Статьи QuantRise
Арена Исследовательских Агентов: Автоматическая Оценка Интеллекта
Автор: Денис Аветисян
Новая платформа DR-Arena позволяет объективно оценивать возможности самообучающихся агентов в решении сложных исследовательских задач.
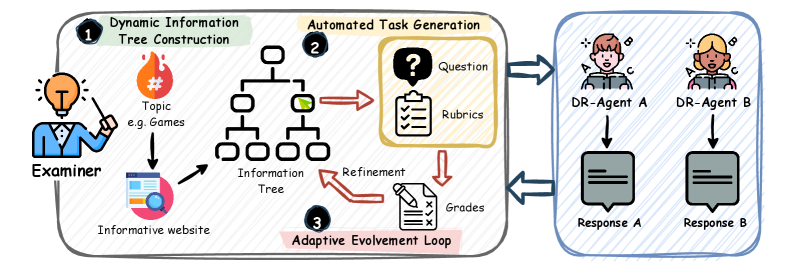
Представлена полностью автоматизированная среда для оценки Deep Research Agents, использующая динамические задачи, адаптивное усложнение и LLM в качестве эксперта.
В условиях стремительного развития агентов глубоких исследований, основанных на больших языковых моделях, надежная автоматизированная оценка их возможностей становится критически важной задачей. В данной работе представлена платформа DR-Arena: an Automated Evaluation Framework for Deep Research Agents, предназначенная для динамической оценки таких агентов посредством симуляции конкурентной среды с адаптивным уровнем сложности. Ключевым результатом является создание автоматизированной системы, коррелирующей с оценками экспертов с коэффициентом Спирмена 0.94, что обеспечивает надежную альтернативу дорогостоящей ручной оценке. Способна ли DR-Arena стать стандартом для оценки и дальнейшего развития автономных агентов, способных к глубоким исследованиям и синтезу информации?
Вызовы Автономных Исследований: Эпоха Систем
Современные методы научного исследования всё чаще сталкиваются с проблемой масштаба и скорости обработки информации. Традиционные подходы, требующие значительных временных и финансовых затрат, оказываются неспособны эффективно справляться с экспоненциальным ростом объема доступных данных. Ученым приходится тратить всё больше времени не на саму научную работу, а на поиск, фильтрацию и анализ релевантных источников. Это замедляет процесс открытия новых знаний и препятствует оперативному решению актуальных задач. В результате, традиционные методы оказываются узким местом в современной науке, требующим разработки принципиально новых подходов к организации и проведению исследований.
Перспектива создания “Глубоких Исследовательских Агентов” — автономных систем, способных к проведению углубленных исследований — пока не реализована в полной мере, что связано, прежде всего, с проблемами оценки их эффективности. Недостаточно просто создать систему, способную генерировать гипотезы и собирать информацию; необходимо разработать надежные и объективные метрики, позволяющие судить о качестве проведенного исследования, новизне полученных результатов и их значимости для соответствующей области знаний. Существующие методы оценки, как правило, требуют значительных временных и ресурсных затрат, а также субъективны, что затрудняет сравнение различных агентов и определение лучших практик. Таким образом, преодоление этих “узких мест” в оценке является ключевым шагом на пути к созданию действительно автономных и полезных исследовательских систем.
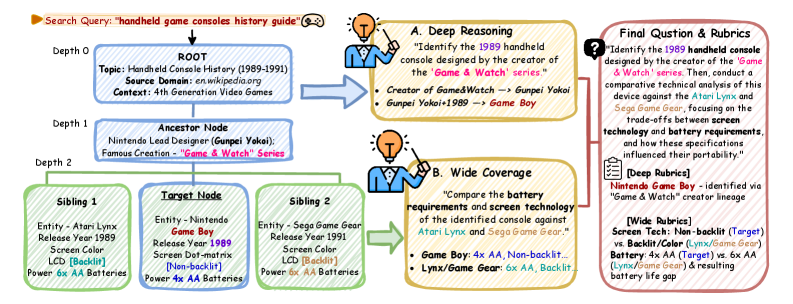
DR-Arena: Арена для Исследовательских Систем
DR-Arena представляет собой автоматизированную платформу для оценки агентов, предназначенных для проведения исследований (DR-агентов), посредством соревновательных задач. Система позволяет проводить сравнительный анализ различных DR-агентов, моделируя условия, в которых они решают исследовательские вопросы. Платформа автоматизирует процесс создания и проведения соревнований, обеспечивая воспроизводимость и объективность оценки. Результаты соревнований в DR-Arena позволяют определить наиболее эффективные стратегии и алгоритмы для проведения исследований, а также выявить сильные и слабые стороны различных DR-агентов.
DR-Arena использует динамические деревья информации (Dynamic Information Trees), формируемые на основе данных, получаемых в режиме реального времени из открытых веб-источников (Live Web Data). Эти деревья представляют собой структурированное представление информации, позволяющее автоматически генерировать разнообразные исследовательские задачи. Каждый узел дерева содержит фрагменты информации, а связи между узлами отражают логические отношения и зависимости. Постоянное обновление данных из веба обеспечивает эволюцию деревьев и, следовательно, динамичное изменение задач, что позволяет оценить способность DR-агентов адаптироваться к новой информации и решать постоянно меняющиеся исследовательские вопросы.
Система DR-Arena использует автоматическую генерацию задач, варьируя их сложность по двум ключевым параметрам: “глубина” (depth), отражающая необходимый уровень логических рассуждений для решения, и “ширина” (width), определяющая объем информации, которую необходимо собрать и обработать. Изменение этих параметров позволяет создавать разнообразные исследовательские задачи, требующие от агентов различной степени аналитических способностей и навыков сбора данных. Комбинация глубины и ширины позволяет контролировать общую сложность задачи и, таким образом, эффективно оценивать возможности различных DR-агентов в решении сложных исследовательских проблем.
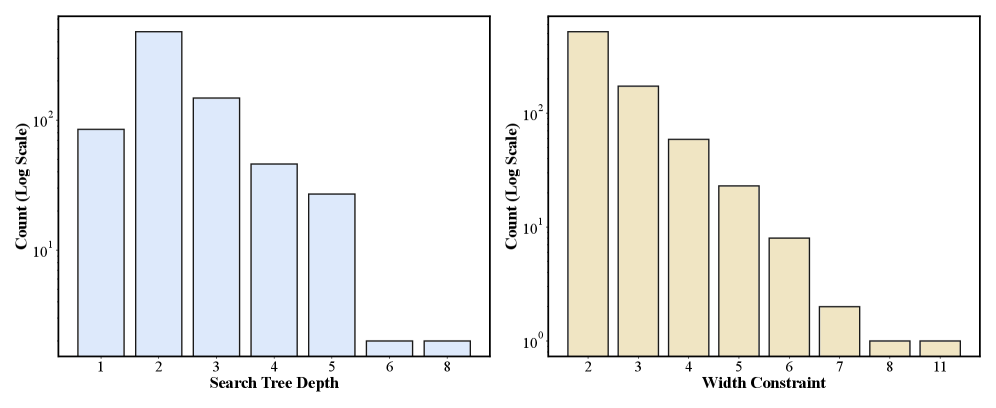
Адаптивная Оценка и Измерение Эффективности: Эволюция в Действии
В DR-Arena реализован “Адаптивный цикл эволюции” (Adaptive Evolvement Loop), который динамически изменяет сложность задач в процессе оценки. Алгоритм отслеживает производительность агентов и автоматически корректирует уровень сложности последующих задач, обеспечивая постоянную нагрузку, соответствующую текущим возможностям. Это достигается путем анализа ответов агентов и применения правил, определяющих повышение или понижение сложности. Такой подход гарантирует, что оценка остается информативной и релевантной на протяжении всего процесса, позволяя точно определить сильные и слабые стороны исследуемых моделей и избежать как слишком простых, так и чрезмерно сложных задач.
Оценка производительности агентов в DR-Arena осуществляется с использованием системы Эло (Elo Rating System), изначально разработанной для шахмат. Система Эло позволяет формировать динамический рейтинг, учитывающий относительную силу агентов на основе результатов их взаимодействия друг с другом. Каждый агент получает числовой рейтинг, который обновляется после каждой «игры» (выполнения задачи) с учетом разницы в рейтингах соперников и фактического результата. Более высокий рейтинг указывает на более высокую способность агента успешно выполнять исследовательские задачи, а динамическое обновление рейтинга обеспечивает точную и нюансированную ранжировку исследовательских возможностей агентов на протяжении всего процесса оценки.
Для обеспечения достоверности оценок, DR-Arena использует комплексную систему валидации ответов агентов, включающую в себя автоматизированную оценку на основе больших языковых моделей (LLM-as-a-Judge) и процедуру проверки фактической точности (Factuality Audit). LLM-as-a-Judge оценивает соответствие ответов заданным критериям и логическую связность, в то время как Factuality Audit проводит сверку предоставленной информации с авторитетными источниками для выявления и устранения потенциальных неточностей или дезинформации. Данный подход позволяет минимизировать влияние предвзятости и обеспечить объективную оценку производительности агентов в различных задачах.
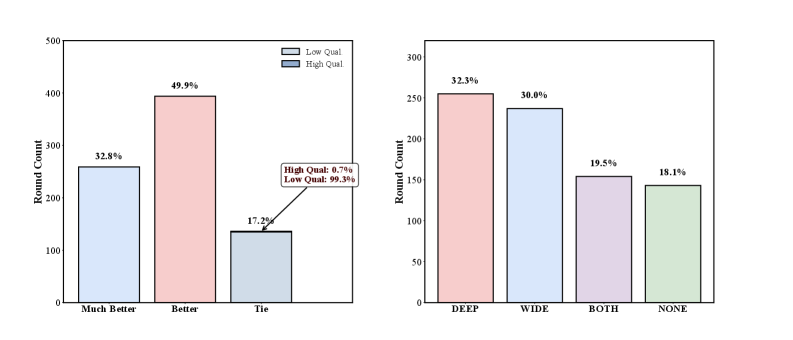
Соответствие Человеческим Предпочтениям и Перспективы Развития: Выращивание Систем
Система DR-Arena демонстрирует высокую степень соответствия человеческим предпочтениям, что подтверждается сравнением с результатами, полученными при оценке людьми. Анализ показывает, что ранжирование моделей, выполненное DR-Arena, тесно коррелирует с тем, как эти же модели оценивались непосредственно людьми-экспертами. Такое соответствие не просто статистически значимо, но и позволяет утверждать о надежности и валидности автоматизированной оценки, предлагаемой данной системой, что открывает перспективы для более эффективной и быстрой оценки моделей искусственного интеллекта в будущем.
Результаты исследований демонстрируют высокую степень соответствия предпочтениям человека, оцениваемую с помощью коэффициента корреляции Спирмена, равного 0.94 по отношению к рейтингам LMSYS Search Arena. Данный показатель свидетельствует о значительном превосходстве разработанной системы в согласовании с человеческими оценками по сравнению с другими существующими эталонами. Высокая корреляция подтверждает, что автоматизированная оценка, предложенная в рамках работы, надежно отражает субъективные предпочтения пользователей, что является ключевым фактором для развития автономных исследований и создания интеллектуальных систем, способных эффективно взаимодействовать с человеком.
Анализ показал высокую степень соответствия результатов, полученных с помощью разработанной системы, и оценок, выставленных людьми. В частности, коэффициент корреляции Пирсона, составивший 0.74 по отношению к рейтингам LMSYS Search Arena, подтверждает надежность предложенного подхода. Более того, значение коэффициента Коэна Каппа, достигшее 0.91 при сравнении с экспертными оценками, указывает на исключительную согласованность и стабильность автоматизированной системы оценки, что свидетельствует о ее способности воспроизводить суждения людей с высокой точностью и последовательностью.
Предполагается, что DR-Arena станет катализатором для ускоренного развития автономных исследований, открывая новые горизонты в различных научных областях. Эта платформа предоставляет уникальную возможность для автоматизации исследовательских процессов, позволяя ученым сосредоточиться на формулировании гипотез и интерпретации результатов, вместо рутинной работы по сбору и анализу данных. Автономные агенты, обученные и протестированные в среде DR-Arena, способны самостоятельно проводить эксперименты, оценивать полученные результаты и предлагать новые направления для исследований, значительно ускоряя темпы научных открытий в таких сферах, как материаловедение, химия, биология и компьютерные науки. Ожидается, что подобный подход приведет к появлению инновационных решений и углублению понимания сложных научных проблем, ранее недоступных для традиционных методов исследования.
Рассматриваемая работа демонстрирует, что попытки создать абсолютно надежные системы оценки неизбежно обречены на провал. DR-Arena, представляя собой динамичную арену для состязания агентов, не стремится к статичной истине, а скорее признает, что оценка — это процесс адаптации к постоянно меняющимся условиям. Как однажды заметил Клод Шеннон: «Теория связи по своей сути является теорией вероятности». Подобно тому, как Шеннон видел в шуме неотъемлемую часть коммуникации, DR-Arena принимает неизбежность ошибок и несовершенства в оценке, делая акцент на выявлении устойчивости агентов к непредсказуемости и их способности к адаптации. Стабильность — это иллюзия, хорошо кэшируемая, а DR-Arena — это признание хаоса как языка природы.
Что Дальше?
Представленная работа, создавая автоматизированную арену для оценки агентов глубокого исследования, не решает проблему оценки, а лишь перемещает её. Теперь задача заключается не в измерении интеллекта агента, а в проектировании самой арены — динамичной, непредсказуемой и, главное, справедливой. Ибо каждое изменение в алгоритме адаптации сложности — это пророчество о будущем способе обхода системы.
Безусловно, автоматизация оценки — шаг вперёд, но она лишь обнажает более глубокую дилемму. Система, претендующая на объективность, неизбежно становится отражением предвзятости своих создателей. Вопрос не в том, насколько хорошо агент решает задачи, а в том, какие задачи ему позволяют решать. Ибо тишина системы — не признак успеха, а подготовка к неожиданностям.
Перспективы кажутся очевидными: переход от оценки способности к оценке эволюции. Агент, способный адаптироваться к непрерывно меняющимся правилам арены, ценнее того, кто идеально решает статичные задачи. Отладка никогда не закончится — мы просто перестанем смотреть, полагая, что нашли достаточно убедительную иллюзию интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2601.10504.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Статья также опубликована на личном сайте автора.