Квантовые технологии
Сжатие интеллекта: Оценка точности квантования больших языковых моделей
Автор: Денис Аветисян
Новое исследование подробно анализирует методы пост-тренировочного квантования, позволяющие уменьшить размер и повысить эффективность больших языковых моделей без существенной потери качества.
В статье проведена всесторонняя оценка методов пост-тренировочного квантования с использованием микромасштабируемых форматов с плавающей точкой (MXFP), показывающая, что MXFP8 обеспечивает стабильность, квантование до 4 бит является сложной задачей, а компенсация ошибок и аффинные преобразования дают наилучшие результаты.
Несмотря на растущий интерес к снижению вычислительной сложности больших языковых моделей (LLM), влияние микромасштабируемых форматов с плавающей точкой (MXFP) на эффективность постобработанной квантизации (PTQ) оставалось недостаточно изученным. В настоящей работе, ‘Benchmarking Post-Training Quantization of Large Language Models under Microscaling Floating Point Formats’, проведено систематическое исследование PTQ с использованием форматов MXFP, охватывающее различные алгоритмы, эталонные тесты и семейства LLM. Ключевым результатом является подтверждение стабильности 8-битной квантизации MXFP, существенных сложностей при 4-битной квантизации и важности компенсации ошибок масштабирования. Какие новые подходы к разработке PTQ позволят в полной мере раскрыть потенциал низкоточных форматов, таких как MXFP, для еще большей оптимизации LLM?
Квантование: Путь к Доступному Искусственному Интеллекту
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, однако их функционирование требует значительных вычислительных ресурсов. Размер этих моделей, состоящих из миллиардов параметров, приводит к высокой потребности в памяти и вычислительной мощности, что затрудняет их развертывание на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы. Для эффективной работы даже при решении относительно простых задач требуется дорогостоящее оборудование и значительное энергопотребление. Это создает серьезные препятствия для широкого распространения и доступности передовых технологий обработки естественного языка, ограничивая их применение в различных областях, где важны мобильность и экономичность.
Огромные размеры современных языковых моделей представляют собой значительное препятствие для их широкого внедрения. Необходимость в большом объеме памяти и вычислительной мощности не только усложняет развертывание этих моделей на периферийных устройствах, таких как смартфоны или встроенные системы, но и существенно увеличивает эксплуатационные расходы, связанные с поддержанием инфраструктуры для их работы. Вычислительные затраты, потребляемые при обработке запросов, напрямую влияют на стоимость обслуживания, что делает использование таких моделей непрактичным для многих потенциальных приложений и пользователей. В результате, оптимизация размеров моделей становится критически важной задачей для обеспечения их доступности и экономичности.
Квантизация представляет собой эффективный подход к уменьшению габаритов больших языковых моделей и ускорению процесса вывода данных, что открывает возможности для их более широкого применения. Уменьшение точности представления параметров модели — например, переход от 32-битных чисел с плавающей точкой к 8-битным целым числам — значительно снижает объём необходимой памяти и вычислительные затраты. Это, в свою очередь, позволяет развертывать модели на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы, а также снижает стоимость их эксплуатации. Таким образом, квантизация не только оптимизирует производительность, но и делает передовые технологии обработки естественного языка доступными для более широкого круга пользователей и приложений.
Простая квантизация, направленная на уменьшение размера и ускорение работы больших языковых моделей, часто приводит к неприемлемому снижению точности. Однако, современные методы, такие как 8-битная квантизация весов и активаций (W8A8), демонстрируют значительное улучшение ситуации. Исследования показывают, что применение W8A8 обеспечивает восстановление точности на уровне ≥97% для различных моделей и тестовых наборов данных. Это означает, что, используя W8A8, можно существенно уменьшить вычислительные затраты и требования к памяти, сохраняя при этом высокую производительность языковой модели, что открывает возможности для её развертывания на более широком спектре устройств и в более экономичных условиях.
Пост-Тренировочная Квантизация: Искусство Сжатия без Жертв
Пост-тренировочная квантизация (PTQ) представляет собой эффективный метод сжатия больших языковых моделей (LLM) без необходимости их повторного обучения. Этот подход позволяет снизить вычислительные затраты и объем памяти, необходимые для развертывания моделей, путем уменьшения разрядности представления весов и активаций. В отличие от квантизации, требующей обучения (Quantization-Aware Training), PTQ позволяет применить сжатие к уже обученной модели, что существенно упрощает процесс и снижает временные и ресурсные затраты. PTQ особенно актуальна для развертывания LLM на устройствах с ограниченными ресурсами, таких как мобильные телефоны или периферийные устройства, где сохранение точности при снижении вычислительной нагрузки является критически важным.
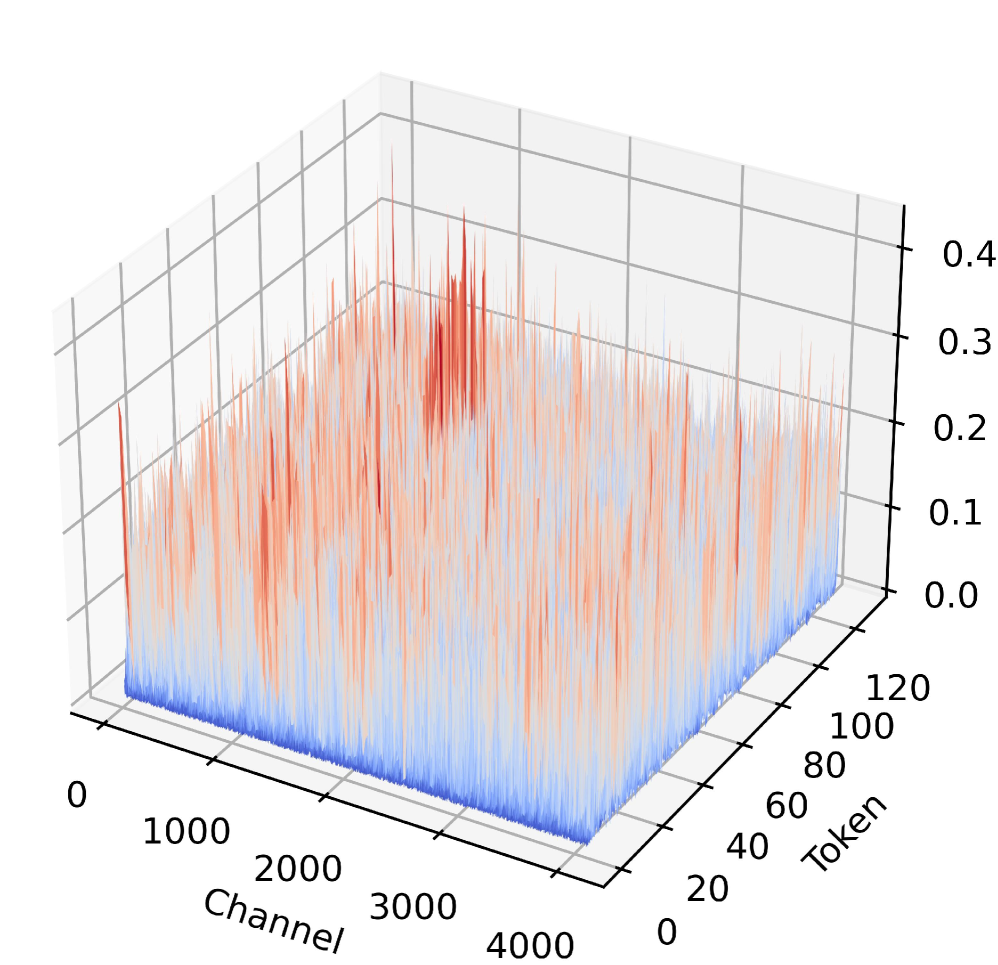
Форматы микромасштабирования чисел с плавающей точкой (MXFP) повышают эффективность квантозации за счет сохранения динамического диапазона, однако они подвержены ошибке, связанной с коэффициентом масштабирования. Данная ошибка возникает из-за ограниченной точности представления коэффициента масштабирования, используемого для преобразования чисел с плавающей точкой в целочисленные представления. При квантизации весов и активаций модели, небольшие ошибки в коэффициенте масштабирования могут накапливаться и приводить к значительным отклонениям в выходных данных, что негативно сказывается на точности модели. Эффект особенно заметен при использовании низкоточных форматов, таких как MXFP4, где разрядность коэффициента масштабирования ограничена.
Операция предварительного масштабирования (Pre-Scale Operation) направлена на устранение ошибки фактора масштабирования (Scaling Factor Error), возникающей при использовании форматов с микромасштабированием чисел с плавающей точкой (MXFP). Данная ошибка может снижать стабильность процесса квантизации. Применение предварительного масштабирования входных данных перед квантизацией позволяет повысить точность и стабильность модели. Экспериментальные данные показывают, что использование данной стратегии приводит к улучшению производительности с 52.39% до 56.76% при квантизации MXFP4.
Методы аффинного и канального преобразования дополнительно уточняют постобработочную квантизацию (PTQ) за счет адаптивной регулировки числовых диапазонов весов и активаций. Аффинное преобразование применяет линейную функцию к данным, оптимизируя масштаб и смещение для минимизации потерь точности. Канальное преобразование идет дальше, применяя отдельные параметры масштабирования и смещения к каждому каналу тензора, что позволяет учитывать различия в распределении данных между каналами. Такой подход позволяет более точно отобразить исходные данные в квантованное пространство, что приводит к повышению производительности и снижению потерь точности по сравнению со стандартными методами PTQ.
Трансформационные Методы: Перестройка Модели для Эффективного Квантования
Методы SmoothQuant и AWQ демонстрируют эффективность преобразования, осуществляемого на уровне каналов, путем переноса сложности квантования с активаций на веса. Традиционно, квантование активаций представляет собой более сложную задачу из-за их широкого динамического диапазона и чувствительности к изменениям. Перенос сложности на веса позволяет использовать более эффективные стратегии квантования для весов, поскольку они обычно имеют более стабильное распределение. Это достигается путем применения аффинных преобразований к весам каждого канала, что позволяет уменьшить разброс значений активаций после квантования и, следовательно, повысить точность модели. Фактически, сложность квантования смещается от операций, требующих больших вычислительных ресурсов (активации), к параметрам, которые могут быть оптимизированы в процессе обучения.
Методы ротационной трансформации, такие как QuaRot и SpinQuant, повышают устойчивость квантования за счет применения ортогональных преобразований к весам модели. В основе этих методов лежит идея переориентации весов в пространстве признаков таким образом, чтобы минимизировать потери точности, возникающие при квантовании. Ортогональные преобразования сохраняют норму векторов, что позволяет снизить величину ошибок квантования и улучшить обобщающую способность модели после квантования. Применение этих преобразований позволяет более эффективно представлять веса с использованием меньшего количества бит, сохраняя при этом высокую точность.
Метод FlatQuant представляет собой эффективную альтернативу в рамках аффинного преобразования для оптимизации квантования. Он использует легковесную блочную стратегию обучения, что позволяет добиться высокой точности восстановления — 97.12% при использовании квантования W4A8 на модели openPangu-Embedded-7B-V1.1. Данный подход позволяет минимизировать вычислительные затраты при обучении, сохраняя при этом высокую производительность квантованной модели.
Методы компенсации ошибок, такие как GPTQ и MR-GPTQ, направлены на снижение погрешностей, возникающих при квантовании, посредством явного моделирования и коррекции этих ошибок. GPTQ использует алгоритм, основанный на втором порядке, для минимизации ошибки квантования, в то время как MR-GPTQ расширяет эту концепцию за счет использования мульти-ранговой декомпозиции для повышения эффективности и точности. Эти методы позволяют более эффективно представлять веса модели в низкоточных форматах, минимизируя потери производительности, связанные с квантованием, и обеспечивая более высокую точность по сравнению со стандартными подходами к квантованию.
Будущее Эффективных Больших Языковых Моделей: Доступность и Демократизация ИИ
Современные языковые модели огромного масштаба, несмотря на свою впечатляющую производительность, требуют значительных вычислительных ресурсов и памяти. Однако, комбинация передовых методов квантования, включающая в себя трансформационные подходы и компенсацию ошибок, позволяет существенно снизить размер этих моделей и связанные с ними вычислительные затраты. Квантование, по сути, представляет собой уменьшение точности представления чисел, используемых в модели, что приводит к уменьшению её размера без значительной потери производительности. В частности, применение сложных трансформаций и алгоритмов компенсации ошибок позволяет минимизировать потери точности, возникающие при снижении разрядности. Это открывает возможности для развертывания мощных языковых моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы, значительно расширяя доступ к передовым технологиям обработки естественного языка.
Современные достижения в области квантования больших языковых моделей открывают возможности для их развертывания на устройствах с ограниченными ресурсами, таких как смартфоны и встроенные системы. Ранее сложные вычисления, требующие мощных серверов, становятся доступными локально, что значительно расширяет спектр применения технологий обработки естественного языка. Это позволяет интегрировать передовые NLP-возможности в приложения, работающие непосредственно на пользовательских устройствах, обеспечивая более высокую скорость обработки данных, повышенную конфиденциальность и независимость от сетевого подключения. Таким образом, снижение вычислительных затрат и требований к памяти не только оптимизирует производительность, но и способствует демократизации доступа к интеллектуальным технологиям, делая их более доступными для широкой аудитории.
Дальнейшее исследование новых стратегий квантования представляется критически важным для раскрытия всего потенциала больших языковых моделей в различных областях применения. В то время как 8-битное квантование обеспечивает сохранение исходной производительности, переход к 4-битному квантованию сопряжен с определенными трудностями. Показатели восстановления точности при 4-битном квантовании варьируются в пределах от 86.37% до 96.79%, что указывает на необходимость разработки более совершенных методов компенсации потерь. Успешное решение этих задач позволит значительно снизить вычислительные затраты и размер моделей, открывая возможности для их развертывания на устройствах с ограниченными ресурсами и расширяя доступ к мощным возможностям обработки естественного языка.
Эффективная квантизация больших языковых моделей (LLM) представляет собой не просто технический прорыв, но и ключевой фактор демократизации доступа к искусственному интеллекту. Уменьшение размера и вычислительных затрат, достигаемое благодаря квантизации, позволяет развертывать мощные модели на устройствах с ограниченными ресурсами, открывая возможности для широкого круга пользователей и приложений. Примечательно, что исследования демонстрируют высокую согласованность в производительности различных моделей — средняя корреляция между ними составляет 0.917, что указывает на стабильные тенденции в эффективности, независимо от архитектуры или модальности. Это подтверждает, что оптимизация квантизации может принести значительные выгоды для всего спектра LLM, делая передовые технологии обработки естественного языка доступными для более широкой аудитории и стимулируя инновации в различных областях.
Исследование демонстрирует, что упрощение моделей, в частности, применение методов пост-тренировочной квантизации, сопряжено с неизбежными потерями точности. Однако, как показывает работа, грамотное применение микромасштабируемых форматов (MXFP) позволяет минимизировать эти потери и достичь стабильности даже при экстремальном сжатии. Тим Бернерс-Ли однажды сказал: «Веб — это не просто коллекция веб-страниц, это способ думать». Подобно тому, как веб требует структурированного подхода к информации, так и квантизация больших языковых моделей требует продуманного подхода к представлению данных, чтобы сохранить их функциональность и избежать искажений. Применение аффинных преобразований и компенсации ошибок, как показано в статье, подтверждает эту идею — взлом системы представления данных требует понимания её структуры и умелого манипулирования ею.
Что дальше?
Представленная работа, тщательно препарируя методы пост-тренировочной квантизации, неизбежно наводит на мысль о том, что вся эта гонка за снижением точности — лишь элегантное признание несовершенства исходных моделей. Каждый патч, каждая аффинная трансформация — это философское заявление о том, что истинное знание требует компромисса. Особо стоит отметить стабильность MXFP8 — как будто система сама подсказывает, где находится предел сжатия, не разрушающего функциональность.
Однако, проблема 4-битной квантизации остаётся открытой раной. Попытки выжать максимум из минимума неизбежно сталкиваются с ограничениями, заставляя задуматься: а не является ли погоня за экстремальным сжатием самоцелью, оторванной от реальных потребностей? Истинный прогресс, вероятно, лежит в более глубоком понимании природы ошибок квантизации и разработке форматов, изначально ориентированных на компромисс между точностью и размером.
В перспективе, стоит ожидать смещения акцентов в сторону квантизации, адаптированной к конкретным задачам и архитектурам моделей. Универсальных решений не существует, и каждый новый формат — это лишь ещё один инструмент в арсенале реверс-инжиниринга реальности. Лучший хак — это осознание того, как всё работает, и готовность признать, что даже самые изящные патчи — лишь временные меры.
Оригинал статьи: https://arxiv.org/pdf/2601.09555.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.