Статьи QuantRise
Умная генерация текста: как сократить расходы на большие языковые модели
Автор: Денис Аветисян
Новый подход к динамическому выбору шаблонов позволяет снизить стоимость работы с большими языковыми моделями, не жертвуя качеством генерируемого текста.
В статье рассматривается метод динамического выбора шаблонов (DTS) на основе MLP и Transformer для оптимизации стоимости токенов при генерации текста большими языковыми моделями.
Современные большие языковые модели часто используют единые шаблоны ответов для запросов различной сложности, что приводит к неэффективному использованию токенов и высоким затратам на API. В работе ‘Dynamic Template Selection for Output Token Generation Optimization: MLP-Based and Transformer Approaches’ предложен метод динамического выбора шаблонов ответов (DTS), адаптирующий их к сложности запроса и значительно снижающий количество генерируемых токенов без потери качества. Эксперименты с использованием MLP и RoBERTa показали, что предложенный подход обеспечивает существенное сокращение затрат, а принятые решения по маршрутизации эффективно обобщаются на различных провайдеров LLM. Возможно ли дальнейшее повышение эффективности и адаптивности подобных систем за счет интеграции более сложных моделей и учета специфики различных предметных областей?
Эхо масштаба и цена возможностей
Современные большие языковые модели, такие как GPT-4 от OpenAI, демонстрируют впечатляющие возможности в обработке и генерации текста, однако их применение сопряжено с существенными вычислительными трудностями и ограничениями по количеству токенов. Сложные задачи, требующие развернутых и детализированных ответов, приводят к экспоненциальному росту потребляемых ресурсов и, как следствие, к увеличению стоимости использования. Это связано с тем, что обработка каждого токена требует значительных вычислительных мощностей, а длительные последовательности токенов значительно усложняют и замедляют работу модели. В результате, несмотря на потенциал LLM, их практическое применение в ресурсоограниченных средах или для задач, требующих высокой скорости обработки, остается серьезной проблемой, требующей поиска эффективных решений по оптимизации и снижению вычислительной нагрузки.
Непрерывное увеличение размеров языковых моделей, хотя и демонстрирует впечатляющие результаты, сталкивается с растущими ограничениями в плане устойчивости. Повышение вычислительной сложности и энергопотребления делает дальнейшую гонку за параметрами все более дорогостоящей и непрактичной. В связи с этим, ключевым направлением исследований становится не просто увеличение масштаба, а оптимизация существующих моделей и разработка новых подходов, позволяющих достигать высокой производительности при меньших затратах ресурсов. Это требует инновационных стратегий в области архитектуры моделей, методов обучения и алгоритмов сжатия, направленных на повышение эффективности использования вычислительных мощностей и снижение потребления энергии, не жертвуя при этом качеством генерируемого текста.
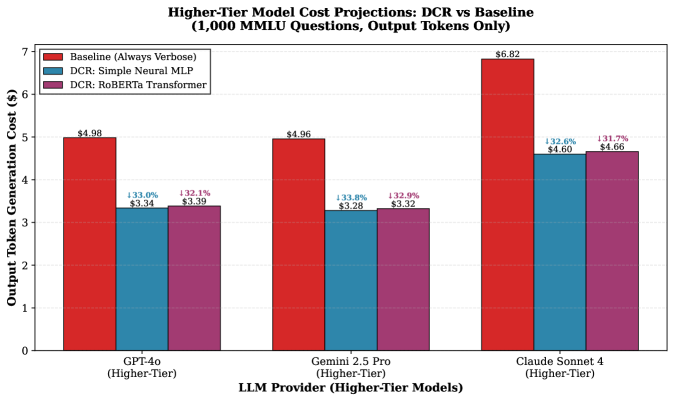
Основная проблема при использовании больших языковых моделей заключается в том, что развернутые, детализированные ответы значительно увеличивают стоимость обработки выходных токенов, что препятствует их практическому внедрению. Разработанная система динамического выбора шаблонов (DTS) направлена на решение этой задачи, эффективно снижая потребление токенов в среднем на 33.2% при использовании основных поставщиков облачных сервисов. Это достигается за счет интеллектуального выбора наиболее лаконичного шаблона ответа, сохраняя при этом полноту и точность предоставляемой информации. Таким образом, DTS позволяет снизить финансовую нагрузку и расширить возможности масштабирования приложений, использующих большие языковые модели.
Динамический выбор шаблонов: стратегия оптимизации издержек
Динамический выбор шаблонов (DTS) представляет собой метод маршрутизации запросов к различным предопределенным шаблонам ответов. Эта система позволяет адаптировать детализацию ответа в зависимости от сложности запроса, используя, например, «Минимальный шаблон» для лаконичных ответов или «Подробный шаблон» для развернутых объяснений. Такой подход позволяет избежать избыточной генерации текста, оптимизируя затраты на обработку и передачу данных, и повышая эффективность взаимодействия с моделью.
Для классификации входящих запросов и выбора наиболее подходящего шаблона ответа, в зависимости от их сложности, система динамического выбора шаблонов (DTS) использует один из двух маршрутизаторов: многослойный персептрон (MLP Router) или RoBERTa Router. MLP Router классифицирует запросы на основе признаков, полученных из входных данных, в то время как RoBERTa Router использует модель трансформера для более глубокого семантического анализа. Оба маршрутизатора предназначены для определения необходимого уровня детализации ответа и, соответственно, выбора шаблона — от минимального, предоставляющего краткий ответ, до подробного, содержащего развернутое объяснение.
Динамический выбор шаблонов (DTS) позволяет снизить затраты на генерацию ответов за счет оптимизации количества выходных токенов. Система классифицирует входящие запросы с помощью MLP Router или RoBERTa Router и направляет их к наиболее подходящему шаблону ответа — от минимального, для кратких ответов, до подробного, для развернутых объяснений. В ходе тестирования на 1000 вопросов MMLU, MLP Router продемонстрировал точность маршрутизации 90.5%, а RoBERTa Router — 89.5%, что подтверждает эффективность подхода в адаптации детализации ответа к сложности запроса и, как следствие, сокращении расходов.
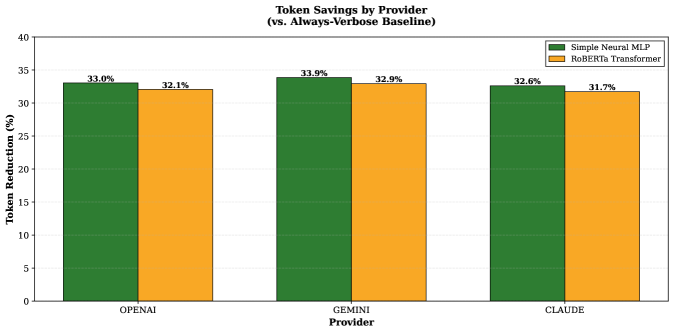
В ходе тестирования на моделях OpenAI GPT-4, Google Gemini 2.5 Pro и Anthropic Claude Sonnet, использование динамического выбора шаблонов (DTS) позволило снизить количество генерируемых выходных токенов на 33.0%, 33.9% и 32.6% соответственно. Данное сокращение обусловлено применением различных, заранее определенных шаблонов ответов в зависимости от сложности запроса, что позволяет избежать избыточной детализации и, как следствие, снизить затраты на использование языковых моделей.

Подтверждение эффективности: результаты валидации и бенчмаркинга
Для оценки DTS использовался стандартный набор данных MMLU Benchmark, предназначенный для оценки многозадачного понимания языка. Результаты показали, что DTS демонстрирует сопоставимую производительность с полноразмерными языковыми моделями (LLM), при этом требуя значительно меньше вычислительных ресурсов и затрат. Это подтверждается сравнительным анализом метрик точности и скорости обработки данных, указывающим на эффективность DTS в задачах, требующих комплексного анализа и генерации текста.
Оба маршрутизатора, RoBERTa Router и MLP Router, демонстрируют высокую точность при выборе шаблонов, что подтверждается снижением количества токенов () без ухудшения качества ответов. Эффективность выбора шаблона оценивалась на основе способности системы предоставлять релевантные ответы при минимальном использовании вычислительных ресурсов, измеряемых количеством токенов, необходимых для генерации ответа. Полученные результаты указывают на то, что оба маршрутизатора эффективно идентифицируют наиболее подходящий шаблон для каждого запроса, оптимизируя процесс обработки и снижая затраты на вычисления, сохраняя при этом высокий уровень качества генерируемых ответов.
Модель обеспечивает надежное векторное представление текста, которое используется обеими маршрутизаторами — ‘RoBERTa Router’ и ‘MLP Router’ — для анализа намерения пользователя и сложности запроса. Данное представление позволяет эффективно сопоставлять входящие запросы с наиболее подходящими шаблонами, обеспечивая высокую точность выбора и, как следствие, качество генерируемых ответов. Надежность векторного представления является ключевым фактором, обеспечивающим работоспособность и эффективность обеих систем маршрутизации.

Теоретические основы и горизонты развития
Успех метода DTS находит объяснение в принципах “информационного узкого места”, согласно которым эффективное обучение требует не просто запоминания данных, а их селективной компрессии. Этот подход предполагает, что для достижения оптимальной обобщающей способности и повышения эффективности, модель должна фокусироваться на наиболее релевантной информации, отбрасывая несущественные детали. В процессе обучения, DTS, подобно принципу “информационного узкого места”, стремится к созданию компактного представления входных данных, сохраняя при этом наиболее важные признаки, необходимые для решения поставленной задачи. Такая компрессия позволяет модели лучше адаптироваться к новым, ранее не встречавшимся данным, избегая переобучения и улучшая свою производительность в различных сценариях, что подтверждает теоретическую обоснованность данного подхода и открывает перспективы для дальнейших исследований в области эффективного машинного обучения.
Исследования демонстрируют, что подход, основанный на сокращении избыточной информации, напрямую соответствует концепции «границы обобщения» в машинном обучении. Уменьшение количества ненужных деталей в данных позволяет избежать переобучения модели — ситуации, когда алгоритм слишком хорошо запоминает тренировочный набор, но плохо справляется с новыми, ранее невиданными данными. В результате, происходит улучшение способности модели к обобщению — то есть, к успешной работе с разнообразными входными данными, не включенными в тренировочный набор. Этот эффект особенно важен при работе с большими языковыми моделями, где переобучение может привести к генерации бессмысленных или нерелевантных ответов, а сокращение избыточности, напротив, повышает надежность и точность результатов.
Данная технология, обозначенная как DTS, демонстрирует значительную универсальность, успешно функционируя с различными крупными языковыми моделями (LLM), включая ‘Google Gemini 2.5 Pro’ и ‘Anthropic Claude Sonnet’. Этот факт указывает на то, что принципы, лежащие в основе DTS, не зависят от конкретной архитектуры или реализации LLM, что значительно расширяет сферу ее потенциального применения. Способность к адаптации к различным провайдерам и моделям позволяет предположить, что DTS может быть интегрирована в широкий спектр существующих систем и платформ, обеспечивая повышение эффективности и улучшение качества обработки естественного языка вне зависимости от используемого базового LLM.
Представленное исследование демонстрирует, что системы не следует проектировать как монолитные конструкции, а скорее, как адаптивные экосистемы. Подход динамического выбора шаблонов (DTS), описанный в статье, иллюстрирует эту концепцию, позволяя системе интеллектуально направлять запросы к шаблонам ответов различной степени детализации. Это не просто оптимизация затрат на API, но и признание того, что любая архитектурная схема содержит в себе предсказание будущих отказов. Как говорил Джон фон Нейман: «В науке нет абсолютной истины, только приближения». DTS — это не поиск идеального решения, а создание системы, способной к саморегуляции и минимизации издержек в условиях непредсказуемости, где место для людей остается за пределами автоматизированных процессов.
Что Дальше?
Представленный подход к динамическому выбору шаблонов, несомненно, демонстрирует возможность оптимизации затрат на взаимодействие с большими языковыми моделями. Однако, следует помнить: каждая сэкономленная единица — это отсроченное столкновение со сложностью. Система, стремящаяся к минимальному числу токенов, лишь откладывает неизбежное — необходимость обработки всего спектра входных данных. Попытки искусственно ограничить выразительность модели — это не решение, а временное умиротворение.
Будущие исследования, вероятно, столкнутся с необходимостью преодоления хрупкости классификаторов, определяющих выбор шаблона. Идеальная классификация — иллюзия; в каждом кроне скрыт страх перед хаосом. Более того, сама концепция «оптимального» шаблона — относительна. Что кажется экономичным сегодня, может оказаться неповоротливым и неадекватным уже через три релиза. Надежда на идеальную архитектуру — это форма отрицания энтропии.
Настоящая проблема заключается не в сокращении числа токенов, а в понимании того, как сделать языковые модели более устойчивыми к неопределенности. Вместо того, чтобы стремиться к «идеальному» ответу, следует разрабатывать системы, способные адаптироваться к неполным или противоречивым данным. Ведь в конечном счете, именно адаптивность, а не экономия, определяет долгосрочную жизнеспособность любой системы.
Оригинал статьи: https://arxiv.org/pdf/2511.20683.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.