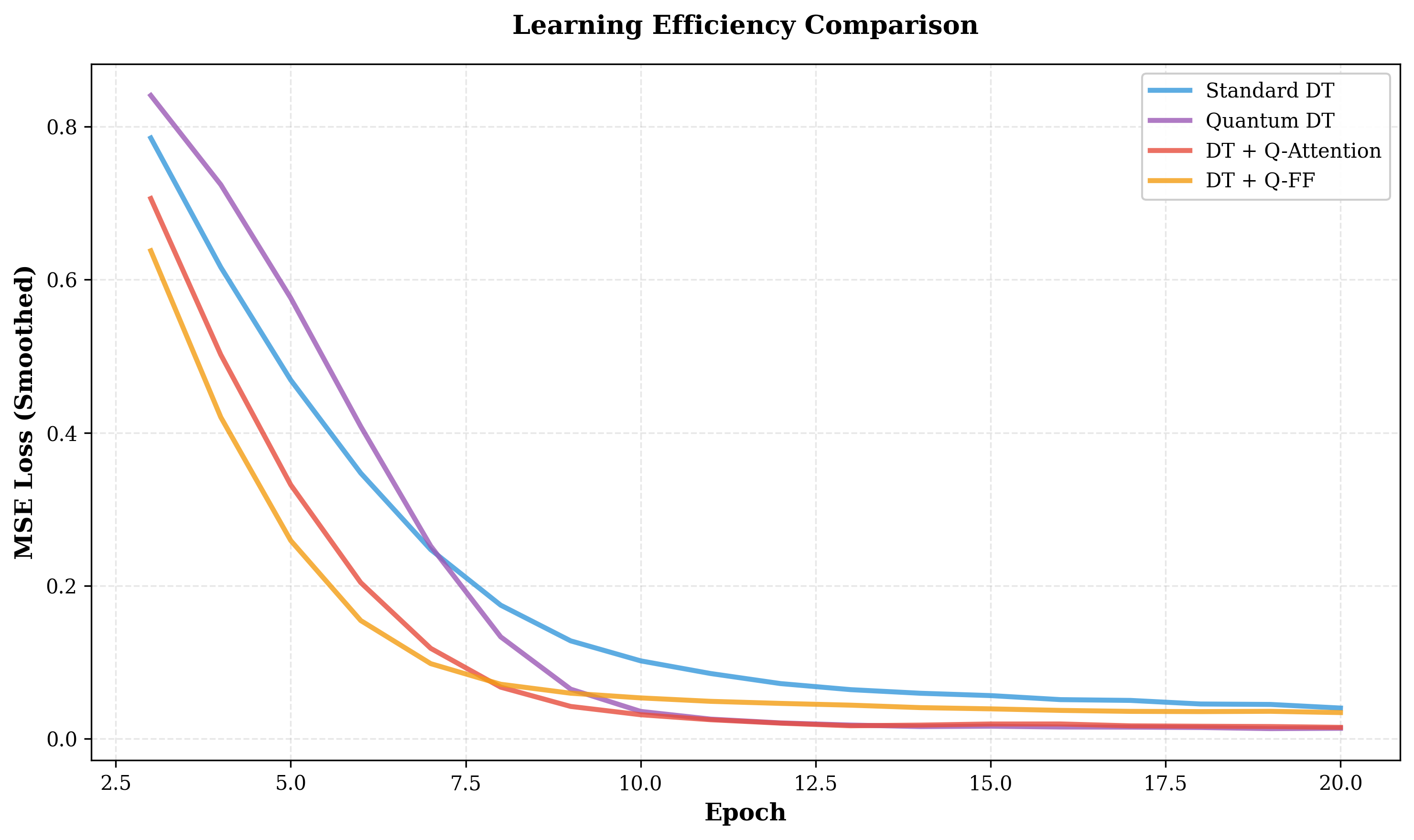
Вдохновение, черпаемое из квантовой механики, а именно принципов суперпозиции, запутанности и интерференции, предоставляет новые возможности для разработки более эффективных и выразительных методов обучения представлений. Принцип суперпозиции позволяет одновременно исследовать множество возможных состояний, что потенциально ускоряет процесс обучения. Запутанность, в свою очередь, позволяет улавливать сложные взаимозависимости между признаками, формируя более полное представление о данных. Использование интерференции позволяет усиливать полезные сигналы и подавлять шум, что повышает точность и устойчивость модели. Такой подход направлен на создание моделей, способных к более гибкому и компактному представлению информации, что особенно важно при работе с высокоразмерными данными и сложными задачами машинного обучения.
Сеть использует принцип для параллельного исследования различных вариантов представления данных. Этот подход имитирует квантовую суперпозицию, позволяя сети одновременно оценивать множество гипотез и путей решения задачи. Реализация достигается за счет создания множественных путей обработки информации, каждый из которых исследует отдельную возможность. Взаимодействие между этими путями осуществляется через механизм , который усиливает перспективные варианты и подавляет менее эффективные, подобно интерференции волн в квантовой механике. Данный метод позволяет значительно расширить пространство поиска и повысить эффективность обучения по сравнению с традиционными однопутевыми нейронными сетями.
В архитектуре сети используется операция “EntanglementOperation” для моделирования квантового запутывания, что позволяет улавливать сложные взаимосвязи между признаками входных данных. В отличие от традиционных методов, где признаки обрабатываются независимо, данная операция создает зависимости между ними, позволяя сети лучше понимать и представлять состояние пространства. Это достигается путем комбинирования признаков таким образом, чтобы изменение одного признака влияло на представление других, что приводит к более полному и контекстуально-зависимому представлению данных. Использование «EntanglementOperation» позволяет сети эффективно кодировать информацию о взаимосвязях между признаками, что особенно полезно в задачах, где эти взаимосвязи критически важны для принятия решений.
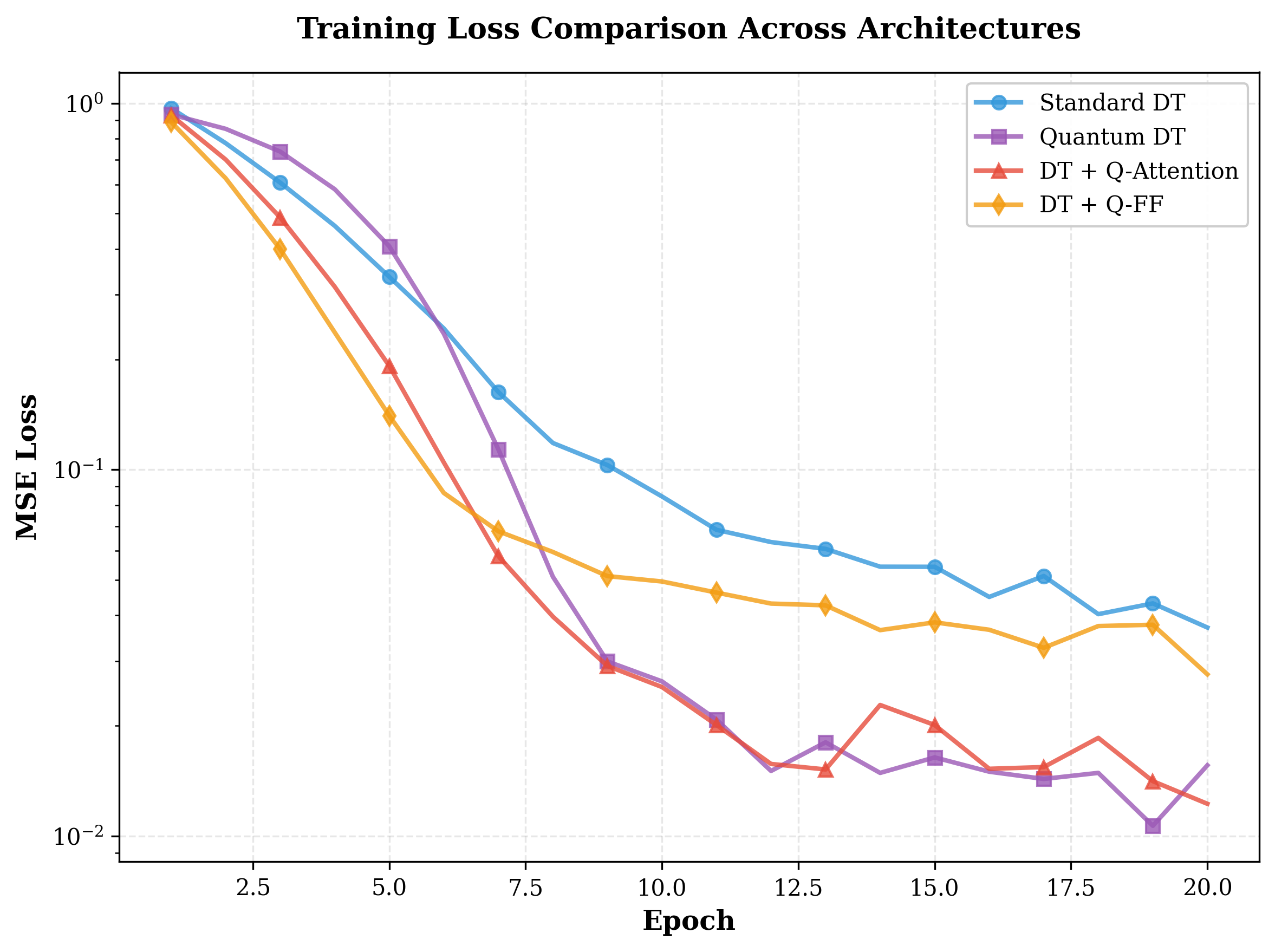
Квантовые механизмы, включающие в себя принципы суперпозиции, запутанности и интерференции, были интегрированы в архитектуру QuantumDecisionTransformer. В результате, данный агент обучения с подкреплением в автономном режиме (offline RL) демонстрирует значительное улучшение производительности по сравнению со стандартными Decision Transformers. Экспериментальные данные показывают, что QuantumDecisionTransformer достигает более чем 2000%-ного увеличения возврата (return) в ряде тестовых сред, что свидетельствует о повышенной эффективности и адаптивности агента к сложным задачам обучения без взаимодействия со средой в процессе обучения.
Влияние Квантовых Принципов: Эффективность и Параметрическая Экономия
Механизм внимания, вдохновленный принципами квантовой механики, использует фазовую кодировку для интеграции временных и реляционных структур данных. В отличие от традиционных методов, где информация обрабатывается последовательно, фазовая кодировка позволяет одновременно учитывать взаимосвязи между различными элементами последовательности и их позицией во времени. Этот подход позволяет модели более эффективно улавливать тонкие зависимости и контекст, что приводит к значительному улучшению способности к обработке информации. В основе лежит представление данных в виде , где фаза кодирует информацию о временных и реляционных характеристиках, обеспечивая компактное и информативное представление данных для последующей обработки.
Механизм внимания, обогащенный принципами квантовой физики, способен выявлять скрытые зависимости в данных, которые остаются незамеченными для традиционных методов. Комбинация фазового кодирования и операций, имитирующих квантовую запутанность, позволяет модели учитывать не только непосредственные связи между элементами, но и более тонкие, контекстуальные отношения. Фазовое кодирование вводит информацию о временной последовательности и относительных позициях элементов, а операции, вдохновленные квантовой запутанностью, создают возможность для параллельной обработки и выявления корреляций между отдаленными частями входных данных. Это позволяет механизму внимания формировать более полное и нюансированное представление о входной информации, что критически важно для решения сложных задач, где даже незначительные детали могут иметь решающее значение.
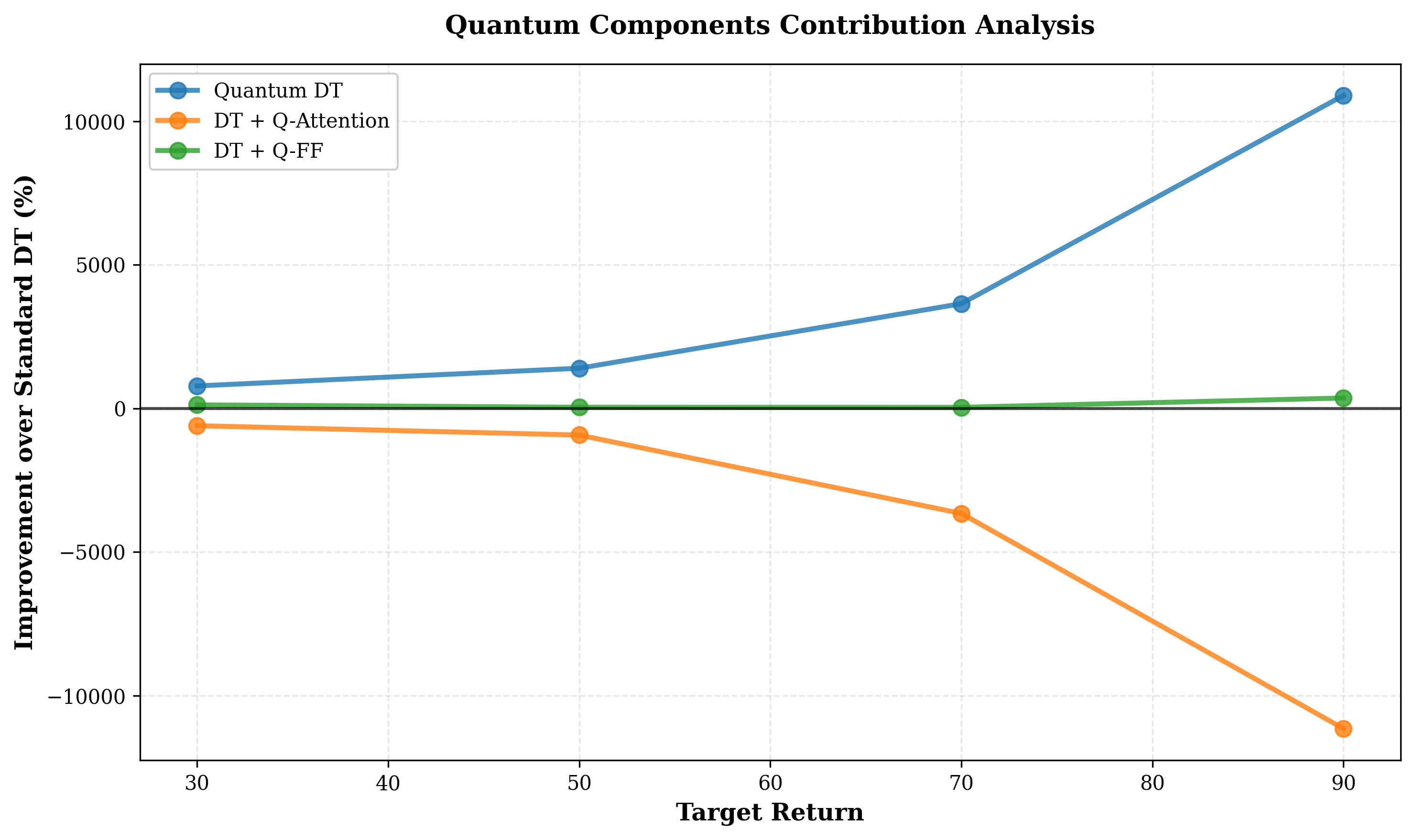
Исследования показали, что разработанный ‘QuantumDecisionTransformer’ демонстрирует значительное улучшение результатов в задачах обучения с подкреплением в автономном режиме. В ходе экспериментов была достигнута награда в 2600 единиц, что свидетельствует о более эффективной стратегии принятия решений. Примечательно, что это повышение производительности сопровождается существенным снижением потерь при обучении — на 58%, с до . Данный результат указывает на способность модели не только быстрее обучаться, но и достигать более стабильных и предсказуемых результатов, что делает её перспективным инструментом для решения сложных задач в области искусственного интеллекта и автоматизации.
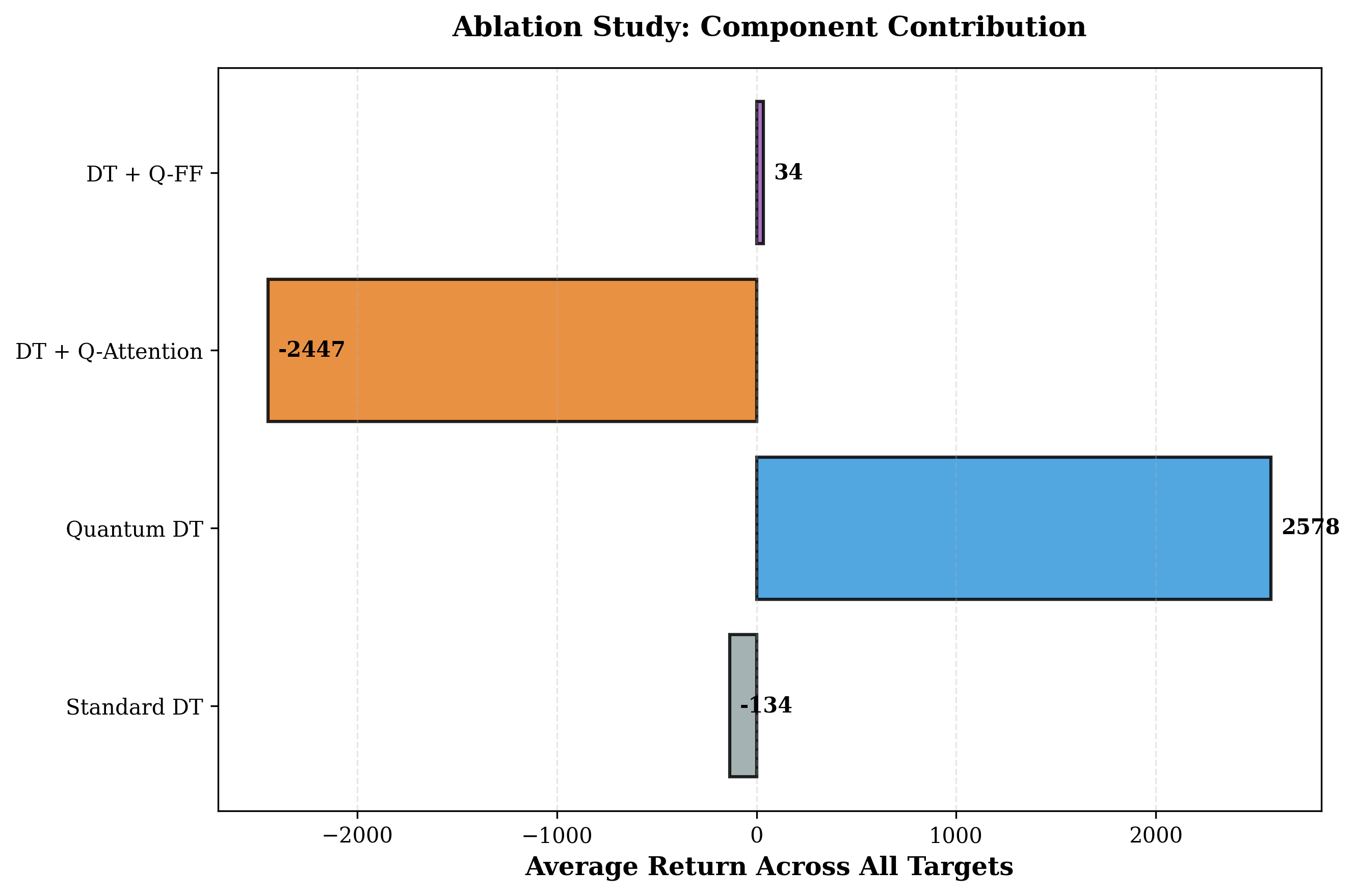
Особо значимым результатом представленного подхода является существенное повышение параметрической эффективности. Эксперименты продемонстрировали, что разработанная система превосходит лучшие отдельные компоненты, такие как квантический прямой проход (), в целых 73 раза. Это означает, что для достижения аналогичного уровня производительности требуется значительно меньше вычислительных ресурсов и параметров модели, что открывает возможности для применения в условиях ограниченной памяти и вычислительной мощности. Подобная эффективность не только снижает затраты на обучение и эксплуатацию, но и способствует созданию более компактных и быстрых систем искусственного интеллекта.
Представленная работа демонстрирует стремление к упрощению сложной задачи обучения с подкреплением. Авторы предлагают архитектуру Quantum Decision Transformer, вдохновлённую принципами квантовых вычислений, для повышения эффективности обучения в режиме офлайн. Это соответствует убеждению, что ясность структуры — форма сострадания к читающему. Как однажды заметил Пауль Эрдеш: «Математика — это искусство находить закономерности, которые не очевидны». Подобно этому, предложенная архитектура стремится выявить скрытые закономерности в данных офлайн обучения, используя принципы запутанности и интерференции для улучшения кредитного назначения и, следовательно, повышения производительности модели.
Что дальше?
Предложенная архитектура, хотя и демонстрирует улучшения в обучении с подкреплением из статических данных, не решает фундаментальную проблему: сложность по-прежнему маскируется под прогрессом. Замена классических механизмов внимания на «квантово-вдохновлённые» аналоги не является самоцелью. Вопрос в том, насколько эффективно эта архитектура оборачивает вычислительные затраты в реальное преимущество над более простыми, но тщательно настроенными решениями.
Дальнейшие исследования должны сосредоточиться не на усложнении, а на упрощении. Необходимо выяснить, какие конкретно аспекты «квантовой» аналогии действительно способствуют улучшению кредитного распределения, а какие являются лишь декоративными элементами. В частности, представляется важным исследовать возможности адаптации предложенных принципов к другим архитектурам, лишенным избыточности.
Возможно, истинный путь вперед заключается не в имитации квантовых явлений, а в более глубоком понимании принципов обучения, лежащих в основе способности к обобщению. Иногда лучшее решение — это не найти новое, а забыть лишнее.
Оригинал статьи: https://arxiv.org/pdf/2512.14726.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.