Статьи QuantRise
LIMO: Ускорение вычислений на грани возможностей
Автор: Денис Аветисян
Новая архитектура энергоэффективных вычислений в памяти открывает перспективы для оптимизации и нейросетей на периферийных устройствах.
Представлен LIMO — макрос для энергоэффективных вычислений в памяти, использующий STT-MRAM и пространственную архитектуру для ускорения задач комбинаторной оптимизации и нейросетевых вычислений.
Комбинаторные задачи оптимизации, лежащие в основе широкого спектра приложений от логистики до разработки электроники, часто сталкиваются с ограничениями, связанными с «узким местом памяти» на традиционных архитектурах. В данной работе, посвященной разработке ‘LIMO: Low-Power In-Memory-Annealer and Matrix-Multiplication Primitive for Edge Computing’, представлен новый подход к решению этой проблемы, основанный на аппаратном и алгоритмическом со-дизайне для вычислений в памяти. Предлагаемая система LIMO использует стохастическое переключение магнитных туннельных переходов (STT-MTJ) и пространственную архитектуру для ускорения алгоритма имитации отжига и повышения качества решения задач оптимизации, а также для эффективной реализации векторно-матричных умножений. Возможно ли, таким образом, создать энергоэффективные платформы для выполнения как сложных оптимизационных задач, так и задач машинного обучения непосредственно на периферийных устройствах?
Комбинаторный Хаос и Его Последствия
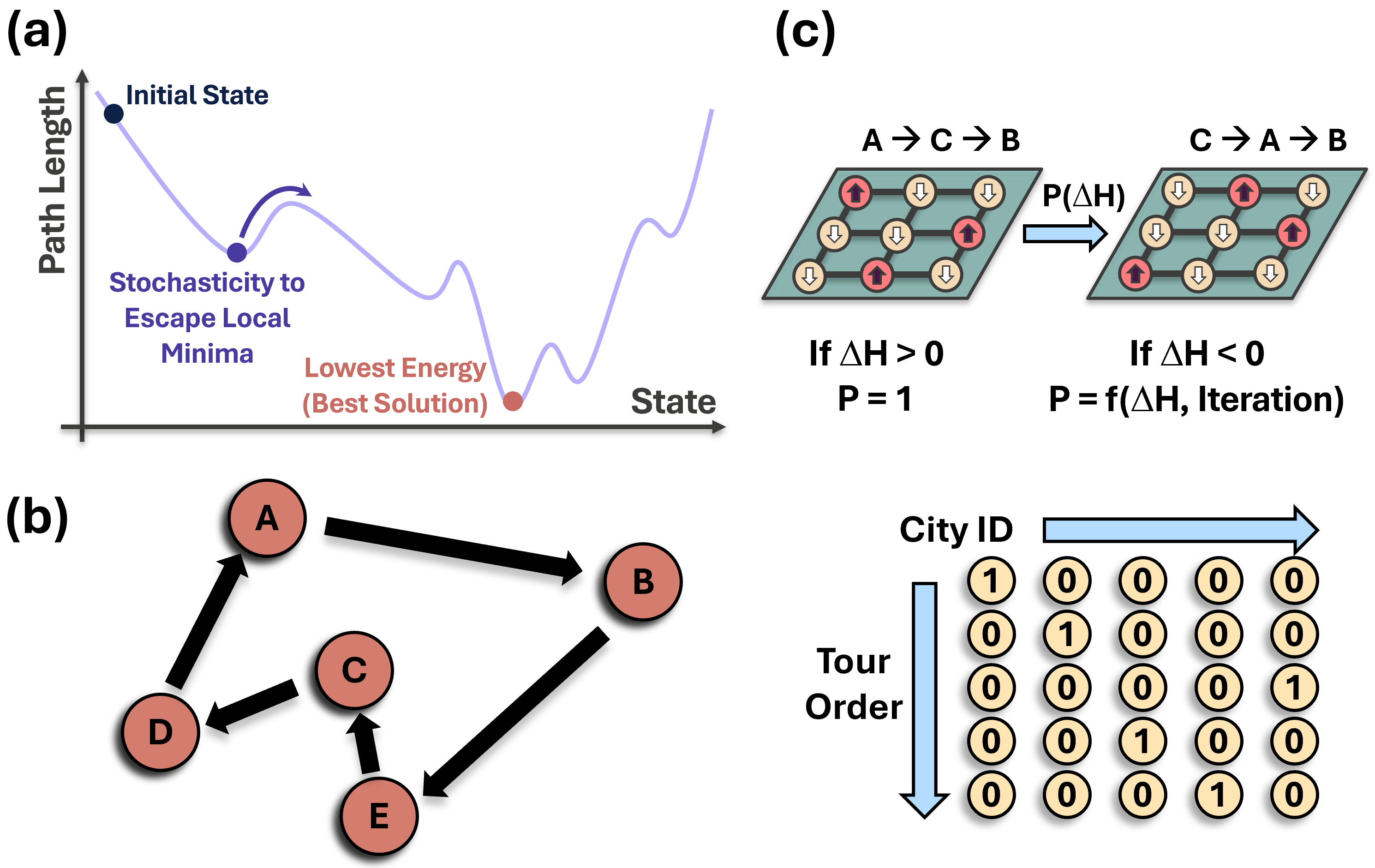
Многие задачи, с которыми сталкивается современная наука и техника, относятся к классу NP-полных комбинаторных оптимизаций, что означает их принципиальную сложность в решении. Примером служит знаменитая задача коммивояжера — поиск кратчайшего маршрута, проходящего через заданный набор городов. Рост числа возможных комбинаций с увеличением количества элементов в задаче приводит к экспоненциальному увеличению времени, необходимого для нахождения оптимального решения даже с использованием самых мощных вычислительных ресурсов. Эта проблема не ограничивается лишь теоретическими построениями; она оказывает существенное влияние на логистику, планирование, проектирование и многие другие практические области, требуя разработки инновационных подходов к оптимизации и приближенных алгоритмов.
Традиционные алгоритмы, применяемые для решения сложных задач, часто сталкиваются с проблемой масштабируемости. По мере увеличения размера решаемой задачи, пространство возможных решений растет экспоненциально, что приводит к резкому увеличению времени вычислений и потребляемых ресурсов. Например, задача о коммивояжере, требующая нахождения кратчайшего маршрута через заданный набор городов, демонстрирует эту проблему особенно ярко: с добавлением каждого нового города количество возможных маршрутов увеличивается в разы, делая полный перебор вариантов невозможным даже для умеренно большого числа городов. В результате, применение стандартных алгоритмов становится непрактичным, требуя разработки новых подходов, способных эффективно справляться с экспоненциальным ростом сложности вычислений и находить приближенные решения за приемлемое время.
Эвристические Подходы и Уточнение Алгоритмов
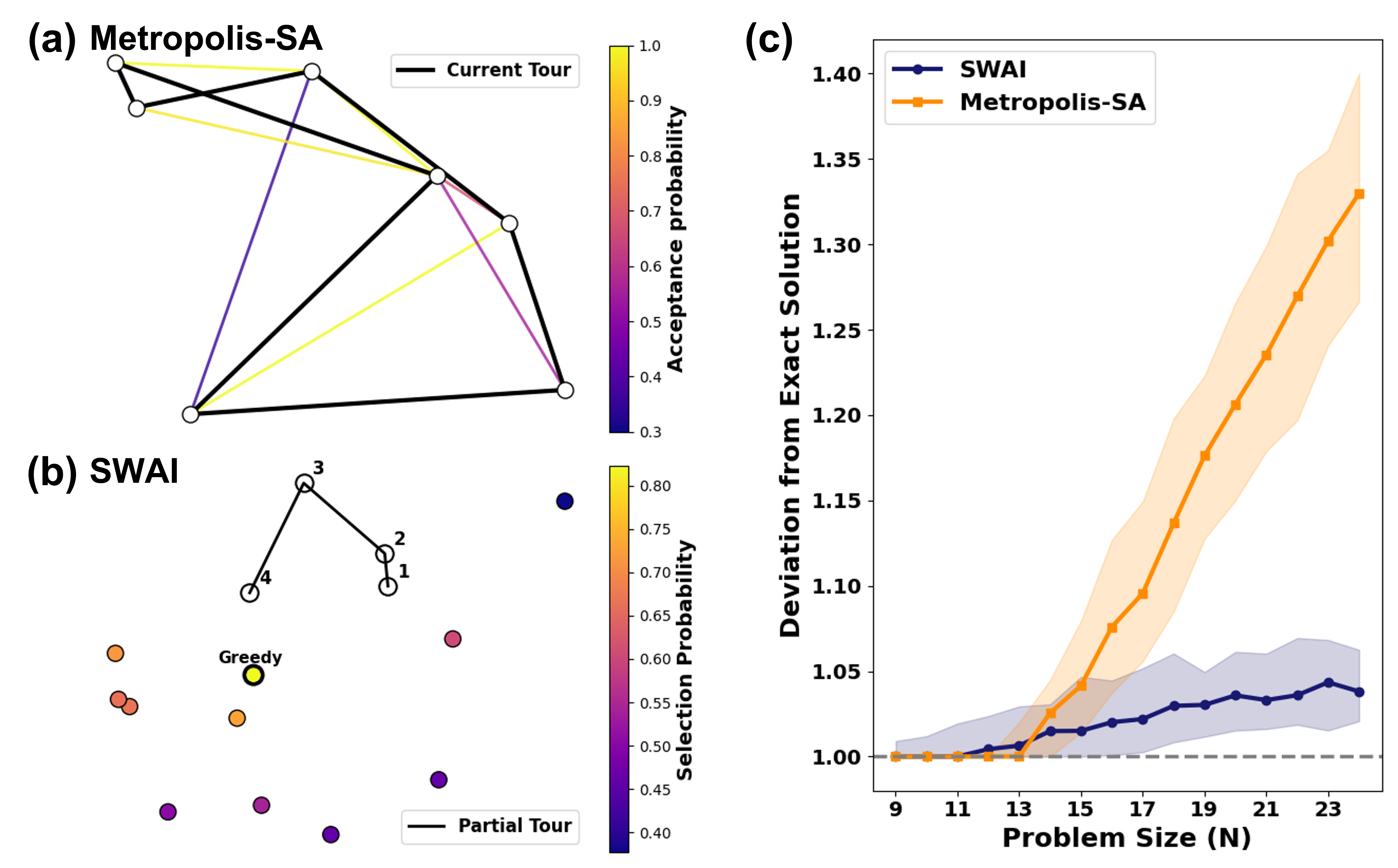
Имитация отжига представляет собой вероятностный метод исследования пространства решений, основанный на аналогии с процессом отжига металлов. Алгоритм допускает принятие решений, ухудшающих текущее решение (так называемые “шаги вверх”), с определенной вероятностью, зависящей от “температуры” и величины ухудшения. Эта возможность принятия субоптимальных шагов позволяет алгоритму избегать застревания в локальных оптимумах, исследуя более широкую область пространства решений. Вероятность принятия “шага вверх” уменьшается по мере снижения “температуры”, что способствует сближению алгоритма к глобальному оптимуму на поздних этапах работы. В отличие от детерминированных методов, имитация отжига не гарантирует нахождение оптимального решения, но обеспечивает высокую вероятность получения хорошего решения за разумное время.
Метод значимо взвешенной вставки (Significance Weighted Annealing Insertion) представляет собой усовершенствование алгоритма имитации отжига, направленное на повышение эффективности поиска решения. В отличие от стандартного имитации отжига, где все допустимые ходы рассматриваются с равной вероятностью, данный метод оценивает потенциальное влияние каждого хода на общую стоимость решения. Ходы, приводящие к более существенному улучшению целевой функции, получают больший вес и, следовательно, более высокую вероятность принятия, даже если они временно увеличивают стоимость решения. Это позволяет алгоритму быстрее сходиться к оптимальному или близкому к оптимальному решению, особенно в задачах с большим пространством поиска и сложной функцией стоимости.
Параллельная обработка данных, использующая методы, такие как PCA-бисекция, значительно ускоряет процесс поиска решения за счет декомпозиции исходной задачи на несколько более мелких, независимо решаемых подзадач. PCA-бисекция, в частности, позволяет разделить пространство поиска, основываясь на главных компонентах, что обеспечивает параллельное исследование различных областей и снижает общую вычислительную сложность. Эффективность параллелизации напрямую зависит от степени декомпозиции и возможности независимой обработки подзадач, а также от архитектуры используемого вычислительного оборудования и оптимизации коммуникаций между процессами.
Преодоление «Узкого Места фон Неймана»
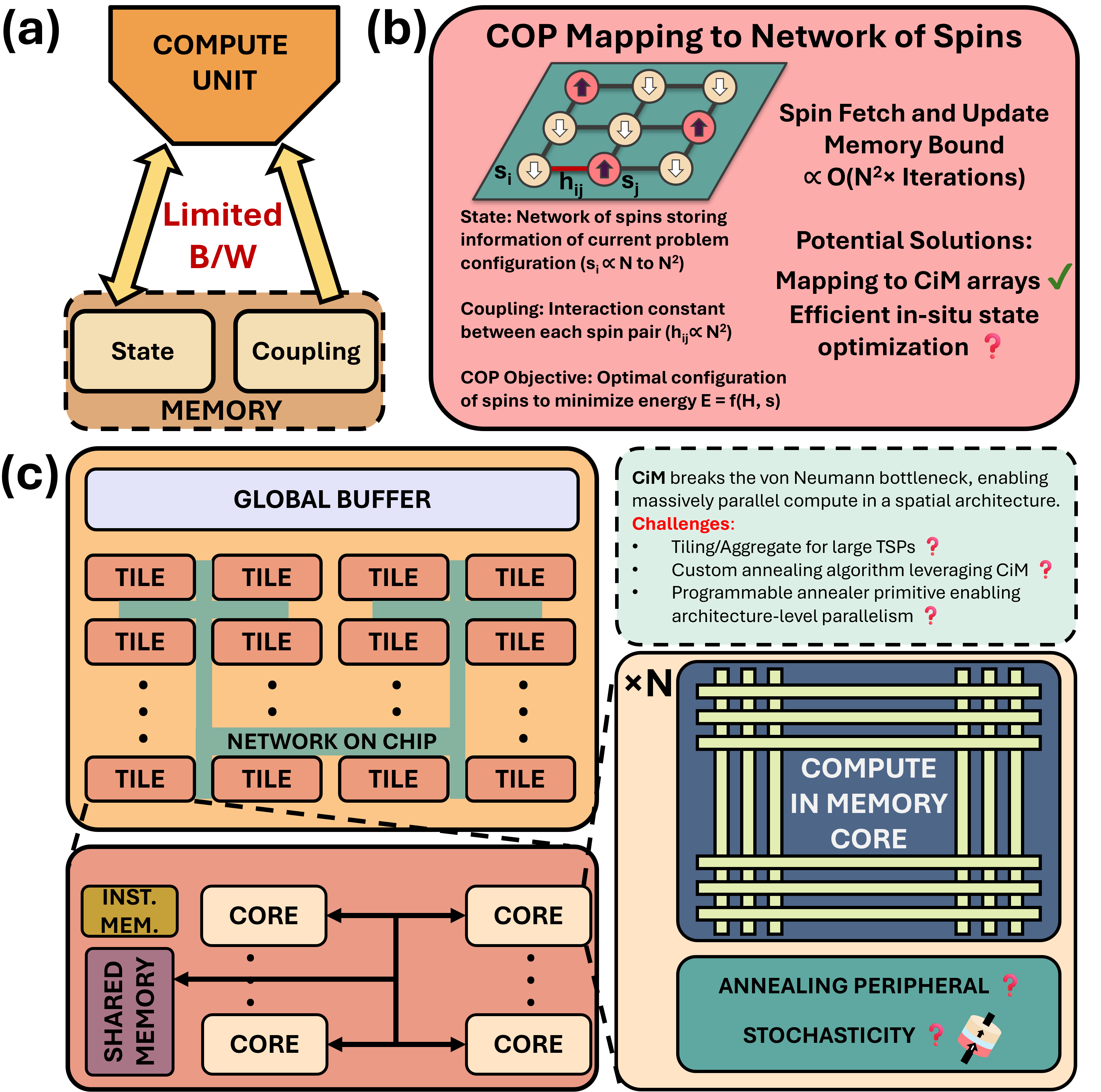
Классическая архитектура фон Неймана, характеризующаяся физическим разделением блоков обработки и памяти, создает узкое место в передаче данных. Необходимость постоянного перемещения данных между процессором и памятью для выполнения операций ограничивает скорость вычислений и общую пропускную способность системы. Это ограничение становится критичным при обработке больших объемов данных, характерных для современных приложений, таких как машинное обучение и анализ данных, где пропускная способность памяти является определяющим фактором производительности. Задержки, связанные с передачей данных, существенно снижают эффективность вычислительных ресурсов, даже при использовании высокоскоростной памяти.
Вычисления в памяти (CIM) представляют собой принципиально новый подход, который позволяет выполнять операции непосредственно внутри массива памяти, устраняя необходимость в постоянном перемещении данных между процессором и памятью. Традиционная архитектура фон Неймана страдает от ограниченной пропускной способности шины данных, что становится узким местом при обработке больших объемов информации. CIM минимизирует этот обмен данными, значительно снижая энергопотребление и увеличивая общую производительность вычислительной системы. Реализация CIM позволяет существенно сократить задержки и повысить скорость обработки данных, особенно в задачах, требующих интенсивных матричных операций, таких как машинное обучение и обработка изображений.
Для реализации вычислений непосредственно в памяти (Compute-in-Memory, CIM) требуется использование энергонезависимых типов памяти нового поколения, таких как STT-MRAM (Spin-Transfer Torque Magnetoresistive Random-Access Memory). В отличие от традиционной DRAM и SRAM, STT-MRAM обеспечивает более высокую плотность хранения, низкое энергопотребление и, что критически важно для CIM, возможность выполнения логических операций непосредственно в ячейках памяти за счет изменения магнитной поляризации. Это достигается за счет управляемого изменения сопротивления ячейки, что позволяет выполнять операции умножения-накопления (MAC) и другие вычисления без перемещения данных между памятью и процессором, тем самым обходя ограничение, накладываемое архитектурой фон Неймана.
LIMO Macro: Пространственная Архитектура для Ускоренных Вычислений
Разработанный макрос LIMO представляет собой малопотребляющую вычислительную схему смешанного типа, предназначенную для ускорения как алгоритмов оптимизации, основанных на имитации отжига, так и процессов вывода нейронных сетей. Данное решение объединяет в себе преимущества аналого-цифровой обработки сигналов, позволяя эффективно решать сложные вычислительные задачи, требующие высокой скорости и минимального энергопотребления. Уникальная архитектура макроса позволяет одновременно обрабатывать большое количество данных, существенно превосходя по производительности традиционные цифровые схемы при решении задач оптимизации и обеспечивая сопоставимую точность с программными реализациями при выполнении задач нейросетевого вывода. Таким образом, LIMO открывает новые возможности для реализации энергоэффективных вычислительных систем, способных решать широкий спектр задач в различных областях, от логистики и маршрутизации до машинного обучения и искусственного интеллекта.
В основе разработки LIMO Macro лежит принципиально новый подход к вычислениям — пространственная архитектура. Вместо последовательной обработки данных, макрос использует множество параллельно работающих вычислительных элементов, связанных между собой для одновременного выполнения операций. Это позволяет значительно ускорить решение сложных задач, таких как оптимизация и машинное обучение. Ключевым элементом эффективности является использование троичного умножения весов, которое снижает вычислительную нагрузку и энергопотребление за счет упрощения операций над данными. Такой подход позволяет обрабатывать большие объемы информации с высокой скоростью и минимальными затратами энергии, открывая новые возможности для разработки энергоэффективных вычислительных систем.
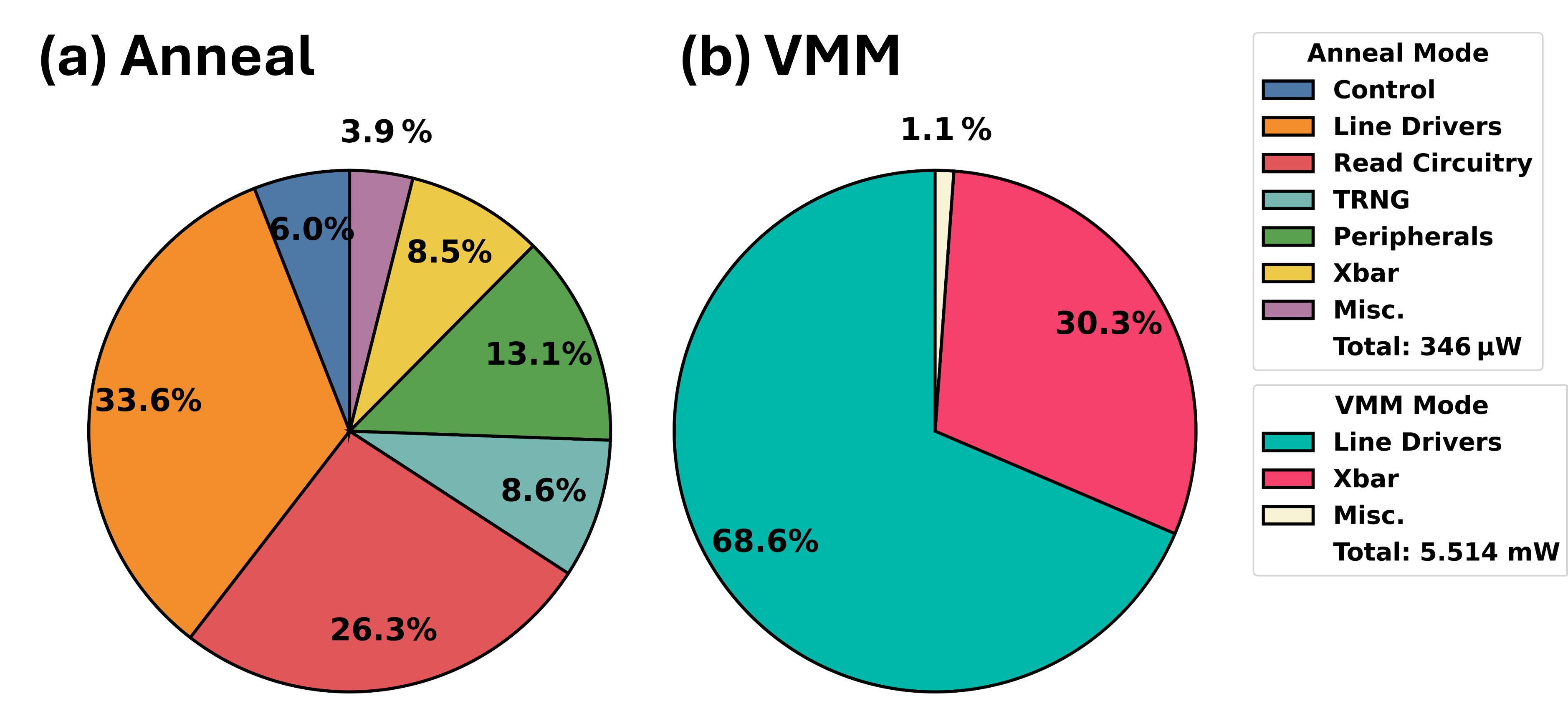
Макроархитектура LIMO интегрирует последовательно-аппроксимационный АЦП (SAR-ADC) для преобразования аналоговых сигналов в цифровые, что позволяет эффективно обрабатывать данные в задачах оптимизации и машинного обучения. Для моделирования и верификации данной пространственной архитектуры используется платформа PUMA, обеспечивающая всесторонний анализ и оптимизацию производительности. В результате подобной интеграции и оптимизации, макроархитектура LIMO демонстрирует значительное улучшение качества решений в задачах оптимизации, в частности, достигается в среднем на 37.5% более высокое качество решений для задачи коммивояжера (TSP) по сравнению с современными аппаратными отжигателями. Это свидетельствует о существенном прогрессе в области аппаратного ускорения сложных вычислительных задач.
Разработанная вычислительная макросхема LIMO демонстрирует существенный прирост производительности в задачах оптимизации и нейронных вычислениях. В частности, при решении задачи коммивояжера для 85 900 городов, LIMO обеспечивает пятикратное ускорение по сравнению с существующими аппаратными решениями. При этом потребление энергии снижается в пятнадцать раз. Более того, LIMO достигает сопоставимой точности с программными реализациями при выполнении задач сверточных нейронных сетей, что подтверждает эффективность предложенной пространственной архитектуры и возможности ее применения в широком спектре вычислительных задач, требующих высокой скорости и энергоэффективности.
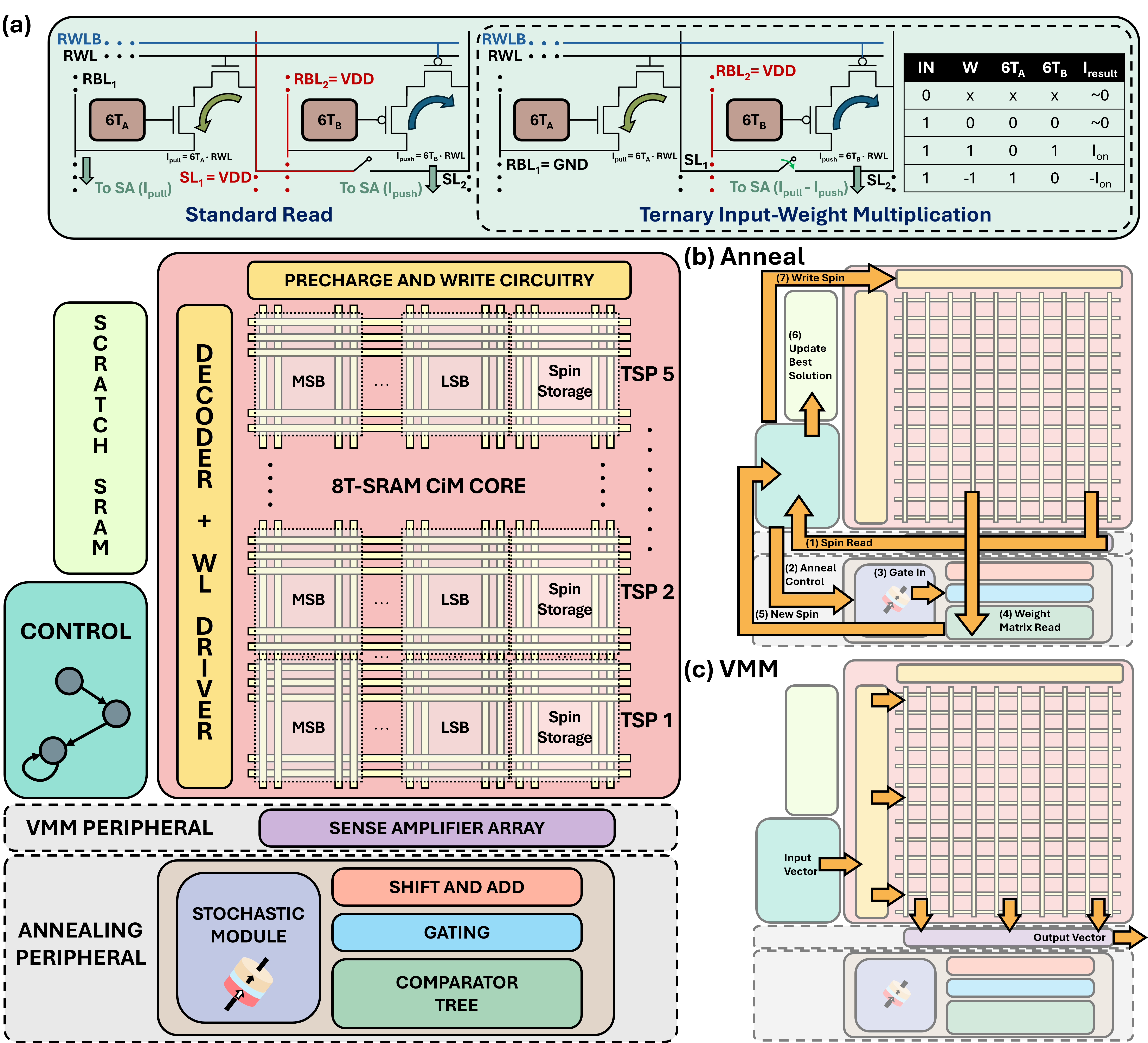
Представленное исследование LIMO, стремящееся к оптимизации энергопотребления при выполнении комбинаторных задач и нейросетевых вычислений, вызывает закономерный скепсис. Утверждения о революционности аппаратного обеспечения, использующего STT-MRAM, кажутся знакомыми — каждая новая технология неизбежно превращается в технический долг, требующий постоянного обслуживания и доработки. Как справедливо заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не влияли на другие». Однако, в реальности, стремление к оптимизации часто приводит к созданию сложных, взаимосвязанных систем, где даже незначительное изменение может вызвать каскад проблем. И, конечно, не обойдется без последующих оправданий о «непредвиденных обстоятельствах» и «недостаточной документации». Сейчас это назовут AI-ускорителем и получат инвестиции.
Что дальше?
Представленное решение, как и все прочие, лишь отодвигает проблему, а не решает её. Ускорение комбинаторной оптимизации и нейронных сетей на периферии — задача, конечно, важная. Но стоит помнить, что каждый новый уровень абстракции требует всё более сложных механизмов отладки и верификации. STT-MRAM, эта прелесть энергоэффективности, рано или поздно начнёт выдавать непредсказуемые ошибки, и тогда все эти «пространственные архитектуры» превратятся в тыкву.
Вместо того, чтобы гнаться за архитектурными чудесами, возможно, стоит вернуться к более фундаментальным вопросам. Например, насколько вообще оправдано переносить сложные алгоритмы на периферию? Не проще ли отправлять данные туда, где есть вычислительные ресурсы и инструменты для их обработки? Но нет, нужно всё усложнить.
В конечном итоге, как показывает опыт, все эти «инновации» — лишь старое в новой обёртке, с худшей документацией и более сложными зависимостями. Потом окажется, что всё работало, пока не подключили очередную библиотеку. И снова нужно разбираться, что сломалось. Впрочем, это и есть суть нашей работы, не так ли?
Оригинал статьи: https://arxiv.org/pdf/2512.23212.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.