Искусственный интеллект
Оптимизация регистрации облаков точек на встраиваемых GPU: динамическое распределение памяти
Автор: Денис Аветисян
Новая стратегия динамического выделения памяти позволяет существенно ускорить процесс регистрации облаков точек на встраиваемых графических процессорах, сохраняя высокую производительность.

Представлен метод динамического распределения памяти для алгоритма ICP на основе дилатации, позволяющий снизить потребление памяти более чем на 97%.
Несмотря на растущую потребность в высокопроизводительной регистрации облаков точек, существующие алгоритмы часто требуют значительных аппаратных ресурсов. В данной работе, посвященной ‘A dynamic memory assignment strategy for dilation-based ICP algorithm on embedded GPUs’, предложена оптимизация использования памяти для алгоритма VANICP, предназначенного для встраиваемых графических процессоров. Разработанная динамическая стратегия распределения памяти позволяет снизить потребление памяти более чем на 97% без потери производительности. Возможно ли дальнейшее расширение предложенного подхода для реализации еще более эффективных алгоритмов обработки облаков точек на ограниченных аппаратных платформах?
Понимание Проблемы: Регистрация Облаков Точек
Точная регистрация облаков точек является фундаментальной задачей для широкого спектра приложений трехмерного восприятия, включая робототехнику, автономное вождение и создание трехмерных моделей. Однако, традиционные методы, несмотря на свою теоретическую обоснованность, часто сталкиваются с трудностями в обеспечении как высокой скорости обработки, так и устойчивости к шумам и неполноте данных. Проблема усугубляется с увеличением объема облаков точек, получаемых современными сенсорами, что требует разработки новых, более эффективных алгоритмов, способных обеспечить надежную и быструю регистрацию даже в сложных условиях. Неспособность оперативно и точно зарегистрировать облака точек может привести к значительным ошибкам в последующих этапах обработки и, как следствие, к неверным решениям в критически важных приложениях.
Алгоритм итеративного поиска ближайших точек (ICP) по-прежнему является фундаментальным инструментом в задачах регистрации облаков точек, однако его вычислительная сложность резко возрастает с увеличением размера набора данных. В основе ICP лежит последовательное уточнение трансформации между двумя облаками точек путем многократного поиска соответствий между ближайшими точками. Каждая итерация требует вычисления расстояний между всеми парами точек, что приводит к сложности, где — количество точек в облаке. В результате, обработка больших облаков точек, генерируемых современными 3D-сканерами, становится непомерно затратной по времени и ресурсам, ограничивая его применение в задачах реального времени, таких как автономная навигация и робототехника. Поэтому, разработка более эффективных алгоритмов, способных снизить вычислительную нагрузку ICP, является важной задачей в области трехмерного компьютерного зрения.
Поиск ближайших соседей в больших облаках точек представляет собой ключевое препятствие для приложений, требующих обработки данных в реальном времени. Сложность алгоритмов поиска, как правило, растет нелинейно с увеличением количества точек — например, наивный поиск требует операций, где — количество точек. Это делает обработку больших наборов данных крайне затратной по времени и вычислительным ресурсам. В результате, даже с использованием оптимизированных структур данных, таких как k-d деревья или октальные деревья, поиск ближайших соседей остается узким местом во многих задачах, включая 3D-реконструкцию, робототехнику и автономное вождение, ограничивая возможность оперативной обработки и анализа данных.

Ускорение Поиска: Стратегии Эффективности
Для повышения эффективности поиска ближайших соседей по сравнению с полным перебором (brute-force), используются различные структуры данных. K-D Tree представляет собой бинарное дерево, где каждый узел разделяет пространство по одной координате, что позволяет быстро исключать целые поддеревья из поиска. Local Sensitive Hashing (LSH) использует хеш-функции, которые с большей вероятностью отображают близкие точки в одинаковые «корзины», снижая количество сравниваемых точек. Иерархические графы строятся на основе кластеризации данных, позволяя осуществлять поиск на разных уровнях детализации и быстро находить ближайших соседей в пределах кластера. Каждая из этих структур данных обеспечивает компромисс между потреблением памяти и скоростью поиска, что делает их применимыми в различных сценариях обработки больших объемов данных.
Использование структур данных, таких как K-D Tree, Locality Sensitive Hashing и иерархические графы, для поиска ближайших соседей предполагает компромисс между объемом используемой памяти и скоростью поиска. Вместо полного перебора всех точек облака точек (brute-force search), эти методы предварительно организуют данные в структуры, требующие дополнительной памяти для хранения индексов и связей. Это позволяет значительно сократить количество точек, которые необходимо проверить при поиске, что приводит к ускорению обработки больших облаков точек, особенно в задачах, требующих высокой производительности и реального времени. Увеличение использования памяти компенсируется снижением вычислительных затрат и, как следствие, уменьшением времени отклика.
Вокселизация представляет собой метод пространственного индексирования, заключающийся в разделении трехмерного пространства на дискретные воксели — кубические элементы фиксированного размера. Этот подход позволяет значительно сократить область поиска ближайших соседей за счет исключения из рассмотрения вокселей, не содержащих искомые точки. Эффективность вокселизации напрямую зависит от размера вокселя: более мелкие воксели обеспечивают большую точность, но требуют больше памяти и вычислительных ресурсов, в то время как более крупные воксели снижают вычислительную нагрузку, но могут привести к пропуску ближайших соседей. Применение вокселизации особенно эффективно при обработке больших облаков точек, где прямой перебор всех точек непрактичен.

VANICP: Оптимизация на Основе Дилатации
VANICP — это метод итеративного ближайшего соответствия (ICP), использующий дилатацию для преобразования глобального поиска ближайших соседей в локализованный процесс. Вместо рассмотрения всех точек в исходном облаке, VANICP применяет операцию дилатации, расширяя окрестность каждой точки в целевом облаке. Это позволяет значительно уменьшить область поиска ближайшего соответствия для каждой точки, повышая эффективность и устойчивость алгоритма регистрации. Дилатация задается параметром, определяющим размер расширенной окрестности, что позволяет контролировать баланс между скоростью и точностью регистрации.
Метод VANICP использует дилатацию для эффективного уменьшения пространства поиска ближайших соседей при регистрации облаков точек. Применение дилатации позволяет расширить область поиска вокруг текущей точки, что снижает вероятность выбора неверного соответствия, особенно в областях с низкой плотностью данных или значительным шумом. Это приводит к повышению устойчивости процесса регистрации к выбросам и неточностям измерений, поскольку алгоритм рассматривает более широкий контекст при установлении соответствий между точками в исходном и целевом облаках. Фактически, дилатация преобразует задачу глобального поиска ближайших соседей в локализованный процесс, существенно снижая вычислительную сложность и повышая надежность регистрации.
В методе VANICP реализовано динамическое распределение памяти, позволяющее значительно оптимизировать её использование. В отличие от статической стратегии, где объём памяти выделяется заранее и может быть неэффективно использован, динамическое распределение выделяет память по мере необходимости. Экспериментальные данные демонстрируют, что данная оптимизация позволяет снизить потребление памяти более чем на 97% по сравнению со статической аллокацией, что особенно важно при работе с большими наборами данных и ограниченными ресурсами памяти.
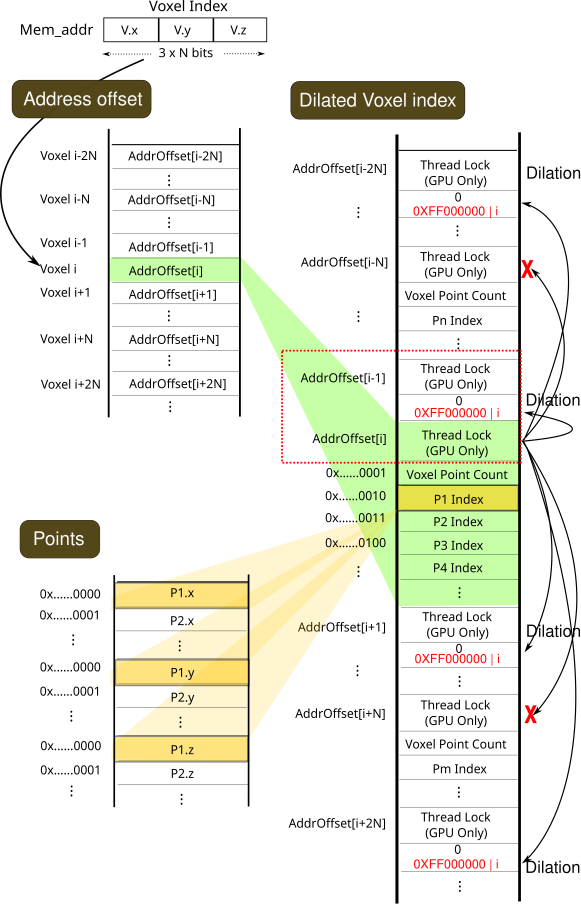
Результаты и Валидация на Реальных Данных
Исследования, проведенные на общепризнанных наборах данных, таких как ModelNet, Stanford Bunny и TUM RGB-D, демонстрируют превосходство VANICP в отношении скорости и точности по сравнению с существующими методами. В ходе экспериментов было установлено, что предложенный алгоритм не только обеспечивает более высокую точность регистрации облаков точек, но и существенно превосходит конкурентов по времени вычислений. Эти результаты подтверждают эффективность VANICP в решении задач компьютерного зрения и робототехники, требующих быстрой и надежной обработки трехмерных данных, и указывают на его потенциал для использования в широком спектре практических приложений, где критичны как точность, так и скорость работы.
Исследования показали, что разработанный метод демонстрирует повышенную устойчивость и эффективность работы с облаками точек различной плотности и при наличии шумов. В ходе тестирования на различных моделях удалось достичь значительной экономии энергии, варьирующейся от 16.4% до 58.63%. Это свидетельствует о потенциале метода для применения в ресурсоограниченных средах и задачах, требующих длительной автономной работы, где снижение энергопотребления играет ключевую роль. Полученные результаты подтверждают, что предложенный подход не только повышает точность обработки данных, но и способствует более рациональному использованию энергетических ресурсов.
Реализация разработанного метода VANICP на встраиваемых GPU-платформах, таких как Jetson AGX Xavier, и специализированных FPGA-устройствах демонстрирует значительный потенциал для приложений, требующих обработки данных в реальном времени. В частности, FPGA-реализация показала наивысшую скорость работы среди всех протестированных методов, что открывает возможности для создания высокопроизводительных систем компьютерного зрения, способных эффективно обрабатывать потоки данных непосредственно на устройстве. Это особенно важно для автономных роботов, беспилотных летательных аппаратов и других мобильных устройств, где ограничения по энергопотреблению и вычислительным ресурсам являются критическими факторами.
Исследование, представленное в статье, демонстрирует важность оптимизации использования памяти при работе с облаками точек на встроенных графических процессорах. Авторы предлагают динамическую стратегию выделения памяти, позволяющую значительно сократить потребление ресурсов без потери производительности. Этот подход перекликается с мыслями Яна ЛеКуна: “Машины должны учиться понимать мир, а не просто запоминать его.” В контексте данной работы, эффективное управление памятью позволяет системе “понимать” структуру данных и адаптироваться к её особенностям, что особенно важно для ограниченных ресурсов встроенных систем. Подобная оптимизация позволяет создавать более эффективные и масштабируемые решения для задач регистрации облаков точек, приближая нас к созданию интеллектуальных систем, способных к адаптации и обучению.
Куда двигаться дальше?
Представленная стратегия динамического распределения памяти, безусловно, демонстрирует значительное снижение потребления ресурсов при регистрации облаков точек на встраиваемых графических процессорах. Однако, необходимо признать, что оптимизация памяти — это лишь одна грань сложной проблемы. Вопрос о границах применимости данного подхода к различным плотностям и размерам облаков точек остается открытым. Тщательная проверка этих границ критически важна для избежания ложных закономерностей и гарантии надежности алгоритма в реальных условиях.
Будущие исследования должны сосредоточиться на адаптивном управлении разрешением вокселизации. Статичный подход к разрешению может оказаться неоптимальным для облаков точек с переменной плотностью. Более того, взаимодействие между динамическим распределением памяти и алгоритмами поиска ближайших соседей заслуживает более глубокого изучения. Возможно, существуют компромиссы, позволяющие еще больше повысить эффективность, учитывая специфику архитектуры встраиваемых GPU.
В конечном счете, стремление к оптимизации алгоритмов регистрации облаков точек — это не только техническая задача, но и философский поиск баланса между точностью, скоростью и потреблением ресурсов. Понимание этой системы требует не просто улучшения отдельных компонентов, а исследования закономерностей, определяющих её поведение в целом.
Оригинал статьи: https://arxiv.org/pdf/2512.04996.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.