Статьи QuantRise
Раскрывая потенциал языковых моделей: новый взгляд на оценку
Автор: Денис Аветисян
- Преодолевая Узкое Горлышко Промпт-Инжиниринга
- Автоматизация Оптимизации Промптов: Новый Подход
- Композиция Модульных Промптов с DSPy: Гибкость и Переиспользование
- Подтверждение Эффективности на Разнообразных Бенчмарках
- К Более Надёжным и Интеллектуальным Системам: Перспективы Развития
- Куда Ведет Эта Дорога?
Исследование показывает, что стандартные методы оценки производительности языковых моделей могут быть неточными и непоследовательными, требуя более комплексного подхода.

В статье предложен метод структурированного промптинга и автоматической оптимизации запросов для получения более надежных и репрезентативных результатов бенчмаркинга.
Несмотря на растущее распространение больших языковых моделей, стандартные методы оценки часто дают неполную картину их возможностей. В работе ‘Structured Prompting Enables More Robust, Holistic Evaluation of Language Models’ показано, что использование фиксированных запросов может занижать производительность моделей и вносить искажения в сравнительные оценки. Авторы предлагают подход, основанный на структурированных запросах и автоматической оптимизации, позволяющий более точно измерить потенциал моделей и получить надежные результаты бенчмаркинга. Можно ли создать действительно объективные и репрезентативные оценки языковых моделей, учитывающие вариативность в дизайне запросов и максимизирующие их производительность?
Преодолевая Узкое Горлышко Промпт-Инжиниринга
Несмотря на значительный прогресс в развитии языковых моделей, достижение оптимальной производительности напрямую зависит от тщательно разработанных запросов, или промптов. Эффективность модели не раскрывается в полной мере, если запрос сформулирован неточно или не учитывает особенности её архитектуры. Продуманный промпт выступает в роли своеобразного «ключа», активирующего скрытые возможности модели и позволяющего получить наиболее релевантный и точный ответ. Иными словами, даже самая мощная языковая модель нуждается в грамотной «инструкции», чтобы продемонстрировать свой потенциал, а процесс создания этих инструкций требует значительных усилий и экспертных знаний.
Традиционная разработка промптов представляет собой трудоемкий и отнимающий много времени процесс, требующий от специалистов ручного подбора и тестирования различных формулировок. Этот подход существенно ограничивает масштабируемость, поскольку для каждой конкретной задачи или нюанса необходимо проводить отдельную оптимизацию. Вследствие этого, полноценное исследование пространства возможных промптов, способных раскрыть весь потенциал языковых моделей, становится практически невозможным. Особенно остро эта проблема проявляется при решении сложных задач, требующих многоступенчатого рассуждения и детальной настройки входных данных. В результате, даже самые передовые модели зачастую работают не на полную мощность, поскольку оптимальный промпт, способный максимально раскрыть их возможности, так и не найден.
Ручное составление запросов представляет собой существенное ограничение в раскрытии полного потенциала современных языковых моделей, особенно при решении сложных задач, требующих логического мышления. Исследования показывают, что существующие методы оценки производительности этих моделей занижают реальные возможности примерно на 4%, поскольку их результаты крайне чувствительны к формулировке запроса. Это означает, что даже незначительные изменения в тексте запроса могут привести к значительному колебанию ответов, что затрудняет объективное сравнение различных моделей и выявление оптимальных решений. Таким образом, преодоление этой зависимости от ручной настройки запросов является ключевой задачей для дальнейшего развития и внедрения языковых моделей в различные сферы применения.
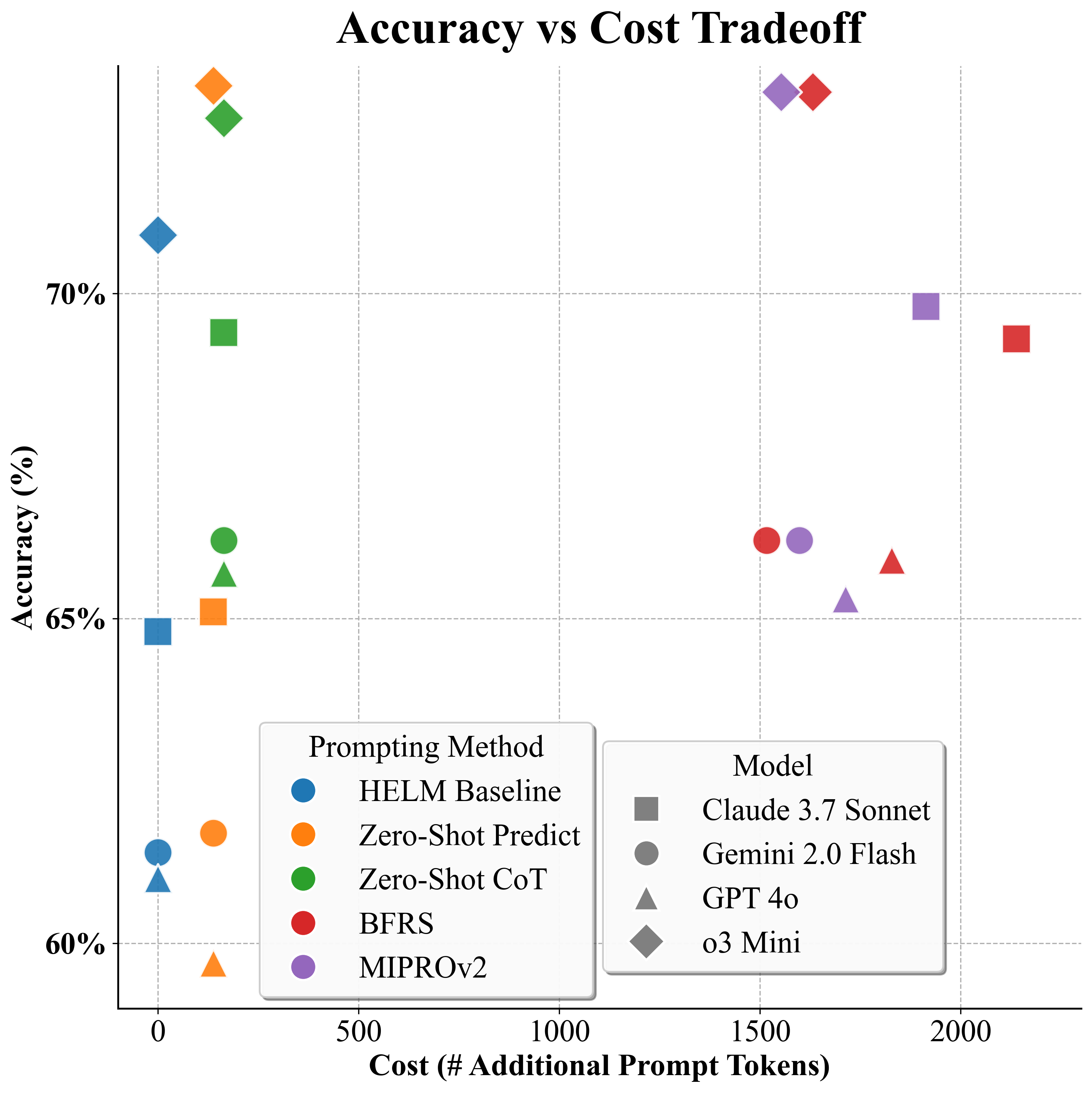
Автоматизация Оптимизации Промптов: Новый Подход
Автоматическая оптимизация промптов (APO) представляет собой принципиальный сдвиг в подходе к разработке входных запросов для больших языковых моделей. Вместо ручного конструирования, APO рассматривает процесс создания промпта как задачу поиска оптимальной конфигурации входных данных, направленную на максимизацию производительности модели. Этот подход позволяет рассматривать пространство возможных промптов как область для систематического исследования, используя алгоритмы для автоматического определения наиболее эффективных формулировок, что позволяет выйти за рамки интуиции и человеческих ограничений при создании запросов.
MIPROv2 представляет собой практическую реализацию автоматической оптимизации запросов, основанную на одновременном выборе наиболее эффективных инструкций и демонстраций few-shot. Данный подход предполагает поиск оптимальной комбинации этих элементов для максимизации производительности модели. Выбор инструкций позволяет адаптировать запрос к конкретной задаче, а выбор релевантных демонстраций few-shot предоставляет модели примеры желаемого поведения. В процессе оптимизации MIPROv2 оценивает различные комбинации инструкций и демонстраций, определяя те, которые приводят к наилучшим результатам на целевом наборе данных, тем самым улучшая общую производительность без необходимости ручной настройки.
Байесовская оптимизация, использующая такие методы как Tree-structured Parzen Estimator (TPE), представляет собой эффективный способ исследования обширного пространства возможных запросов. TPE — это алгоритм, который моделирует распределение вероятностей производительности запросов, используя непараметрические методы оценки плотности. Он строит две модели: одну для запросов с высокой производительностью и другую для запросов с низкой производительностью. Далее, алгоритм выбирает новые запросы для оценки, основываясь на вероятности того, что они окажутся в области высокой производительности, эффективно балансируя между исследованием новых областей пространства запросов и использованием уже известных эффективных конфигураций. Такой подход позволяет существенно сократить количество необходимых итераций для нахождения оптимального запроса по сравнению с методом случайного поиска или грубым перебором.
Автоматизированный подход к оптимизации промптов позволяет добиться повышения производительности и снизить зависимость от экспертных оценок. В результате оптимизации промптов, наблюдается снижение разброса оценок производительности на различных бенчмарках на 2%. Это достигается за счет систематического поиска оптимальной конфигурации входных данных, что позволяет минимизировать вариативность результатов и повысить стабильность работы моделей машинного обучения.

Композиция Модульных Промптов с DSPy: Гибкость и Переиспользование
Декларативное программирование подсказок, реализуемое в DSPy, предоставляет основу для создания сложных подсказок из модульных, параметризованных компонентов. Этот подход предполагает разбиение общей задачи на отдельные, переиспользуемые блоки, каждый из которых отвечает за конкретный аспект генерации ответа. Параметризация позволяет динамически настраивать поведение этих компонентов, изменяя входные данные и получая различные результаты. Вместо построения единой, монолитной подсказки, DSPy позволяет создавать составные подсказки путем комбинирования этих модулей, что значительно упрощает процесс разработки и отладки, а также повышает гибкость и масштабируемость.
Использование модульных элементов в построении промптов обеспечивает повышенную гибкость, возможность повторного использования и компонуемость. Вместо создания монолитных промптов, разработчики могут собирать их из отдельных, параметризованных блоков. Это упрощает процесс разработки, поскольку позволяет переиспользовать проверенные компоненты в различных задачах, а также легко изменять и комбинировать их для адаптации к новым требованиям без необходимости полной переработки всего промпта. Такая модульная структура также облегчает отладку и тестирование, поскольку можно изолированно проверять функциональность каждого компонента.
Модель MIPROv2 выигрывает от возможностей DSPy, позволяя создавать сложные цепочки промптов, адаптированные под конкретные задачи. DSPy предоставляет инструменты для модульного построения этих цепочек, что дает возможность комбинировать и настраивать отдельные компоненты промптов для достижения оптимальной производительности. Это особенно полезно для задач, требующих многоэтапной обработки и сложной логики, поскольку позволяет создавать специализированные пайплайны, оптимизированные для конкретного сценария использования и обеспечивающие более точные и релевантные результаты.
DSPy позволяет рассматривать промпты как программный код, что открывает возможности для систематического проведения экспериментов и оптимизации. Вместо ручной настройки и интуитивной корректировки, пользователи могут применять стандартные программные техники, такие как параметризация, модульное тестирование и автоматизированные циклы обратной связи. Это позволяет проводить контролируемые A/B-тесты различных вариантов промптов, измерять их производительность по заданным метрикам и автоматически находить оптимальные конфигурации для конкретных задач. Такой подход значительно упрощает процесс улучшения качества и надежности промптов, а также способствует более эффективному использованию больших языковых моделей.
Подтверждение Эффективности на Разнообразных Бенчмарках
Тщательная оценка на стандартных бенчмарках, таких как MMLU-Pro, GSM8K и GPQA, подтверждает эффективность автоматизированных и модульных стратегий промптинга. Бенчмарк MMLU-Pro оценивает многопредметные знания и навыки решения задач, в то время как GSM8K специализируется на математических задачах, требующих многошаговых рассуждений. GPQA (Graduate-level Physics Questions) предназначен для оценки понимания физики на уровне магистратуры. Результаты, полученные на этих бенчмарках, демонстрируют, что использование автоматизированных методов создания промптов и модульная структура, позволяющая комбинировать различные компоненты промпта, приводят к значительному улучшению показателей производительности моделей в различных областях знаний и типах задач.
Для оценки производительности в критически важных областях, таких как медицинское рассуждение, используются специализированные бенчмарки, включающие HeadQA, MedCalc-Bench, Medec и MedBullets. HeadQA фокусируется на вопросах, требующих понимания сложных медицинских текстов и извлечения релевантной информации. MedCalc-Bench предназначен для проверки способности модели решать задачи, связанные с медицинскими расчетами и интерпретацией числовых данных. Бенчмарки Medec и MedBullets оценивают навыки модели в области клинического рассуждения и анализа медицинских заключений, соответственно. Использование этих специализированных наборов данных позволяет более точно оценить применимость модели в реальных медицинских сценариях и выявить потенциальные области для улучшения.
Метод Chain-of-Thought (CoT) значительно повышает эффективность выполнения сложных задач, требующих рассуждений. Суть CoT заключается в том, что модель не просто выдает конечный ответ, а генерирует последовательность промежуточных логических шагов, объясняющих процесс решения. Это позволяет модели более эффективно использовать свои знания и справляться с задачами, требующими многоступенчатых умозаключений, таких как математические задачи, логические головоломки и задачи, требующие анализа текста и вывода заключений. В результате применения CoT наблюдается существенное улучшение показателей точности и надежности ответов по сравнению с традиционными подходами, не использующими явное представление логической цепочки рассуждений.
В качестве базового уровня для сравнения использовалась модель Zero-Shot Predict, что позволило оценить улучшения, достигнутые благодаря применению методов APO (Automated Prompt Optimization) и DSPy. Анализ показал, что изменение дизайна промптов привело к изменению позиций моделей в рейтинге бенчмарков в 3 из 73 случаев сравнения. Это указывает на значительное влияние формулировки промпта на результаты, даже при использовании передовых методов оптимизации, и подчеркивает важность тщательной разработки и тестирования промптов для обеспечения надежной и воспроизводимой производительности.
К Более Надёжным и Интеллектуальным Системам: Перспективы Развития
Автоматизированные и модульные методы разработки запросов обладают значительным потенциалом для повышения надёжности и способности к обобщению языковых моделей. Традиционно, эффективность этих моделей сильно зависела от тщательно разработанных, вручную созданных запросов, что ограничивало их адаптивность и требовало значительных усилий для переноса на новые задачи. Новые подходы позволяют создавать запросы автоматически, используя алгоритмы поиска и оптимизации, а также разбивать сложные запросы на более простые, модульные компоненты. Это не только снижает зависимость от ручной настройки, но и позволяет моделям более эффективно использовать имеющиеся данные и обобщать полученные знания на незнакомые ситуации, открывая путь к созданию более устойчивых и интеллектуальных систем, способных решать сложные задачи в различных областях, включая здравоохранение, образование и научные исследования.
Снижение зависимости от тщательно разработанных запросов открывает путь к созданию систем, способных к более гибкой адаптации к новым задачам и областям применения. Традиционно, эффективность языковых моделей сильно зависела от качества и специфичности промптов, создаваемых экспертами. Однако, разработка автоматизированных методов генерации и оптимизации запросов позволяет преодолеть эту зависимость, обеспечивая более широкую применимость и устойчивость систем. Это особенно важно в условиях быстро меняющихся требований и необходимости обработки разнообразных данных, поскольку позволяет моделям самостоятельно адаптироваться к новым условиям без необходимости ручной перенастройки. В результате, системы становятся более универсальными и способными решать широкий спектр задач в различных сферах, от медицины и образования до научных исследований и разработки.
Развитие автоматизированных методов создания запросов и модульных систем открывает перспективы для создания более устойчивых и интеллектуальных систем, способных решать сложные задачи в различных областях. В здравоохранении это может привести к улучшению диагностики и персонализированного лечения, основанных на анализе больших объемов данных. В сфере образования — к созданию адаптивных обучающих платформ, подстраивающихся под индивидуальные потребности каждого ученика. А в науке — к ускорению процесса открытий благодаря автоматизации анализа данных и генерации гипотез. Такой подход позволяет преодолеть ограничения, связанные с ручным созданием запросов, и повысить эффективность и надежность систем искусственного интеллекта, приближая их к решению реальных, сложных проблем.
Метод Bootstrap Few-Shot с использованием случайного поиска (BFRS) представляет собой перспективный подход к усилению возможностей обучения с небольшим количеством примеров. В отличие от традиционных методов, требующих обширных наборов данных, BFRS позволяет модели эффективно учиться на ограниченном количестве доступных примеров, используя стратегию случайного поиска для генерации и оценки различных вариантов подсказок. Этот процесс позволяет модели адаптироваться к новым задачам и доменам без необходимости ручной настройки и оптимизации, значительно повышая ее обобщающую способность и надежность. Эффективность BFRS заключается в автоматизированном исследовании пространства возможных подсказок, что позволяет выявить наиболее подходящие стратегии обучения даже при ограниченном количестве данных, открывая новые возможности для применения языковых моделей в различных областях, где сбор больших наборов данных затруднен или невозможен.
Исследование подчеркивает важность целостного подхода к оценке языковых моделей, что находит отклик в философии Дональда Дэвиса. Он говорил: «Простота — ключ к надежности». Как и в архитектуре сложных систем, где понимание взаимосвязей критически важно, так и в оценке языковых моделей необходимо учитывать всю картину, а не отдельные аспекты. Стандартные методы оценки, использующие фиксированные запросы, подобны попытке починить сердце, не понимая кровотока, что приводит к недооценке истинного потенциала и вносит нежелательную изменчивость. Предложенный метод структурированного промптинга стремится к созданию более надежных и репрезентативных эталонов, напоминая о важности ясной структуры для обеспечения эффективной работы системы.
Куда Ведет Эта Дорога?
Представленная работа демонстрирует, что стандартные методы оценки языковых моделей, подобно постройке квартала на зыбком фундаменте, склонны к изменчивости и недооценке истинного потенциала. Идея структурированного промптинга, автоматической оптимизации — это не просто улучшение отдельных инструментов, а переосмысление всей инфраструктуры бенчмаркинга. Однако, эта эволюция поднимает новые вопросы. Как обеспечить универсальность этих «структур», чтобы они не стали новыми, еще более узкими «бутылочными горлышками»?
Очевидно, что переход к более сложным методам оценки требует и более глубокого понимания самих моделей. Необходимо исследовать, как «структура» промпта влияет на внутренние представления и процессы принятия решений в языковой модели. Без этого, мы рискуем лишь усовершенствовать способы «заставить» модель выдать желаемый ответ, не понимая, действительно ли она «понимает» задачу.
В конечном итоге, задача состоит не в создании все более сложных бенчмарков, а в разработке принципиально новых подходов к оценке, которые отражают не только способность модели к имитации, но и ее истинный «интеллект». Это требует смелого взгляда на проблему, отказа от привычных шаблонов и признания того, что настоящая оценка — это не просто измерение, а диалог.
Оригинал статьи: https://arxiv.org/pdf/2511.20836.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.