Статьи QuantRise
Учебники под прицелом: Автоматический поиск вопросов и ответов с изображениями
Автор: Денис Аветисян
Новая система позволяет извлекать из образовательных материалов ценные данные для обучения искусственного интеллекта, способного понимать визуальную информацию.
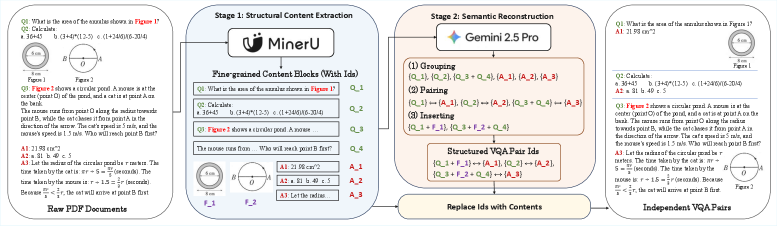
Представлена система FlipVQA-Miner для автоматизированного извлечения пар «вопрос-ответ» с изображениями из учебников и других образовательных документов, предназначенная для создания обучающих данных для больших языковых моделей.
Несмотря на стремительное развитие больших языковых моделей (LLM), получение качественных обучающих данных остается сложной задачей. В данной работе, представленной под названием ‘FlipVQA-Miner: Cross-Page Visual Question-Answer Mining from Textbooks’, предложен автоматизированный конвейер для извлечения пар «вопрос-ответ» и «визуальный вопрос-ответ» из учебных материалов. Разработанный метод позволяет эффективно преобразовывать неструктурированные данные из учебников в высококачественные наборы данных для обучения LLM, обеспечивая высокую точность и семантическую согласованность. Сможет ли предложенный подход стать основой для создания более эффективных и надежных систем искусственного интеллекта, способных к сложному рассуждению и пониманию?
Раскрытие Потенциала Знаний: Вызовы Структурированных Данных
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие способности в обработке и генерации текста, однако их возможности в решении задач, требующих доступа к структурированным знаниям и сложного логического вывода, остаются ограниченными. Несмотря на способность БЯМ распознавать закономерности в тексте и генерировать связные ответы, они часто испытывают трудности при работе с данными, представленными в табличной форме или графах знаний. В отличие от людей, способных легко интегрировать информацию из различных источников и применять логические правила, БЯМ полагаются преимущественно на статистические связи, обнаруженные в обучающих данных. Это приводит к тому, что даже при наличии релевантной информации, модели могут допускать ошибки в рассуждениях или выдавать неточные ответы, особенно в задачах, требующих глубокого понимания предметной области и умения делать выводы на основе структурированных данных.
Традиционные методы извлечения информации из документов, такие как базовое оптическое распознавание символов (OCR), часто оказываются недостаточными для глубокого понимания и ответов на сложные вопросы. В то время как OCR успешно преобразует изображения текста в машиночитаемый формат, он не способен уловить нюансы смысла, контекст или отношения между различными элементами информации. Простое распознавание символов не позволяет выявить, например, причинно-следственные связи, иерархические структуры или семантические роли слов в предложении. В результате, системы, полагающиеся исключительно на базовый OCR, сталкиваются с трудностями при анализе сложных документов, требующих не только распознавания текста, но и его интерпретации в контексте предметной области. Это особенно критично для задач, связанных с юридическими документами, научными статьями или техническими отчетами, где точность и полнота понимания имеют первостепенное значение.
Ограниченность надежных методов использования структурированных данных существенно снижает способность больших языковых моделей (LLM) предоставлять точные и контекстуально релевантные ответы. Несмотря на впечатляющие возможности в обработке текста, LLM часто сталкиваются с трудностями при решении задач, требующих доступа к формализованным знаниям, таким как базы данных или онтологии. Отсутствие эффективных инструментов для интеграции и анализа этих данных приводит к тому, что ответы моделей могут быть неполными, неточными или даже ошибочными, особенно в областях, где важна высокая степень достоверности информации. В результате, потенциал LLM для решения сложных задач, требующих логического вывода и анализа структурированных знаний, остается нереализованным, что подчеркивает необходимость разработки новых подходов к интеграции структурированных и неструктурированных данных.
Автоматизированное Извлечение Знаний: Система FlipVQA-Miner
FlipVQA-Miner представляет собой конвейер, предназначенный для автоматизированного извлечения пар «Вопрос-Ответ» (QA) и «Визуальный вопрос-Ответ» (VQA) из учебников и других образовательных материалов. Система обрабатывает исходные документы, полученные посредством оптического распознавания символов (OCR), и использует MinerU 2.5 для структурного извлечения контента. Далее, для улучшения понимания структуры документов применяется модель LayoutLMv3. Конечная цель конвейера — создание структурированного набора данных, пригодного для обучения и оценки больших языковых моделей (LLM), используя как текстовую, так и визуальную информацию, содержащуюся в исходных материалах.
Система FlipVQA-Miner использует MinerU 2.5 для извлечения структурного содержимого из документов, начиная с необработанного текста, полученного посредством оптического распознавания символов (OCR). MinerU 2.5 позволяет идентифицировать и сегментировать различные элементы документа, такие как заголовки, абзацы, списки и изображения. Для улучшения понимания структуры и семантики документа применяется модель LayoutLMv3, которая учитывает как текстовое содержание, так и визуальную компоновку элементов. LayoutLMv3 позволяет эффективно обрабатывать сложные макеты документов, включая многоколоночные тексты и документы с перекрывающимися элементами, что критически важно для точного извлечения пар вопрос-ответ и визуальных вопросов-ответов.
Успешная работа системы FlipVQA-Miner напрямую зависит от использования моделей, объединяющих обработку изображений и текста (Vision Language Models). Эти модели позволяют системе одновременно анализировать как текстовое содержание учебных материалов, полученное посредством OCR, так и визуальную информацию, представленную на изображениях. Такой подход необходим для корректного извлечения пар «вопрос-ответ» и «визуальный вопрос-ответ», поскольку ответы часто требуют понимания контекста, представленного как в тексте, так и на изображениях. Интеграция визуальной и текстовой информации значительно повышает точность и полноту извлеченных данных, обеспечивая создание качественного набора обучающих данных для LLM.
Система FlipVQA-Miner демонстрирует высокую точность извлечения пар вопрос-ответ (QA) и визуальных вопросов-ответов (VQA) из учебных материалов. Оценка F1 для извлечения текста (Text Extraction F1) превышает 0.98 для всех протестированных документов, включая документы со сложной структурой: чередующиеся текстовые блоки, длинные дистанции между вопросом и ответом, а также многоколоночный формат. Данный показатель подтверждает надежность системы в автоматическом формировании обучающих данных для моделей машинного обучения.
В процессе работы системы FlipVQA-Miner достигнута абсолютная точность определения местоположения изображений (Image Placement Precision = 1.0) во всех протестированных документах, независимо от их структуры и языка. При этом, значения F1-меры для определения местоположения изображений (Image Placement F1) варьируются от 0.9615 до 0.9886, что свидетельствует о высокой эффективности системы в корректном сопоставлении изображений и соответствующего текстового контекста, даже в документах со сложной структурой, например, с многоколоночным текстом или чередующимся текстом и изображениями.
Извлеченные данные из FlipVQA-Miner представляют собой ценный источник инструктивных данных для обучения и оценки больших языковых моделей (LLM). Этот набор данных включает в себя пары вопрос-ответ (QA) и визуальный вопрос-ответ (VQA), полученные из учебных материалов, что позволяет создавать разнообразные сценарии обучения, охватывающие как текстовую, так и визуальную информацию. Такая структура данных позволяет LLM улучшать свои способности к пониманию контекста, логическому мышлению и генерации ответов на сложные вопросы, требующие интеграции визуального и текстового контента. Использование данных, полученных из образовательных источников, обеспечивает высокую степень релевантности и точности, что критически важно для эффективного обучения и надежной оценки производительности LLM.

Повышение Надежности LLM: Стабильность и Обоснованность
Обучение с учителем (Supervised Fine-Tuning) на извлеченных данных демонстрирует существенное повышение производительности больших языковых моделей (LLM) в задачах ответов на вопросы. Этот процесс включает в себя использование размеченных данных, состоящих из вопросов и соответствующих ответов, для корректировки весов модели. В результате, LLM улучшает способность точно понимать вопросы и генерировать релевантные и корректные ответы. Экспериментальные данные показывают, что точность ответов повышается на после применения данной методики, по сравнению с исходной моделью, не подвергавшейся обучению с учителем на специфическом наборе данных.
Для решения проблем галлюцинаций и фактических неточностей в ответах языковых моделей, используется обучение с подкреплением на основе обратной связи от людей. В процессе обучения, люди оценивают ответы модели, предоставляя информацию о их корректности и релевантности. Эти оценки используются для формирования сигнала вознаграждения, который оптимизирует модель, направляя её к генерации более точных и правдивых ответов. Обучение с подкреплением позволяет модели не только улучшить качество генерируемого текста, но и адаптироваться к предпочтениям и ожиданиям пользователей, повышая общую надежность и полезность системы.
Процесс обучения с подкреплением акцентируется на двух ключевых аспектах: фактической обоснованности (Factual Grounding) и стабильности рассуждений (Reasoning Stability). Фактическая обоснованность подразумевает, что генерируемые ответы должны основываться на проверенных источниках и избегать выдумывания информации. Стабильность рассуждений обеспечивает логическую последовательность и непротиворечивость в ответах, даже при незначительных изменениях входных данных или формулировок вопросов. Совместная оптимизация этих двух параметров позволяет значительно повысить точность и надежность ответов, генерируемых большой языковой моделью (LLM), минимизируя вероятность галлюцинаций и неточностей.
Комбинирование высококачественных данных и целевого обучения с подкреплением позволяет добиться существенного повышения производительности больших языковых моделей (LLM). Использование тщательно отобранных и размеченных данных в качестве основы для обучения, в сочетании с алгоритмами обучения с подкреплением, ориентированными на конкретные метрики, такие как точность и согласованность ответов, приводит к улучшению показателей в задачах, требующих генерации текста, ответа на вопросы и выполнения инструкций. Наблюдается статистически значимое увеличение точности и снижение частоты галлюцинаций, что подтверждается количественными измерениями, такими как -мера и BLEU score, в сравнении с моделями, обученными только на больших объемах неструктурированных данных.
К Надежному Искусственному Интеллекту: Последствия и Будущие Направления
Исследование демонстрирует значительный потенциал синергии между автоматической генерацией данных и целенаправленным обучением с подкреплением для повышения возможностей больших языковых моделей. В рамках данной методологии, алгоритмы автоматически создают разнообразные и структурированные наборы данных, специально разработанные для тренировки модели в областях, где требуется улучшение. Затем, обучение с подкреплением позволяет модели активно учиться на этих данных, оптимизируя свои ответы и стратегии для достижения конкретных целей. Такой подход позволяет не только повысить точность и надежность языковых моделей, но и существенно расширить их функциональность, позволяя им решать более сложные и специализированные задачи, требующие глубокого понимания и адаптации к различным контекстам. Полученные результаты указывают на перспективность данного направления для создания более интеллектуальных и эффективных систем искусственного интеллекта.
Возможность эффективного использования структурированных знаний открывает принципиально новые горизонты для больших языковых моделей (LLM) в таких областях, как образование и научные исследования. Вместо простой обработки неструктурированного текста, LLM получают доступ к организованным базам данных, онтологиям и графам знаний, что позволяет им не только отвечать на вопросы, но и выводить новые знания, устанавливать связи между различными концепциями и даже генерировать гипотезы. В образовании это может привести к созданию персонализированных систем обучения, адаптирующихся к индивидуальным потребностям каждого ученика. В научных исследованиях — к автоматизации процесса анализа больших объемов данных и ускорению открытия новых закономерностей. Интеграция структурированных знаний позволяет LLM перестать быть просто «попугаями», повторяющими информацию, и стать настоящими интеллектуальными помощниками, способными к глубокому пониманию и творческому решению задач.
Дальнейшие исследования направлены на расширение масштабов разработанного конвейера обработки данных, с целью применения к более крупным наборам информации. Это позволит оценить устойчивость и обобщающую способность предложенного подхода в условиях значительного увеличения сложности задач. Параллельно планируется изучение и внедрение более совершенных методов обучения с подкреплением, включая алгоритмы, способные к более эффективному исследованию пространства решений и адаптации к меняющимся условиям. Особое внимание будет уделено техникам, позволяющим оптимизировать процесс обучения и повысить стабильность результатов, что критически важно для создания надежных и эффективных систем искусственного интеллекта.
Данное исследование вносит значительный вклад в создание искусственного интеллекта, отличающегося повышенной устойчивостью, надежностью и доверием к результатам. Разработка направлена на преодоление существующих ограничений, связанных с хрупкостью и непредсказуемостью больших языковых моделей. Достигнутые улучшения в способности к обучению и адаптации позволяют создавать системы, способные более точно и последовательно выполнять поставленные задачи, даже в условиях неопределенности или неполноты данных. В конечном итоге, это способствует формированию более безопасных и полезных AI-систем, пригодных для широкого спектра приложений, где важна не только эффективность, но и предсказуемость поведения.
Исследование, представленное в данной работе, демонстрирует стремление к созданию целостной системы извлечения знаний из учебных материалов. Автоматизированный конвейер FlipVQA-Miner, извлекающий пары вопрос-ответ из визуального контента, подчеркивает важность понимания структуры документа для эффективного обучения больших языковых моделей. Этот подход соответствует убеждению, что хорошая система — живой организм, где каждая часть взаимосвязана. Как заметил Блез Паскаль: «Все великие дела требуют времени». В данном случае, время, потраченное на разработку такого инструмента, как FlipVQA-Miner, потенциально способно значительно ускорить прогресс в области обучения моделей пониманию визуальной информации, предоставляя надежный источник данных для обучения. Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений.
Что Дальше?
Представленный подход к автоматизированному извлечению пар «вопрос-ответ» из учебных материалов, безусловно, является шагом вперёд. Однако, стоит помнить, что любая система, даже элегантная, неизбежно имеет границы применимости. Автоматизация, освобождая ресурсы, лишь подчёркивает важность качественной верификации извлечённых данных. Ведь неисправности всегда возникают на границах ответственности — если их не видно, вскоре станет больно. Поэтому, основная задача будущего — не только увеличение объёма извлекаемых данных, но и разработка надежных механизмов контроля их достоверности.
Очевидным направлением развития является расширение области применения. Если текущая работа фокусируется на учебных материалах, то потенциал автоматического извлечения знаний охватывает гораздо более широкий спектр документов — от технических руководств до научных статей. Однако, следует учитывать, что структура и сложность этих документов различны, что требует адаптации существующих алгоритмов и разработки новых подходов. Необходимо понимать, что поведение системы определяется её структурой; попытки «починить» лишь отдельные элементы без учёта целого обречены на неудачу.
В конечном итоге, успех подобных систем будет определяться не только техническими инновациями, но и философским подходом к пониманию знаний. Необходимо помнить, что знание — это не просто набор фактов, а сложная система взаимосвязанных понятий. Поэтому, будущее развитие исследований должно быть направлено на создание систем, способных не только извлекать знания, но и понимать их смысл, а также выявлять скрытые связи и закономерности.
Оригинал статьи: https://arxiv.org/pdf/2511.16216.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.