Статьи QuantRise
Считаем без запуска: оценка способности моделей понимать сложность кода
Автор: Денис Аветисян
Новое исследование выявляет ограничения современных языковых моделей в понимании вычислительных затрат CUDA-ядер без их фактического выполнения.

В статье представлена gpuFLOPBench — эталонная база для оценки способности моделей статически анализировать сложность кода и предсказывать количество операций с плавающей точкой (FLOPs).
Современные графические процессоры требуют от разработчиков умения предвидеть узкие места в производительности еще до запуска ядра, однако существующие большие языковые модели (LLM) редко тестируются в этом контексте прогностического анализа. В работе ‘Counting Without Running: Evaluating LLMs’ Reasoning About Code Complexity’ представлен новый бенчмарк gpuFLOPBench, позволяющий оценить способность LLM статически анализировать вычислительную сложность CUDA-ядер. Полученные результаты демонстрируют, что, несмотря на успехи в простых случаях, модели все еще допускают значительные ошибки при оценке неявных операций и аппаратной оптимизации. Сможем ли мы разработать инструменты на основе LLM, способные предсказывать производительность графических процессоров с той же точностью, что и опытные разработчики?
Скрытые Издержки GPU-Вычислений
Точное прогнозирование производительности GPU-ядер имеет решающее значение для эффективного распределения ресурсов и оптимизации приложений. В современных вычислительных системах, где GPU играют ключевую роль в обработке данных, способность предсказывать, как быстро и эффективно ядро выполнит свою задачу, позволяет избежать перегрузки оборудования и максимизировать пропускную способность. Неточные прогнозы могут приводить к неэффективному использованию вычислительных мощностей, задержкам в обработке и увеличению энергопотребления. Оптимизация на основе точных прогнозов позволяет разработчикам и системным администраторам принимать обоснованные решения о распределении задач, масштабировании ресурсов и выборе оптимальных конфигураций оборудования, что в конечном итоге повышает общую производительность и снижает затраты.
Традиционные методы оценки производительности графических процессоров (GPU) зачастую не учитывают так называемые “скрытые FLOPS” — вычислительные затраты, возникающие в результате оптимизаций компилятора и поведения программы во время выполнения. Эти “неявные FLOPS” проявляются в таких процессах, как переупорядочивание инструкций, раскрытие циклов и векторизация, которые компилятор выполняет для повышения эффективности кода. В результате, предсказанная производительность, основанная только на явных операциях с плавающей точкой, может значительно отличаться от фактической. Игнорирование этих скрытых затрат приводит к неточному планированию ресурсов и может существенно снизить общую эффективность вычислений, особенно в сложных приложениях, где оптимизации компилятора оказывают значительное влияние на производительность. Понимание и учет “неявных FLOPS” критически важно для точной оценки и оптимизации GPU-вычислений, позволяя разработчикам добиваться максимальной производительности и эффективно использовать доступные ресурсы.

Представляем gpuFLOPBench: Новый Эталонный Набор Данных
Представляем gpuFLOPBench — эталонный набор данных, предназначенный для строгой оценки способности больших языковых моделей (LLM) предсказывать количество операций с плавающей точкой (FLOP) для различных CUDA-ядер. gpuFLOPBench позволяет количественно оценить точность LLM в предсказании вычислительной сложности графических ядер, что критически важно для оптимизации производительности и эффективного планирования ресурсов. Тесты проводятся на разнообразном наборе CUDA-ядер, представляющих широкий спектр вычислительных задач, что обеспечивает всестороннюю оценку возможностей LLM в области предсказания FLOP. Результаты, полученные с использованием gpuFLOPBench, могут быть использованы для сравнения различных архитектур LLM и стратегий обучения в контексте прогнозирования производительности графических процессоров.
Набор данных gpuFLOPBench использует ядра из HeCBench, что обеспечивает стандартизированную и репрезентативную рабочую нагрузку для оценки. HeCBench представляет собой широко используемый набор тестов для высокопроизводительных вычислений, включающий в себя разнообразные CUDA-ядра, охватывающие широкий спектр вычислительных задач. Использование HeCBench в качестве основы для gpuFLOPBench гарантирует, что оценка предсказаний количества операций с плавающей точкой (FLOP) будет проводиться на согласованном и общепринятом наборе задач, что облегчает сравнение различных моделей и стратегий обучения. Данный подход позволяет обеспечить надежность и воспроизводимость результатов, полученных с использованием gpuFLOPBench.
gpuFLOPBench предоставляет возможность прямого сопоставления различных архитектур больших языковых моделей (LLM) и стратегий обучения в контексте предсказания производительности. Недавние оценки показали, что использование этого набора данных позволяет количественно оценить эффективность различных моделей в прогнозировании количества операций с плавающей точкой (FLOP) для CUDA-ядер. Это достигается путем предоставления стандартизированного набора задач и метрик, позволяющих сравнивать модели по их способности к точному предсказанию вычислительной сложности, что является важным фактором для оптимизации производительности и планирования ресурсов.
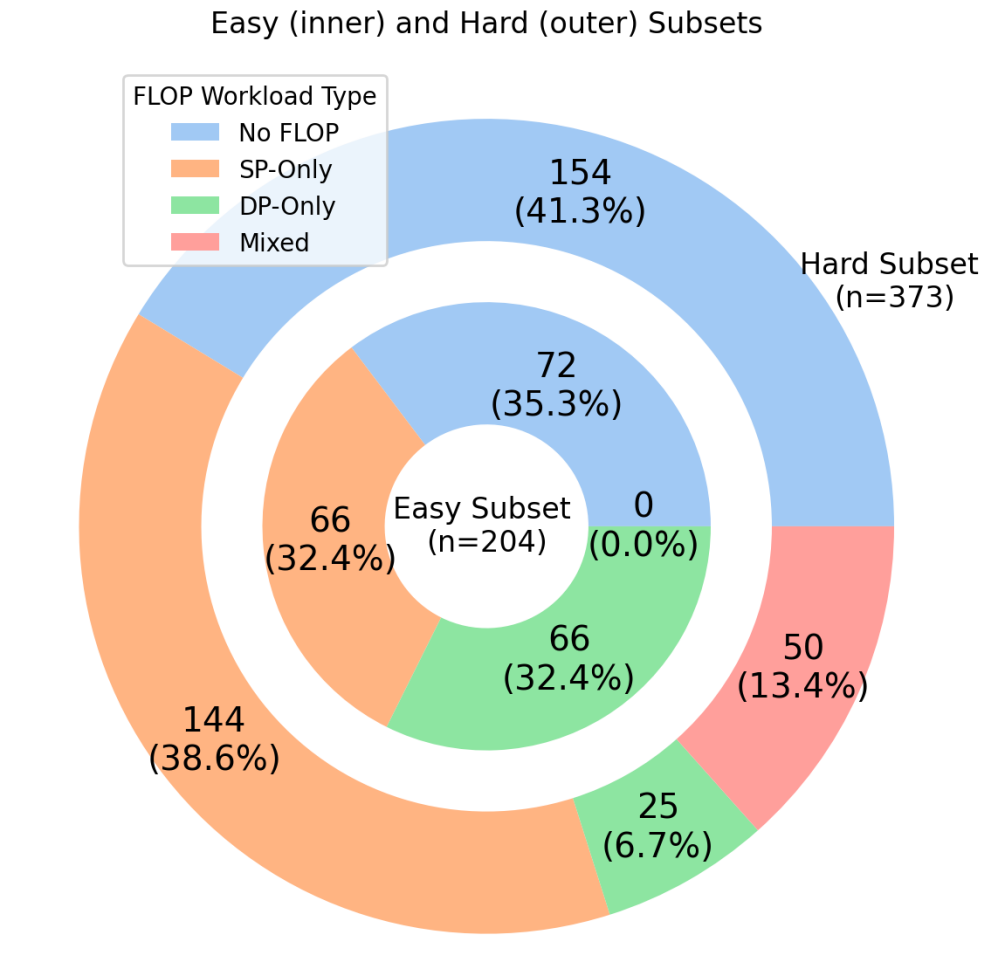
Раскрывая Источники Скрытых FLOPS
При попытках предсказания количества операций с плавающей точкой (FLOPs) большие языковые модели (LLM) испытывают трудности с ядрами, содержащими специальные математические функции, операции деления и общие подвыражения. Эти элементы приводят к появлению неявных вычислений, которые не отражаются в статическом анализе кода. Специальные математические функции, такие как или , часто реализуются через сложные алгоритмы, требующие множества внутренних операций. Операции деления, особенно в архитектурах, где они выполняются медленнее, чем умножение, увеличивают общее число FLOPs. Общие подвыражения, хотя и оптимизируют код за счет повторного использования результатов, также вносят вклад в общее количество вычислений, которое LLM часто недооценивает при предсказании FLOPs.
Отклонение потоков данных (Data-Dependent Warp Divergence) существенно усложняет точное предсказание количества операций с плавающей точкой (FLOPs). Данное явление возникает из-за того, что фактическое число выполняемых FLOPs изменяется в зависимости от входных данных. В частности, если различные потоки в warp (группа потоков, выполняющихся параллельно) выполняют разные ветви кода, обусловленные значениями входных данных, то возникают простои и необходимость последовательного выполнения операций, что увеличивает общее число FLOPs. Степень отклонения потоков данных напрямую зависит от структуры данных и логики алгоритма, что делает статическое предсказание FLOPs неточным и требует учета динамических характеристик выполнения.
Статический анализ, несмотря на свою полезность в оценке вычислительной сложности, не способен полностью учесть динамические эффекты, возникающие в современных графических процессорах. Это приводит к систематической недооценке фактических вычислительных затрат, особенно в случае смешанных ядер (Mixed kernels). Ошибки в предсказании количества операций с плавающей точкой (FLOPs) измеряются с помощью средней абсолютной логарифмической ошибки (MALE), которая значительно выше для смешанных ядер, чем для одно- или двухточных, что подтверждает ограничения статического анализа в сложных вычислительных сценариях. Данный показатель отражает несоответствие между предсказанными и фактическими FLOPs, указывая на необходимость более точных методов анализа, учитывающих динамическое поведение кода.
Недавние оценки LLM с использованием gpuFLOPBench показали, что модели демонстрируют более высокую производительность на ядрах, использующих одинарную и двойную точность (Single/Double-precision), однако испытывают затруднения с ядрами смешанной точности (Mixed kernels). Этот результат подтверждает сложность предсказания неявных FLOPs, возникающих в смешанных ядрах, поскольку LLM испытывают трудности с точной оценкой вычислительных затрат, связанных с операциями, использующими различные форматы данных. Разница в производительности указывает на то, что LLM лучше справляются с предсказанием FLOPs для стандартных операций с плавающей точкой, в то время как неявные вычисления, возникающие в смешанных ядрах, приводят к ошибкам в прогнозировании.
Последствия для Оптимизации Производительности на Основе LLM
Повышение точности предсказания количества операций с плавающей запятой (FLOP) благодаря таким наборам данных, как gpuFLOPBench, открывает новые возможности для оптимизации затрат и эффективного распределения ресурсов в приложениях, ускоренных графическими процессорами. Более точная оценка вычислительной сложности позволяет разработчикам и системам управления ресурсами принимать обоснованные решения о масштабировании, планировании и выделении ресурсов GPU. Это особенно важно в облачных средах и высокопроизводительных вычислениях, где минимизация затрат и максимизация пропускной способности являются ключевыми приоритетами. Улучшенное предсказание позволяет создавать более реалистичные модели стоимости, что, в свою очередь, способствует более эффективному использованию ресурсов и снижению энергопотребления.
Исследования показали, что большие языковые модели (LLM) способны выявлять неявные операции с плавающей точкой (FLOPs) в коде, что открывает новые возможности для оптимизации производительности и энергоэффективности. В отличие от традиционных методов анализа, которые фокусируются на явных вычислениях, LLM могут обнаруживать скрытые вычислительные затраты, возникающие из-за особенностей архитектуры и реализации алгоритмов. Это позволяет разработчикам не только улучшать скорость выполнения программ, но и снижать потребление энергии за счет более эффективного использования ресурсов графического процессора. Идентификация неявных особенно полезна при оптимизации смешанных ядер, где традиционные методы могут оказаться неэффективными, что подтверждается снижением метрики MALE в ходе экспериментов.
Исследование демонстрирует возможность создания инструментов, основанных на больших языковых моделях (LLM), для автоматического анализа и оптимизации GPU-ядер. Полученные результаты, подтвержденные различными значениями F1-меры для разных архитектур LLM, указывают на значительный потенциал в повышении производительности. Автоматизированный анализ кода позволяет выявлять узкие места и предлагать эффективные решения для оптимизации, что может привести к существенному увеличению скорости вычислений и снижению энергопотребления графических процессоров. Различия в показателях F1-меры между моделями подчеркивают важность выбора подходящей архитектуры LLM для конкретной задачи оптимизации и стимулируют дальнейшие исследования в этой области.
Разработка моделей, демонстрирующих повышенную точность при анализе смешанных ядер (mixed kernels), является ключевым фактором для реализации полного потенциала оптимизации GPU с помощью больших языковых моделей. Показатель MALE (Mean Absolute Logarithmic Error) служит важным индикатором эффективности таких моделей — его снижение свидетельствует о более точной оценке вычислительной сложности и, следовательно, о возможности более эффективной оптимизации кода. Улучшение производительности на смешанных ядрах, содержащих комбинацию различных вычислительных операций, особенно важно, поскольку именно такие ядра часто встречаются в реальных приложениях. Повышенная точность оценки операций в смешанных ядрах позволяет LLM предлагать более эффективные стратегии оптимизации, что приводит к значительному увеличению производительности и снижению энергопотребления GPU-ускоренных приложений.
Исследование демонстрирует, что современные языковые модели часто не способны точно оценить вычислительную сложность CUDA-ядер, полагаясь скорее на поверхностные закономерности, чем на глубокое понимание аппаратных оптимизаций. Это особенно заметно при анализе неявных FLOPs, которые не отражены в явном коде. Как заметил Брайан Керниган: «Простота — высшая степень совершенства». В контексте данной работы, сложность оценки FLOPs указывает на необходимость упрощения моделей и повышения их способности к абстрактному мышлению, что позволит им более эффективно анализировать и оптимизировать код. gpuFLOPBench выступает инструментом, выявляющим эти недостатки и стимулирующим разработку более ясных и эффективных алгоритмов.
Куда Ведет Этот Счет?
Представленная работа, обнажая ограниченность современных языковых моделей в оценке вычислительной сложности CUDA-ядер, не столько решает проблему, сколько обнажает её истинные масштабы. Счетчик операций с плавающей точкой — всего лишь инструмент, а глубина понимания архитектурных оптимизаций и скрытых вычислительных издержек остается за пределами возможностей текущих алгоритмов. Упрощение — это искушение, и каждая убранная деталь может скрыть более тонкое понимание.
Будущие исследования, вероятно, потребуют смещения фокуса с прямого предсказания FLOPs на оценку относительной вычислительной стоимости различных реализаций ядра. Не столько абсолютное число, сколько способность различать эффективное и неэффективное использование аппаратных ресурсов представляется более важной задачей. Иллюзия точности должна уступить место честному признанию границ понимания.
В конечном итоге, истинный прогресс будет достигнут не через добавление новых слоев абстракции, а через очищение существующих. Избавление от избыточности, от поверхностного знания — вот путь к более глубокому пониманию вычислительной сложности. И, возможно, тогда, счёт станет не просто цифрой, а отражением сути происходящего.
Оригинал статьи: https://arxiv.org/pdf/2512.04355.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.